
刚刚,英伟达重新定义PC!史上最高效CPU构建AI个人工作站新体验
刚刚,英伟达重新定义PC!史上最高效CPU构建AI个人工作站新体验在上午 11 点开始的英伟达 GTC Taibei 2026 大会现场,黄仁勋拿出了英伟达与微软联手打造的 PC 产品。在细数了将近 1 个小时已有成果之后,黄仁勋终于开讲今天的重头戏:一款迄今为止全球性能最强、能效最高的轻薄型 Windows PC。
来自主题: AI资讯
9299 点击 2026-06-01 14:09
 搜索
搜索
在上午 11 点开始的英伟达 GTC Taibei 2026 大会现场,黄仁勋拿出了英伟达与微软联手打造的 PC 产品。在细数了将近 1 个小时已有成果之后,黄仁勋终于开讲今天的重头戏:一款迄今为止全球性能最强、能效最高的轻薄型 Windows PC。

2026年5月30日,半导体研究机构SemiAnalysis发布深度报告《AI Dark Output: The Visible Cost of Invisible Output》,提出了一个“暗产出”的概念,判断AI正在大规模创造真实经济价值,但这些价值在GDP、价格指数和就业统计中几乎无迹可寻,规模“可能不亚于工业革命”。

连续创业的 York 开启了又一段新征程。过去十几年里,他几乎一直在做软硬一体系统:从计算机视觉、嵌入式,到后来的机器人。他的上一个创业项目——智能购物车 Caper AI,在 2021 年被 Instacart 以 3.5 亿美元收购。
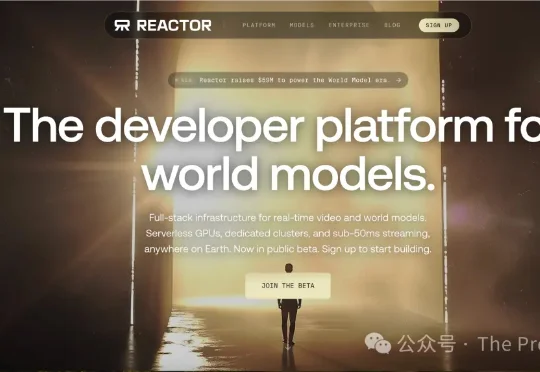
核心观点:由前Apple Vision Pro两位技术负责人联合创办的Reactor,近期完成5900万美元种子轮及A轮融资,由Lightspeed Venture Partners领投,WndrCo

从大模型的提示词到智能体的 Skills,看着进化了,但又没有完全进化。

MiniMax M3 今日正式发布。MiniMax M3 在编程和智能体等专业任务上达到了前沿的能力。它使用了我们提出的全新注意力架构 MSA (MiniMax Sparse Attention),最高支持 1M 超长上下文。如外界所期待的那样,它也是一个原生多模态模型,支持图片和视频的输入,并能操作电脑桌面。
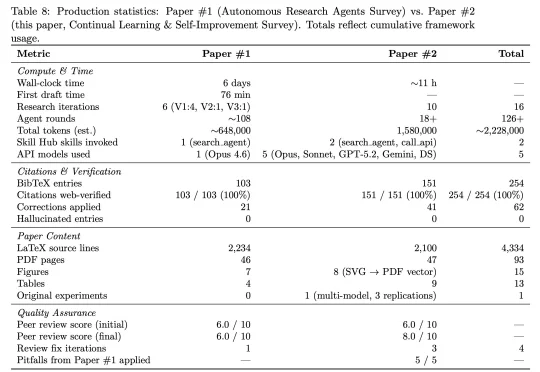
DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。
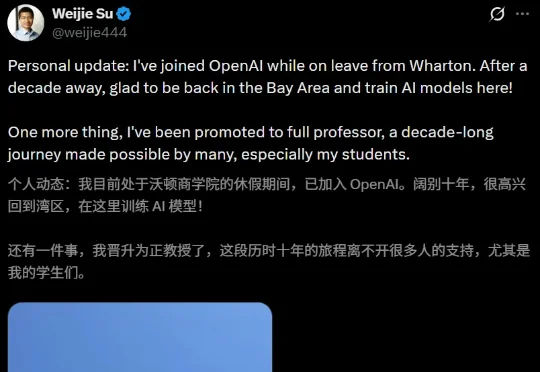
继清华姚班陈立杰之后,OpenAI又迎来一位重量级华人学者:北大数院「黄金二代」苏炜杰。今年,他刚刚摘下有「统计学诺奖」之称的COPSS Presidents' Award。

5 月下旬,NVIDIA 联合清华大学、多伦多大学和 Vector Institute 发布 Gamma-World,共一第一为清华大学电子系博士刘芳甫,核心 Research 方向是世界模型和空间智能。
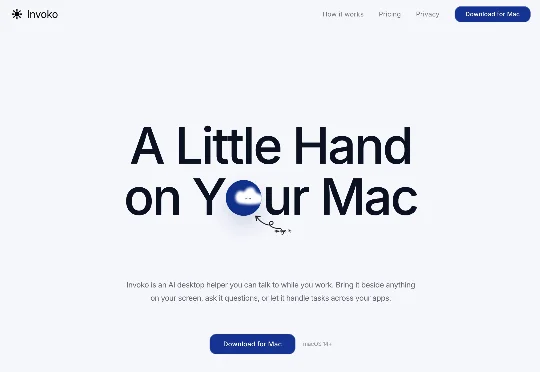
SophiaPro 成立于 2025 年 6 月。 最早,他们做的是一款叫 Karis.im 的 ToB 产品,给出海企业提供市场营销数字员工。后来转向 C 端产品,先是做了浏览器插件 TryClico,最近又推出了桌面端产品 Invoko.ai,一个长在 Mac 灵动岛位置的 notch 工具,帮用户在不同 app 之间自由切换上下文。