
Anthropic 创始人,到底在「百度」经历了什么?
Anthropic 创始人,到底在「百度」经历了什么?“Dario 见证的百度 AI 路线分歧。 ” 作者丨成妍菁 编辑丨胡敏 Anthropic 创始人 Dario 的职业开局有些戏剧化。 2014 年刚走出校园加入百度,就赶上中国互联网历史上第一场“
来自主题: AI资讯
8561 点击 2026-07-06 15:58
 搜索
搜索
“Dario 见证的百度 AI 路线分歧。 ” 作者丨成妍菁 编辑丨胡敏 Anthropic 创始人 Dario 的职业开局有些戏剧化。 2014 年刚走出校园加入百度,就赶上中国互联网历史上第一场“

谷歌DeepMind的一个高管,用死对头Anthropic的AI,把一个2003年的游戏硬塞进了iPhone。这个人叫Ammaar Reshi,是AI Studio的产品与设计负责人。跑的是真实引擎,ARM64原生编译,不是模拟器。
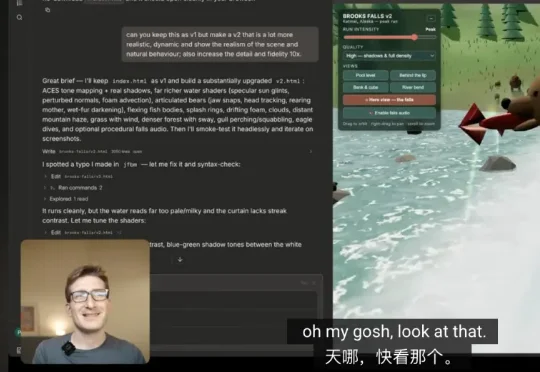
Fable 5重新上线,Arena.ai的Gostev在一段视频中甩出63个3D世界,几乎都是一次成型。看了视频,就连刚加盟Anthropic预训练团队的Karpathy,也直呼没想到。
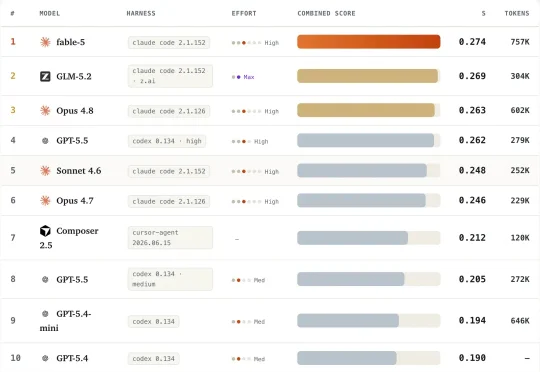
为了解决这一问题,来自 University of Arizona、Zoom 与 Stony Brook University 的研究团队推出了 VISTA(VIsual Spec-To-App Benchmark), 首个面向 Visual Spec-to-Web-App Coding Agents 的端到端 Benchmark。

UC Berkeley团队提出的端到端流程旨在解决该问题,研究团队跑通了首条能够从网络视频生成真实灵巧手实机执行轨迹的完整链路:先从真实场景中的单目RGB视频中重建4D手-物交互过程,再将这些交互轨迹重定向到拥有22个自由度的Sharpa Wave灵巧手上。

乐鑫喵伴 EchoEar EchoEar 喵伴 AI 机器人搭载的 ESP-Brookesia 框架实现全双工语音交互、多模态识别与智能体控制,构建更具沉浸感的人机交互体验。 EchoEar 套件以端

WIRED 上周曝光了一个消息:Meta 的几百名外国员工,假扮成 13 岁少女、小学生等,向 ChatGPT、Gemini、Character.AI 发送提示词。这个项目代号叫 Cannes,Meta 通过外包商 Covalen 执行,最近一次活跃是今年 4 月。
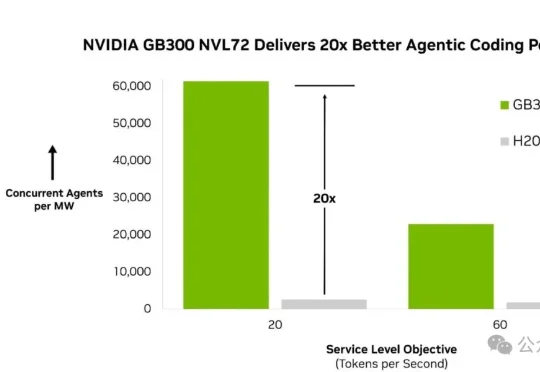
同样一兆瓦电,英伟达最新的GB300 NVL72能同时扛住61400个智能体,上一代H200只扛得住大约2600个。这中间,差了整整20倍。它就是独立评测机构Artificial Analysis发布的新基准:AA-AgentPerf。

5周内,他们如何做出了一个新的Agent产品,并完成了组织改造?那时,他们的公司火星电波成立了1年2个月,刚刚拿到新一笔200万美元融资。ListenHub——他们打造的一款AI驱动的音频内容生成工具,已经做到300万美元ARR,并实现了月度盈亏平衡。且,ListenHub仍在增长。按照原来的计划,他们会继续把它推向海外,到年底,营收或许还能再翻几倍。
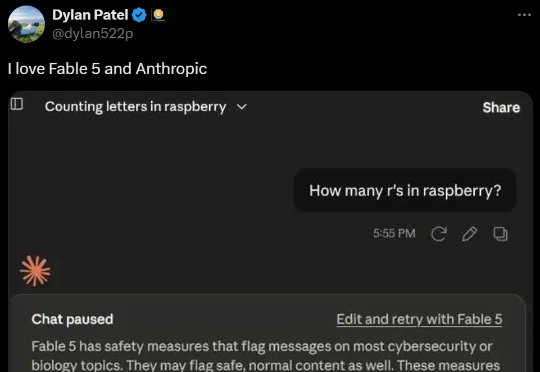
你敢信?仅仅是让Fable 5数一下,单词raspberry里到底有几个字母r,结果就被一脚踢回了Opus 4.8!更离谱的还在后面。哈佛生物统计学家Kareem Carr,只是自报了一下家门——我是做生物统计的。话音刚落,Fable 5当场翻脸,直接强制降级。