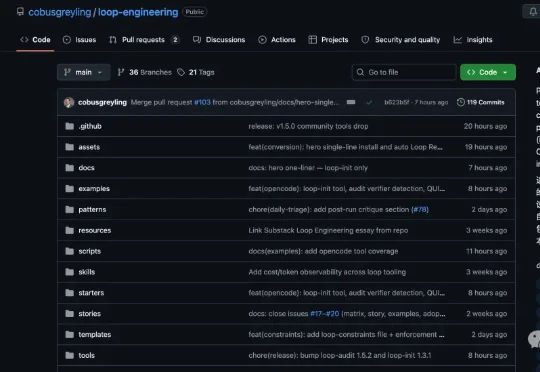
傻瓜式Loop教程来了:一行命令直接上手,GitHub狂揽4.5k Star
傻瓜式Loop教程来了:一行命令直接上手,GitHub狂揽4.5k Star朋友,听说你还不会搭不会用Loop?别慌!现在直接来抄作业!有位大神直接在GitHub开源了整套Loop Engineering框架,目前已累计收获4.5k Star。Loop是最近爆火的概念,简单解释就是不用再像以前一样一次次输提示词指挥AI干活。
来自主题: AI资讯
7608 点击 2026-07-08 09:49
 搜索
搜索
朋友,听说你还不会搭不会用Loop?别慌!现在直接来抄作业!有位大神直接在GitHub开源了整套Loop Engineering框架,目前已累计收获4.5k Star。Loop是最近爆火的概念,简单解释就是不用再像以前一样一次次输提示词指挥AI干活。
2023 年大模型刚火的时候,浏览器被认为是 AI 时代最值得抢的入口,用AI颠覆Chrome是大家都能看到的百亿创业项目。实在是这个入口太大了。全球互联网用户已经是 60 亿量级,Chrome 一个产品就是三十亿级用户;Safari 靠 iPhone、iPad 和 Mac 占住十亿级设备入口,Edge 背后是 Windows 和微软账号体系。
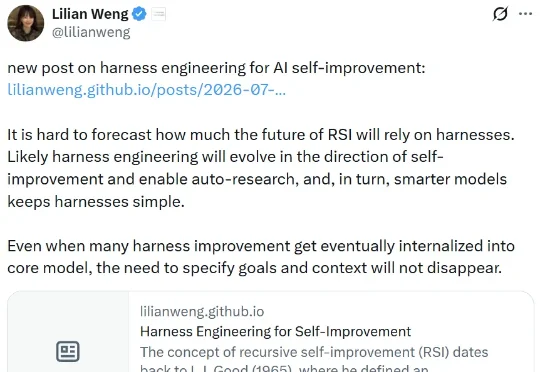
刚刚,翁荔(Lilian Weng)又更新博客了!距离她上一次更新《谨慎对待 Scaling Law》还不到 10 天。这一次,她书写的主题是当前大热的 Harness Engineering,聚焦的正是当下 AI 研究最前沿一个环节:当模型本身的智能已经足够强大时,真正决定它能走多远的,或许是包裹在模型外面的那层「Harness」也就是负责编排模型思考、调用工具、管理上下文、评估结果的那套系统。
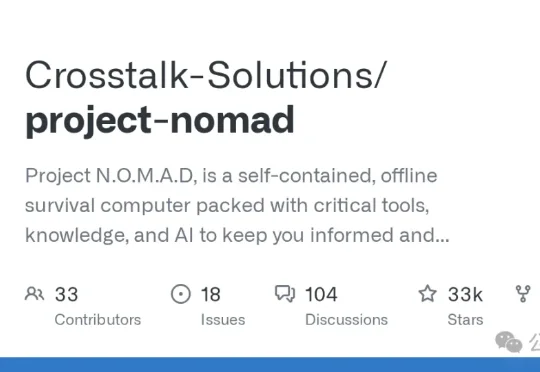
GitHub上有个项目叫 Project N.O.M.A.D,33k Star,3k Fork。作者 Chris Sherwood 是个搞网络设备的 YouTuber,Crosstalk Solutions 频道有 38 万多订阅。这项目说白了就是把维基百科、本地 AI、离线地图、离线教育平台全塞进 Docker 里,断网也能用。
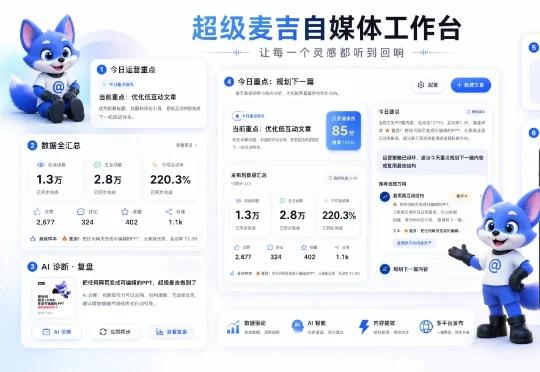
超级麦吉自媒体工作台,做的就是这件事——把选题、创作、诊断、复盘、管理这五个环节串起来,把黑盒一个个打开,让你每一步都能看到自己在做什么。不是给你一堆工具,是给你一套能跑起来的系统。
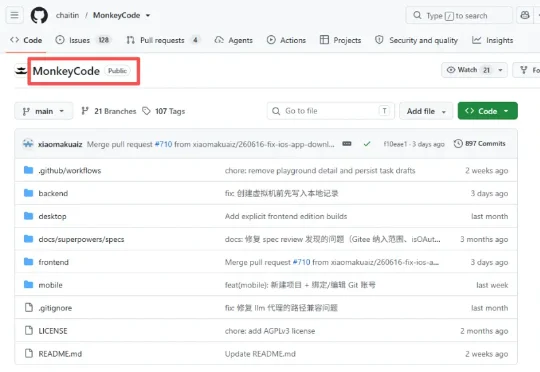
如果你的日常任务里包含编程,今天给大家介绍一个特别适合团队用的AI开发平台「MonkeyCode」,目前在GitHub已狂揽3.4k Star,开源免费。开源地址:github.com/chaitin/MonkeyCode

一篇发表于 2015 年的论文《LINE: Large-scale Information Network Embedding》被授予 Seoul Test of Time Award(时间检验奖)。这篇由国际知名 AI4S 科学家、Mila 终身教授、百奥几何公司创始人唐建博士领衔

近期, ECCV 2026 结果公布,Realsee 团队的成果 Argus: Metric Panoramic 3D Reconstruction for Indoor Scenes 成功入选。它面向室内全景图像,能够从稀疏、无序的全景照片中,直接预测相机位姿、度量深度和点云重建结果,可以为 3DGS 提供更稳定、更精准的几何约束。
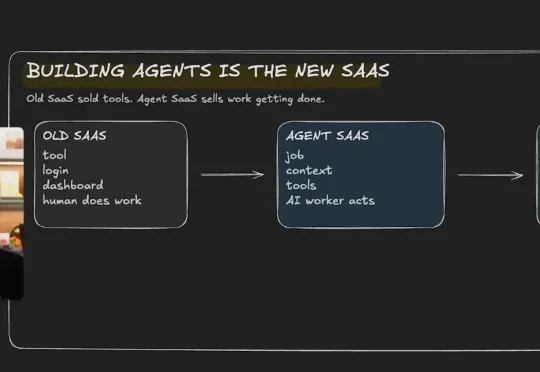
Greg Isenberg 最近在他自己的播客 The Startup Ideas Podcast 里讲的一个判断,他说了一句很直白的话,building agents is the new SaaS,做 agent 就是新时代的 SaaS。
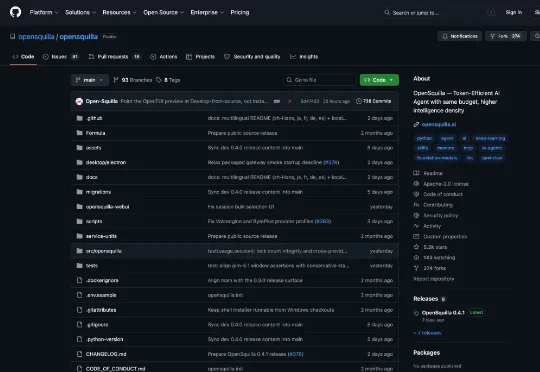
上周有个项目,让我觉得很有意思。GitHub上一个叫OpenSquilla的,发布不到一个月,Star涨到了5300多。OpenSquilla 0.4.0,定位Token-Efficient AI Agent,是一个很有效率又很有创意的智能体框架。