ARPO:智能体强化策略优化,让Agent在关键时刻多探索一步
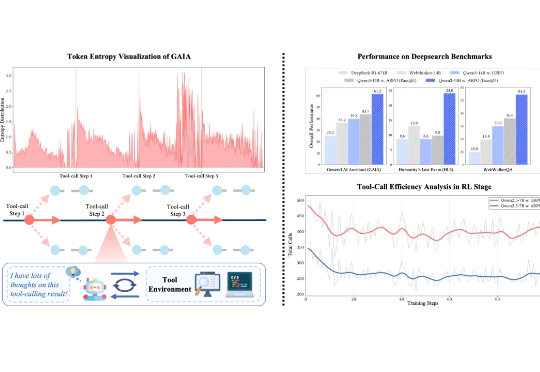
ARPO:智能体强化策略优化,让Agent在关键时刻多探索一步在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM 往往需要结合外部工具进行多轮交互,现有 RL 算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。
来自主题: AI技术研报
7853 点击 2025-08-10 13:29
 搜索
搜索
在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM 往往需要结合外部工具进行多轮交互,现有 RL 算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。