
让大模型“边看边改”,视觉分割准确率直接上涨9% | ICML 2026
让大模型“边看边改”,视觉分割准确率直接上涨9% | ICML 2026智能体时代,如何让视觉分割更准确?
来自主题: AI技术研报
8946 点击 2026-05-27 16:31
 搜索
搜索
智能体时代,如何让视觉分割更准确?

AI范式从Chat转向Agent时,AI的能力边界正在被重新定义。

一个纯Python写的开源项目,竟把OpenAI用Rust写的王牌给秒了!最终战绩6比5,Hermes直接上演工程暴力美学,解释型语言终于逆天改命。
DeepSeek研究员陈德里,在个人博客更新一篇研究综述论文。用的是他自己的技能DeliAutoResearch,DeepSeek-V4-Pro研究和写作,GPT-Image2画图。论文共迭代6次(V1:4 次,V2:1 次,V3:1 次),总耗时6天,进行了约108轮Agent调用,消耗64.8万token,写了2234行LaTeX代码。

多模态Agent最容易制造的一种错觉是:它看过图片,所以它记住了图片。
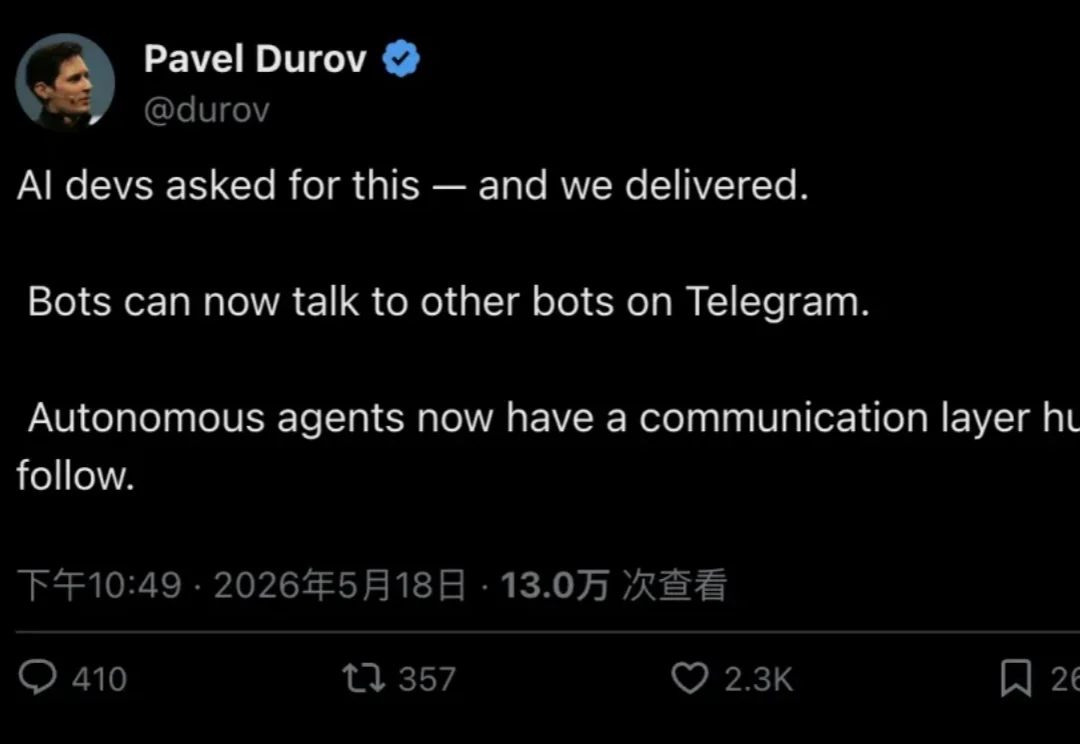
Telegram 创始人 Pavel Durov 宣布:Bot 现在可以直接和其他 Bot 对话。更关键的定义是——自主 Agent 从此拥有了一个「人类可旁观」的原生通信层。Bot API 10.0 早在 5 月 8 日就已落地,Durov 用一条帖子把它重新定义为 AI 基础设施,13 万人围观,2300 人点赞。

说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。

刚刚,蚂蚁集团旗下支付宝亮出AI支付“全家桶”:全球首个Token Pay服务、AI钱包产品,连同此前已落地的AI付与AI收,正式构成一套覆盖授权、支付、结算、管理、安全的全栈AI原生支付体系。
谁懂啊家人们??
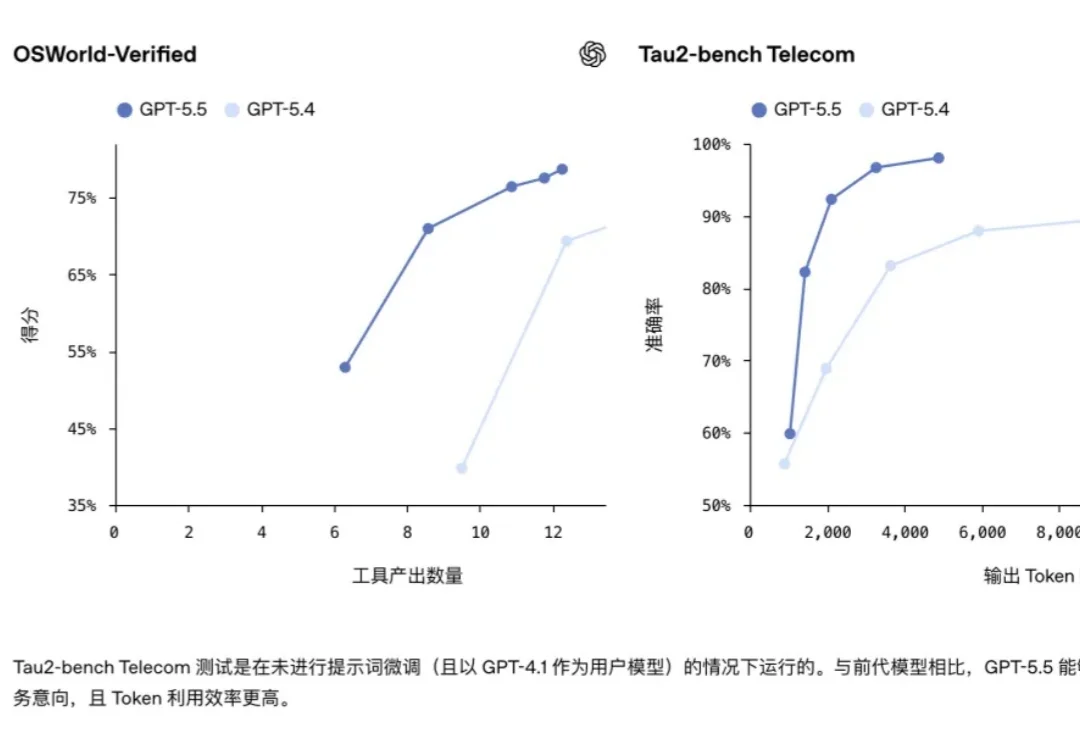
判断 Agent 靠谱与否,核心指标只有一个:是不是真干完活了