
超越OpenAI,中国00后团队攻破「记忆」难题!打造下一个AI互联网时刻
超越OpenAI,中国00后团队攻破「记忆」难题!打造下一个AI互联网时刻80年前,阿根廷作家博尔赫斯写过一个寓言,叫《博闻强记的富内斯》。博尔赫斯笔下的富内斯,拥有过目不忘、堪称完美的记忆,却无法思考,因为思考依赖于遗忘和抽象。
来自主题: AI技术研报
9475 点击 2026-07-15 14:34
 搜索
搜索
80年前,阿根廷作家博尔赫斯写过一个寓言,叫《博闻强记的富内斯》。博尔赫斯笔下的富内斯,拥有过目不忘、堪称完美的记忆,却无法思考,因为思考依赖于遗忘和抽象。

一个比Anthropic更好的AI to B故事。

这年头,提示词工程也能发ICML了???

7月14日,AI for Materials公司深度原理Deep Principle完成A系列融资,累计融资金额近10亿元人民币。A系列融资的募集资金将用于以下方向:持续升级AI Scientist能力,扩大全球领先优势;依托AI Materials Factory,加速重点材料管线研发落地;深化海内外上下游合作,共同构建产业生态。
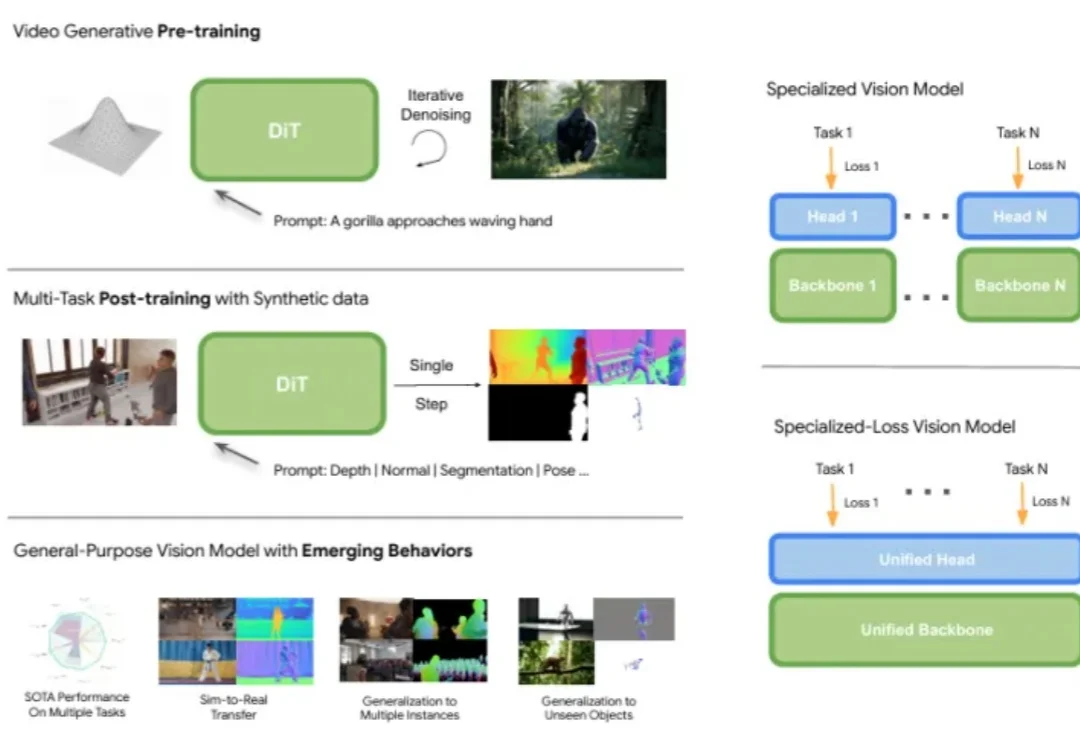
如果想开发一个视频理解应用,你会怎么做?

Z Potentials 获悉,近日,国内具身触觉头部企业千觉机器人科技(上海)有限公司(以下简称“千觉机器人”或“Xense Robotics”)完成亿元融资。本轮融资由顶级具身智能产业方与吉德电器战略投资,新锐投资机构天季资本共同投资。

3D空间数据的瓶颈,从来不是算法,而是标注。
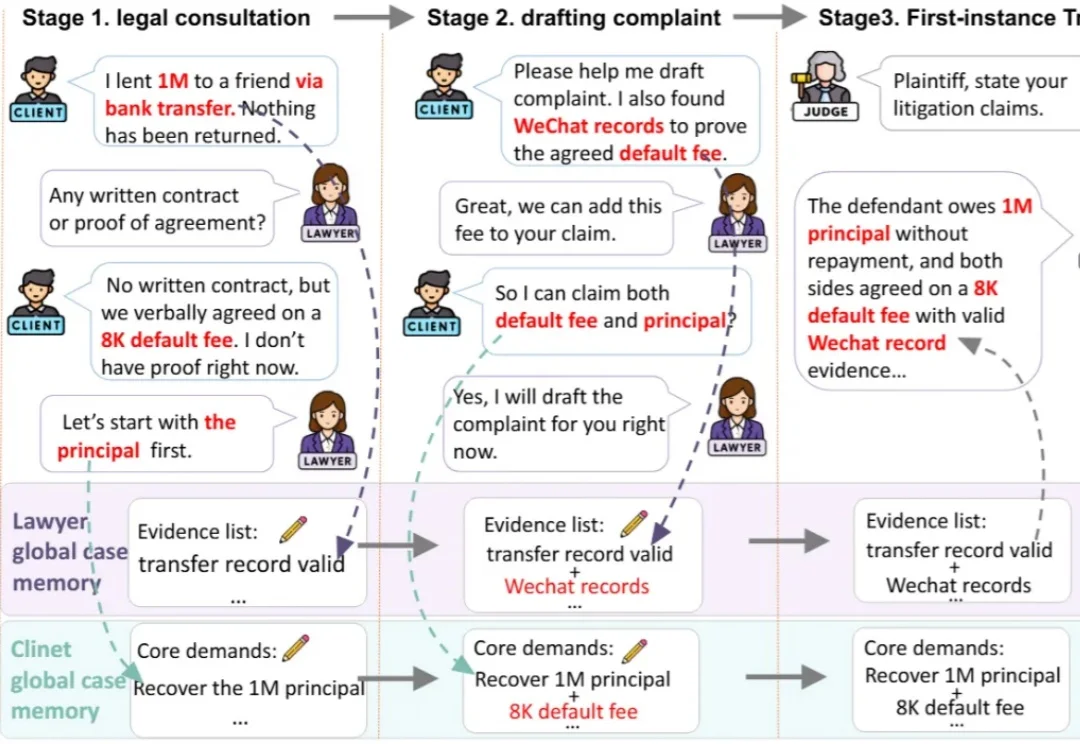
打官司,从来不是一问一答就能结束的事。
把一个Bug交给Claude Code或Codex,十几分钟后它回了一句“Done”和一大片Diff。过程中它读错了什么、为什么反复改同一个文件、最后有没有重新跑测试......开发者想知道就只能去几百行日志里碰运气。7月11日,一个名叫Mindwalk的开源项目发布了v0.1.0。
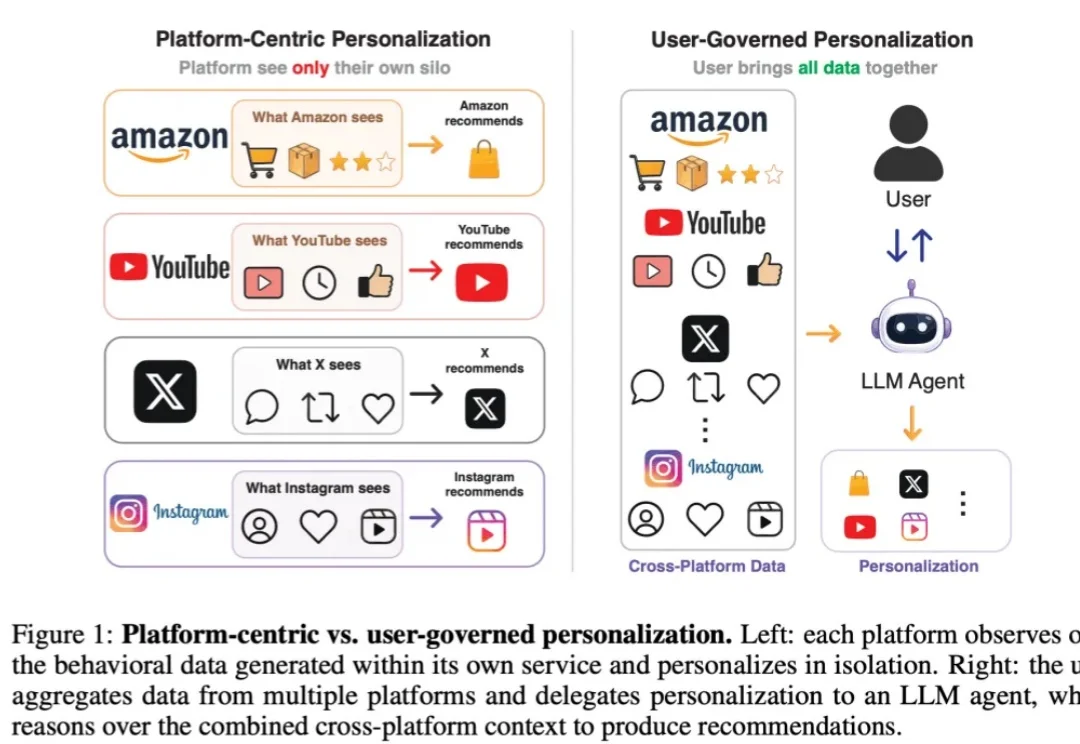
在过去二三十年的互联网发展中,个性化推荐几乎一直是平台的核心能力之一。打开视频 app,平台决定你接下来会刷到什么视频;打开购物软件,平台预测你可能会购买什么商品;打开短视频 app,平台根据你的浏览、点赞、停留和互动,不断优化信息流。某种意义上,现代互联网的用户体验本身就是由推荐系统塑造的。