
硅谷百亿美金押注「AI造AI」,清华系创业团队衔远科技反手把模型开源了!
硅谷百亿美金押注「AI造AI」,清华系创业团队衔远科技反手把模型开源了!新智元报道 2026年,AI行业最昂贵的新故事,已经不只是「训练一个更大的模型」。 资本开始直接押注:让AI参与制造下一代AI。 4月,AlphaGo核心缔造者David Silver创办的 Inef
来自主题: AI资讯
8540 点击 2026-08-01 13:33
 搜索
搜索
新智元报道 2026年,AI行业最昂贵的新故事,已经不只是「训练一个更大的模型」。 资本开始直接押注:让AI参与制造下一代AI。 4月,AlphaGo核心缔造者David Silver创办的 Inef

据英国《金融时报》7 月 29 日报道,谷歌 DeepMind 已经重组了曾打造诺贝尔奖级成果 AlphaFold 的核心团队:不再保留独立的 AlphaFold 团队,而是将相关研究人员分流至多个战略项目。这一调整被视为 DeepMind 将重心进一步转向 Gemini 大模型和 AI Agent 的重要信号。
面向 Gen Alpha 的视频共创社交平台 Wapoo 已完成近千万美元天使轮融资。本轮融资由某互联网集团旗下战略投资方投资,其在全球化产品运营、年轻用户生态及新兴市场拓展方面已具备一定积累,探奇资本担任公司独家融资顾问。目前,Wapoo 团队约 10 人,并已开始筹备下一轮融资。

2023 年他在深圳创立听象科技,推出自有品牌昂听 ELEHEAR(下文统一简称 ELEHEAR)。前期发布 Alpha 系列产品试水助听器市场,2024 年 10 月推出旗舰产品 Beyond,凭借全栈自研的 AI 助听器+远程实时验配的新模式,用 1 年时间做到了美国亚马逊助听器类目 Top1,年销超 1500 万美元,市场份额从 1% 迅速增长至 18%。

家人们,最近刷到一个硅谷新瓜——美国有钱人最近流行一种新式鸡娃,把孩子从传统学校撤出来,送进AI私塾。所谓AI私塾,就是上课没有老师、由AI来教的私立学校。最出名的一所叫Alpha School,收着全旧金山最贵的学费:一年7.5万美元,折合人民币约52万。

Ricursive Intelligence 由 Google AlphaChip 项目负责人 Anna Goldie 和 Azalia Mirhoseini 于 2025 年创立。与当前大多数 AI 芯片创业公司不同,Ricursive 并不制造芯片,而是试图改变芯片被设计出来的方式。
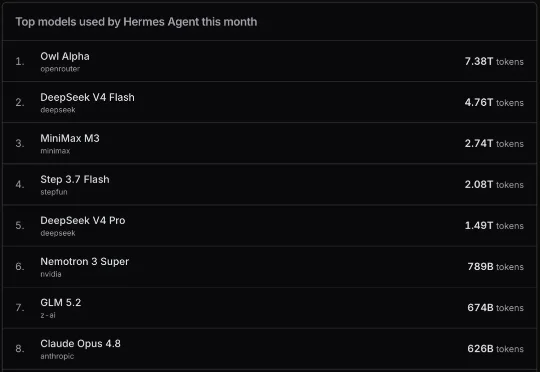
最近几个月,一个名为“Owl Alpha”的神秘模型持续霸榜OpenRouter。它调用量长期位居全球前三,在Hermes、Claude Code和OpenClaw几大Agent模型中分别位列第一、第二和第三,不少开发者将其称为今年最令人意外的一匹“黑马”。

Verily这家公司身上有太多漂亮标签。它从Google X走出来,是Alphabet孵化多年的生命科学资产,做过临床研究平台、慢病管理、人群疾病监测、可穿戴设备、研究数据环境、个人健康应用和人工智能助手。每一个方向单独拿出来,都足够讲一篇精准医疗的未来故事。

Google 将开始通过其云服务提供软件公司 SandboxAQ 的专业人工智能模型,扩展企业和研究机构对旨在加速药物发现、材料科学和半导体制造技术的访问。SandboxAQ 是 Alphabet 的分拆公司,是越来越多致力于利用 AI 解决棘手研究问题的公司之一。

如果我们谈到 AI 赋能带来的科学突破,AlphaFold 一定是不可忽略的一项。它解决了困扰生物学界半个多世纪的蛋白质折叠难题,大量压缩了得到蛋白质结构的时间,从原来的一年,到现在的几分钟。它的核心开发者之一 John Jumper 也因这一贡献在 2024 年摘得诺贝尔化学奖。