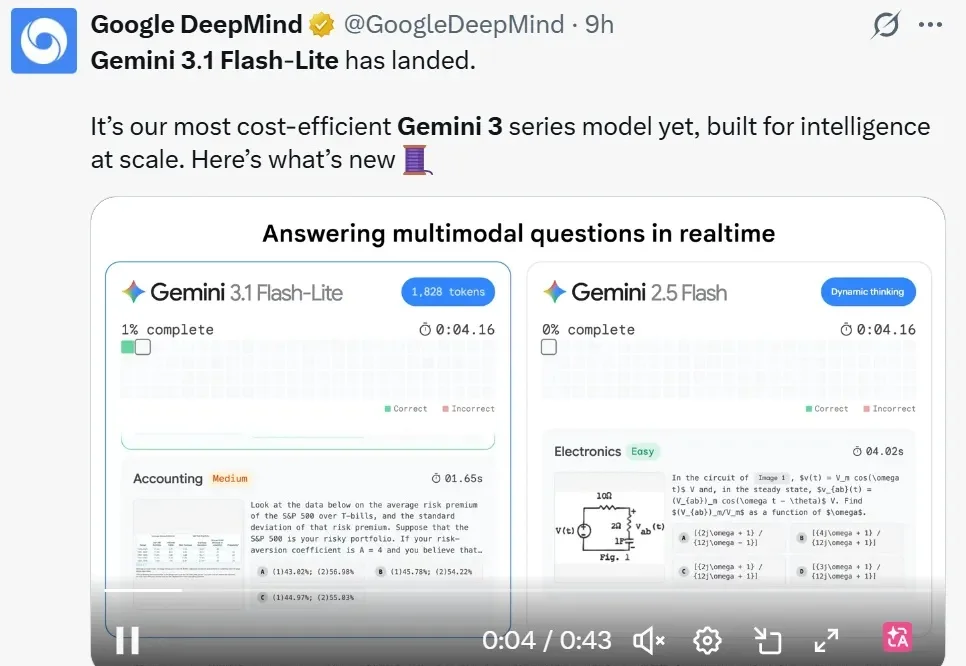
FlashAttention-4正式发布:算法流水线大改,矩阵乘法级速度
FlashAttention-4正式发布:算法流水线大改,矩阵乘法级速度近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!
来自主题: AI技术研报
10328 点击 2026-03-06 15:30