罗福莉首秀前,小米突然发布!代码全球最强,总体媲美DeepSeek-V3.2【附实测】
罗福莉首秀前,小米突然发布!代码全球最强,总体媲美DeepSeek-V3.2【附实测】今天,小米发布并开源了最新MoE大模型MiMo-V2-Flash,总参数309B,激活参数15B。今日上午,小米2025小米人车家全生态合作伙伴大会上,Xiaomi MiMO大模型负责人罗福莉将首秀并发布主题演讲。
来自主题: AI资讯
9173 点击 2025-12-17 09:41
 搜索
搜索
今天,小米发布并开源了最新MoE大模型MiMo-V2-Flash,总参数309B,激活参数15B。今日上午,小米2025小米人车家全生态合作伙伴大会上,Xiaomi MiMO大模型负责人罗福莉将首秀并发布主题演讲。

谷歌发布Gemini 2.5 Flash原生音频模型,不仅能保留语调进行实时语音翻译,更让AI在复杂指令和连续对话中像真人一样自然流畅。这一更新标志着AI从简单的「文本转语音」跨越到了真正的「拟人化交互」时代。
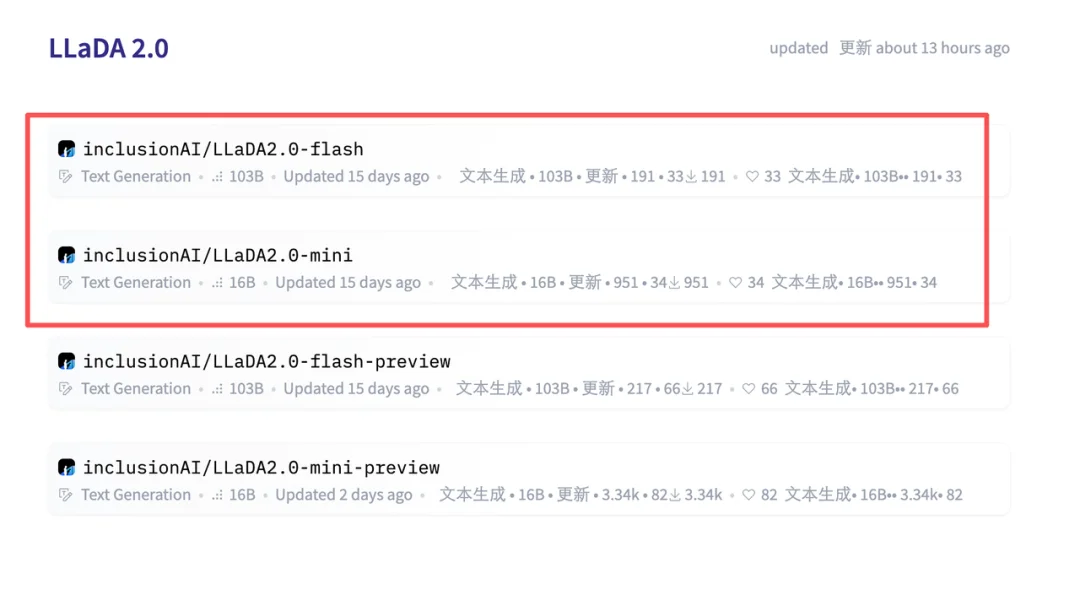
前段时间,我们在 HuggingFace 页面发现了两个新模型:LLaDA2.0-mini 和 LLaDA2.0-flash。它们来自蚂蚁集团与人大、浙大、西湖大学组成的联合团队,都采用了 MoE 架构。前者总参数量为 16B,后者总参数量则高达 100B—— 在「扩散语言模型」这个领域,这是从未见过的规模。

宾夕法尼亚大学沃顿商学院(The Wharton School)今年发布了一系列名为《Prompting Science Reports》的重磅研究报告。他们选取了2024-2025最常用的模型(如GPT-4o, Claude 3.5 Sonnet, Gemini Pro/Flash等),在极高难度的博士级基准测试(GPQA Diamond)上进行了数万次的严谨测试。
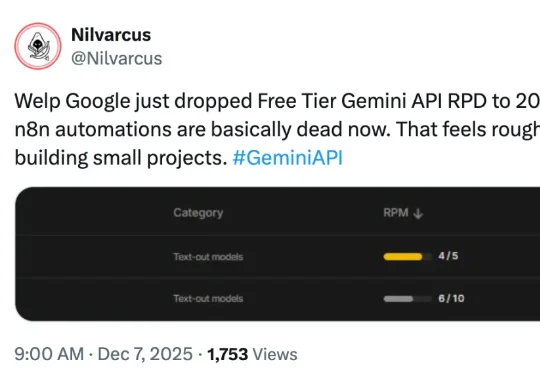
“谷歌刚把免费版 Gemini API 的每日请求次数从 250 降到了 20,我的 n8n 自动化脚本现在基本都用不了了。这对任何开发小型项目的人来说都是个打击。”网友 Nilvarcus 表示。近日,有网友曝出 Google 收紧了 Gemini API 免费层级的限制:Pro 系列已经取消,Flash 系列每天仅 20 次。这对开发者来说远远不够用。
作为中国最大的B2B供应链平台,阿里巴巴集团旗下源头厂货平台1688今年几乎以「梭哈」的决心押注和布局AI。继1688 AI版App、1688诚信通AI版等一系列AI原生产品后,1688近日又发布了一个跨境电商AI智能体——遨虾(alphashop.cn)。
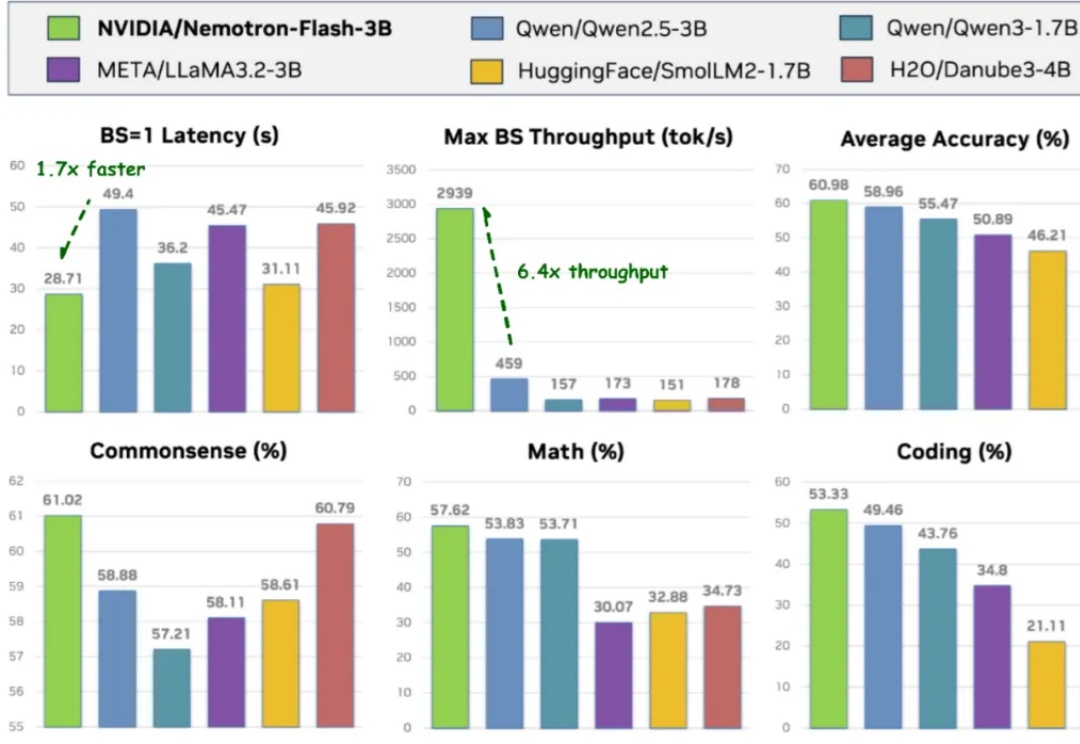
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

2025年11月,印度国会议员、前外交部国务部长沙希·塔鲁尔(Shashi Tharoor)在《印度教徒报》发表了一篇颇具影响力的专栏文章。文章中,他以“十字路口”为喻,描绘了印度IT产业的集体焦虑。
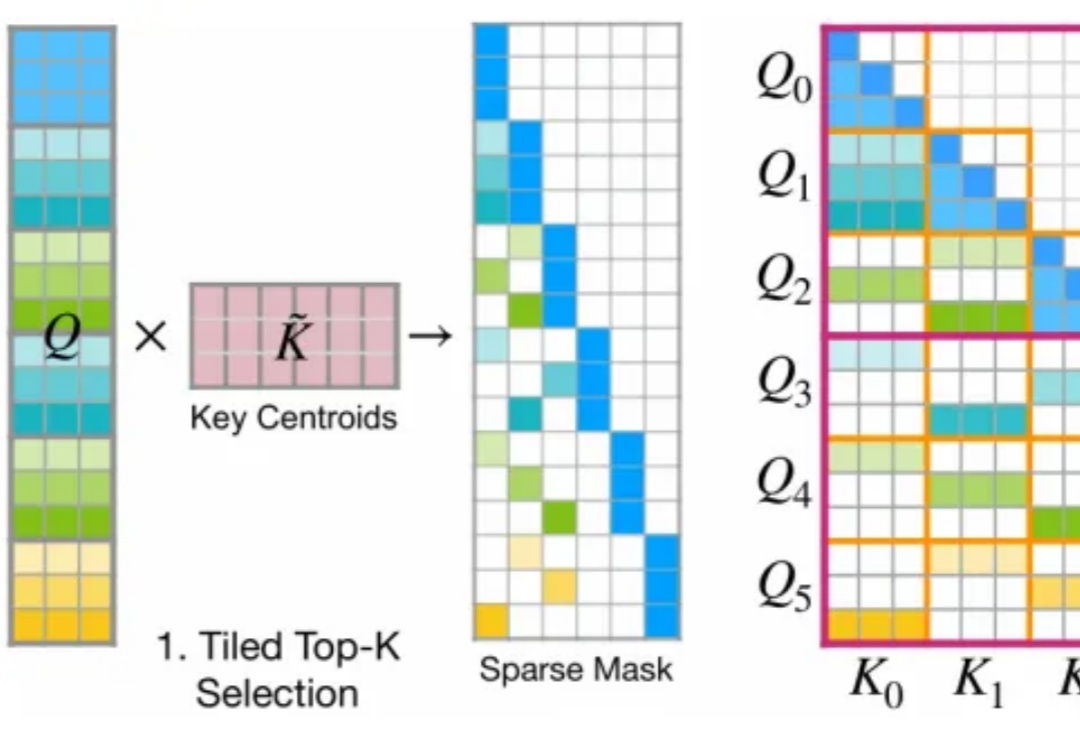
今年 2 月,月之暗面提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。
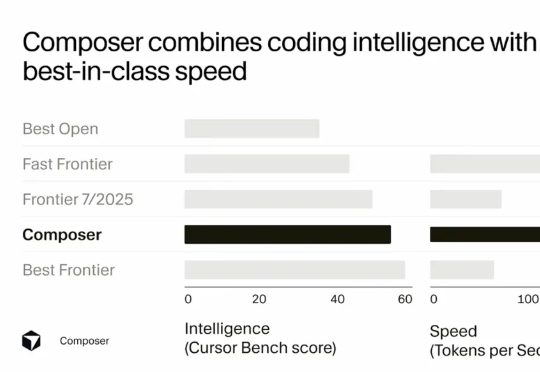
Sasha Rush 在分享开头就提到,Cursor Composer 在他们的内部 benchmark 上的表现几乎与最好的 Frontier 模型(前沿模型)持平,并且优于去年夏天发布的所有模型。它的表现明显好于最好的开源模型,以及那些被标榜为"快速"的模型。