
5行代码,逼疯整个硅谷!澳洲放羊大叔,捅开AI编程奇点
5行代码,逼疯整个硅谷!澳洲放羊大叔,捅开AI编程奇点最近,一个澳大利亚的养羊大叔用5行代码捅破AI编程天花板的故事,彻底火出圈了。2025年底,在铲羊粪的间隙,Geoffrey Huntley写出了下面这个仅含5行代码的Bash脚本while :; do cat PROMPT.md | claude-code ; done
来自主题: AI资讯
9394 点击 2026-01-14 17:29
 搜索
搜索
最近,一个澳大利亚的养羊大叔用5行代码捅破AI编程天花板的故事,彻底火出圈了。2025年底,在铲羊粪的间隙,Geoffrey Huntley写出了下面这个仅含5行代码的Bash脚本while :; do cat PROMPT.md | claude-code ; done

当整个科技圈都在为「谷歌黑魔法」集体高潮时,真相恐给了所有人一记耳光。那套被捧上神坛的「并行验证循环」,不过是社交网络上AI生成的「赛博跳大神」。

参数越小,智商越高?Gemini 3 Flash用百万级长上下文、白菜价成本,把自家大哥Pro按在地上摩擦。谷歌到底掏出了什么黑魔法,让整个大模型圈开始怀疑人生?
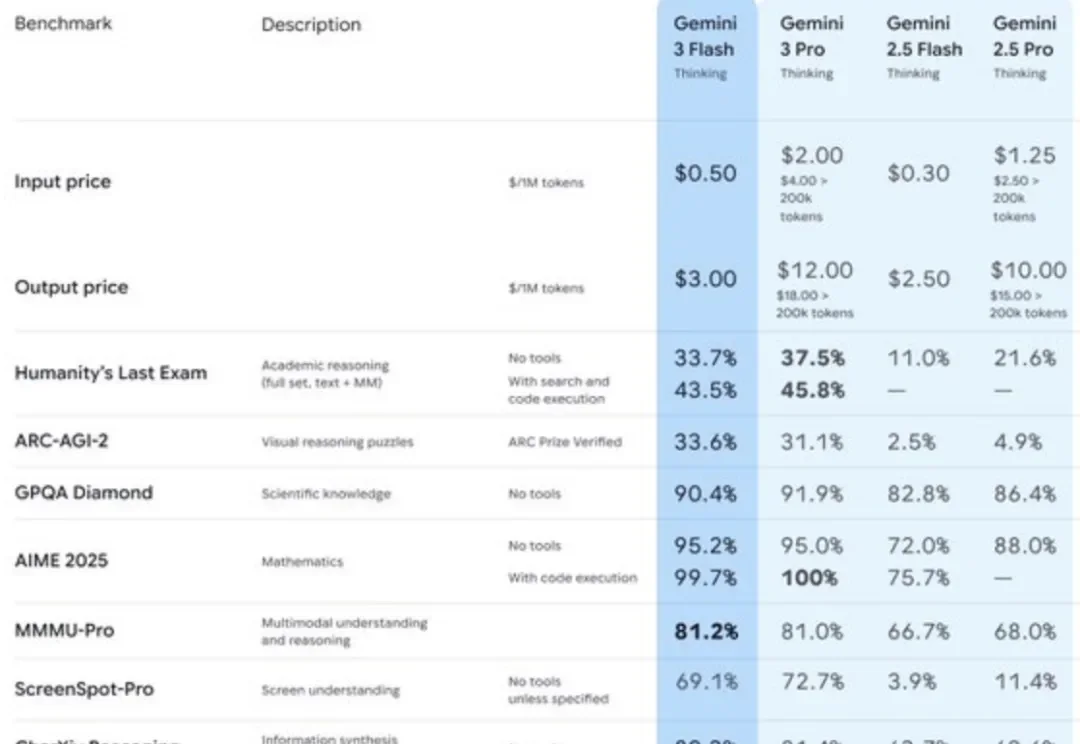
倒反天罡! Gemini 3 Flash的表现在SWE-Bench Verified测试中获得了78%的分数,比超大杯Pro还略胜一筹。

2025年底,最令人印象深刻的AI圈大事莫过于Gemini 3 Flash的发布。

AI不应是巨头游戏,模型也不是越大越聪明。近日,「Transformer八子」中的Ashish Vaswani和Parmar共同推出了一个8B的开源小模型,剑指Scaling Law软肋,为轻量化、开放式AI探索了新方向。
谷歌丢出Gemini 3 Flash,给AI圈示范了啥叫:小孩子才做选择题,成年人当然是全都要(doge)。一个公式来形容这款新模型:Gemini 3 Flash=Pro级智能+Flash级速度+更低价格。

AI竞技场开始清场。

谷歌在2025年底甩出「王炸」:Gemini 3 Flash! 这款模型彻底打破了「快就一定笨、强就一定贵」的定律,以3倍于前代的速度实现「零延迟」响应,甚至在编程和逻辑推理上反超了Pro级大哥。

开源模型再次迎来一位重磅选手,就在刚刚,小米正式发布并开源新模型 MiMo-V2-Flash。