快一点!再快一点!快到世界能实时生成|和生数科技张金涛聊:Vidu S1、推理加速、实时交互模型
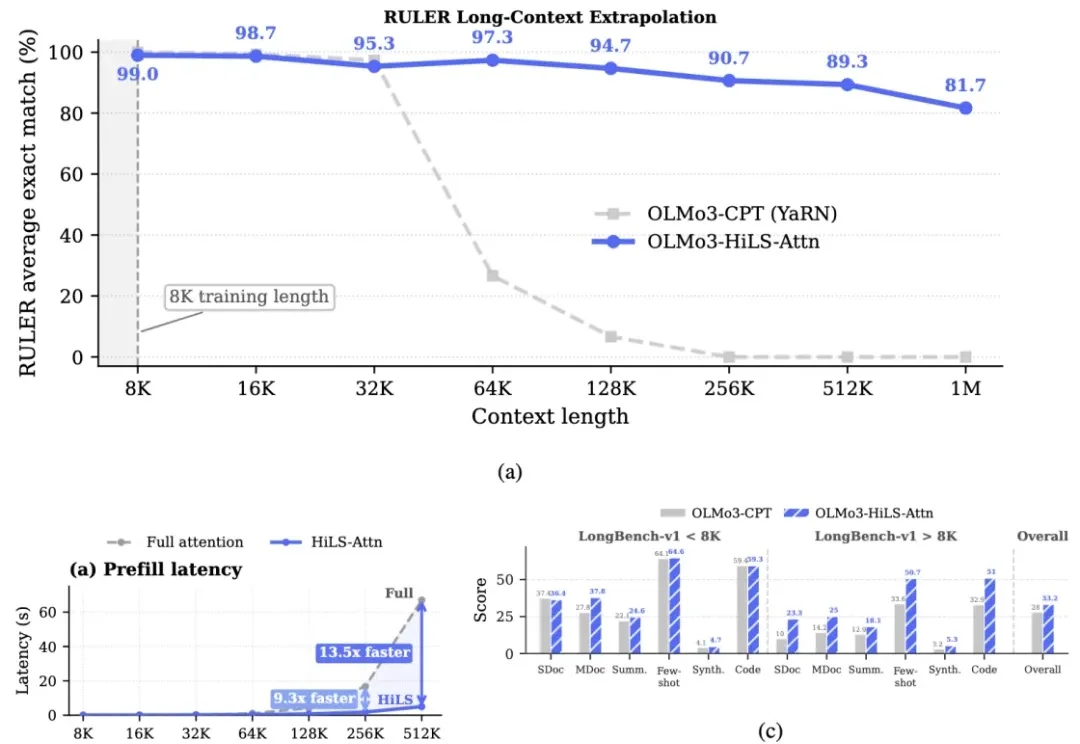
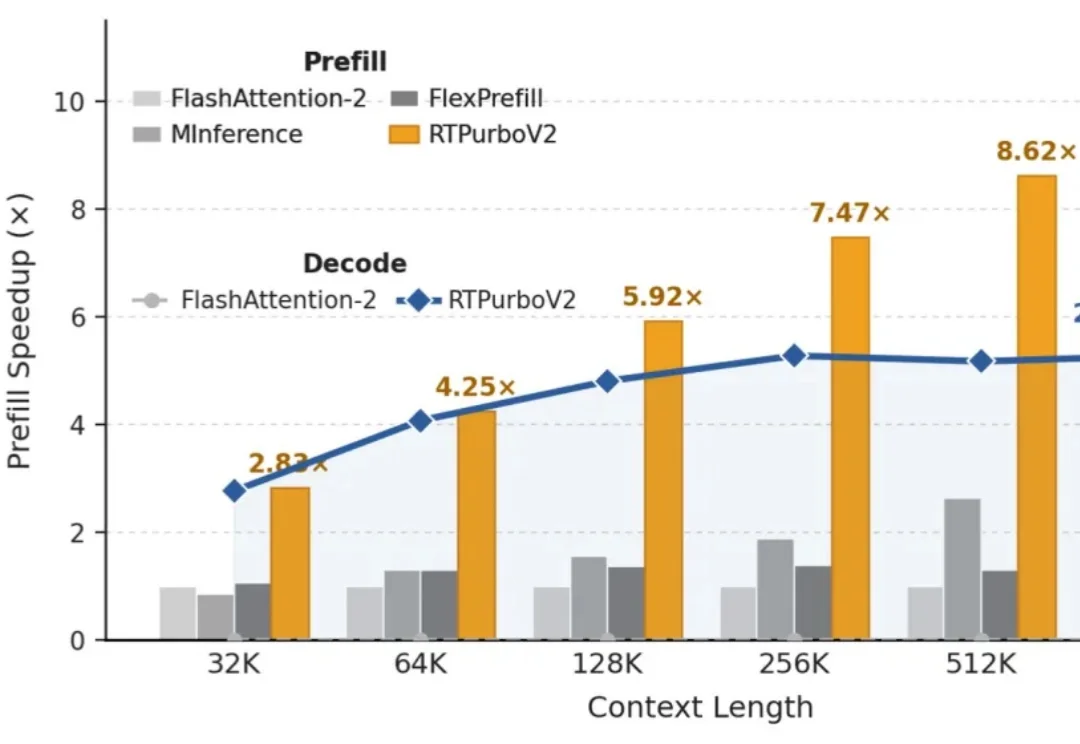
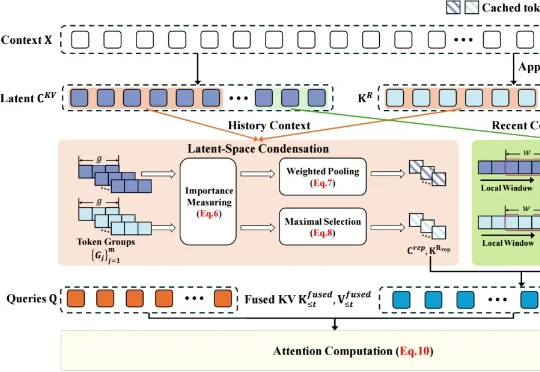
快一点!再快一点!快到世界能实时生成|和生数科技张金涛聊:Vidu S1、推理加速、实时交互模型金涛今年 26 岁,还是清华在读博士。真正把他带进「推理加速」的,是一个很朴素的判断——当大家都默认 FlashAttention 已经把 Attention 算子做到极致时,他却发现:显卡上明明还有更快的计算单元没被用起来 ——「这么明显的收益,为什么没人做?」
来自主题: AI资讯
9215 点击 2026-07-25 10:56