DeepSeek新模型上线!引入DSA新稀疏注意力,还又狙了CUDA一枪
DeepSeek新模型上线!引入DSA新稀疏注意力,还又狙了CUDA一枪刚发V3.1“最终版”,DeepSeek最新模型又来了!DeepSeek-V3.2-Exp刚刚官宣上线,不仅引入了新的注意力机制——DeepSeek Sparse Attention。还开源了更高效的TileLang版本GPU算子!
来自主题: AI资讯
11932 点击 2025-09-29 19:04
 搜索
搜索
刚发V3.1“最终版”,DeepSeek最新模型又来了!DeepSeek-V3.2-Exp刚刚官宣上线,不仅引入了新的注意力机制——DeepSeek Sparse Attention。还开源了更高效的TileLang版本GPU算子!
2017 年,一篇标题看似简单、甚至有些狂妄的论文在线上出现:《Attention Is All You Need》。
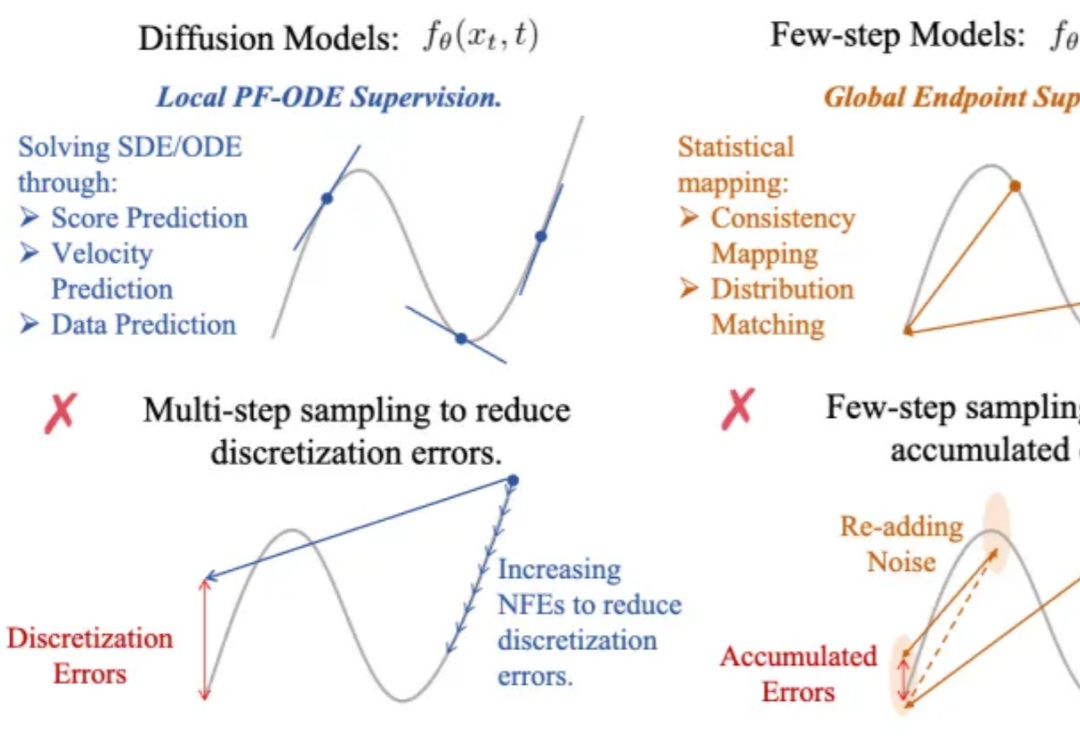
生成式AI的快与好,终于能兼得了?
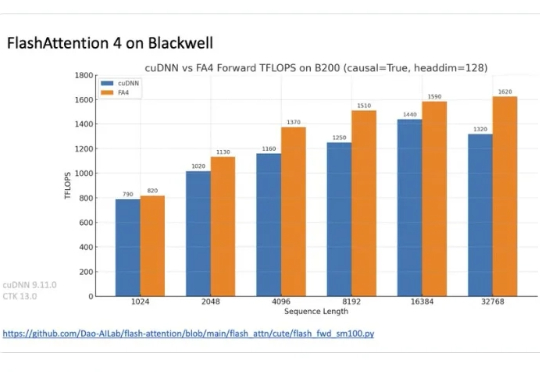
在正在举办的半导体行业会议 Hot Chips 2025 上,TogetherAI 首席科学家 Tri Dao 公布了 FlashAttention-4。

稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。

近年来,大语言模型(LLM)的能力越来越强,但它们的“饭量”也越来越大。这个“饭量”主要体现在计算和内存上。当模型处理的文本越来越长时,一个叫做“自注意力(Self-Attention)”的核心机制会导致计算量呈平方级增长。这就像一个房间里的人开会,如果每个人都要和在场的其他所有人单独聊一遍,那么随着人数增加,总的对话次数会爆炸式增长。
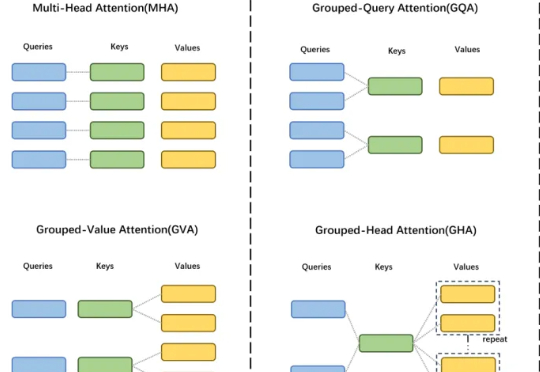
GTA 工作由中国科学院自动化研究所、伦敦大学学院及香港科技大学(广州)联合研发,提出了一种高效的大模型框架,显著提升模型性能与计算效率。
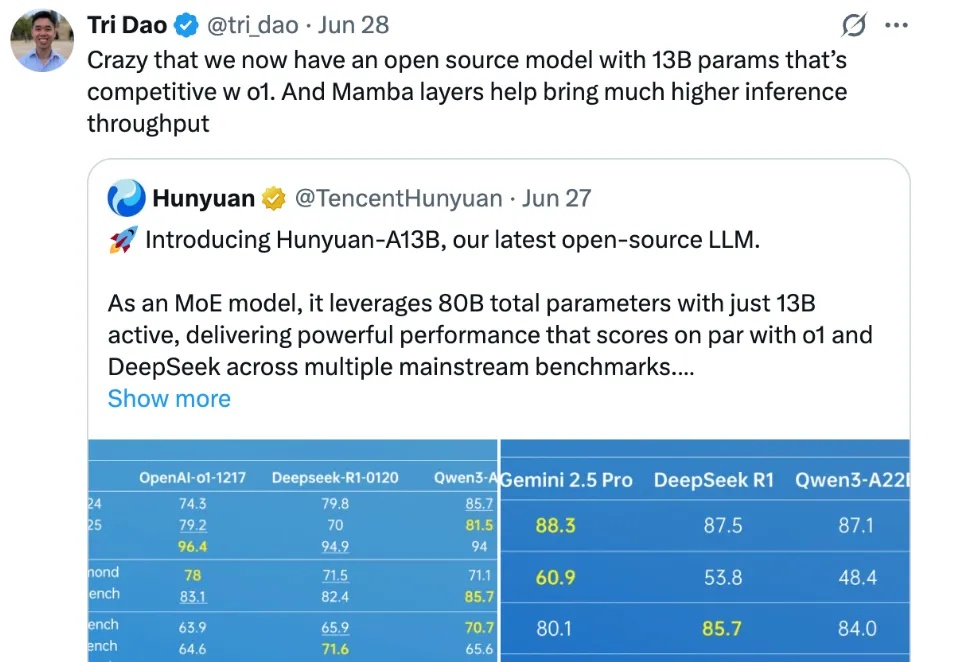
腾讯混元,在开源社区打出名气了。
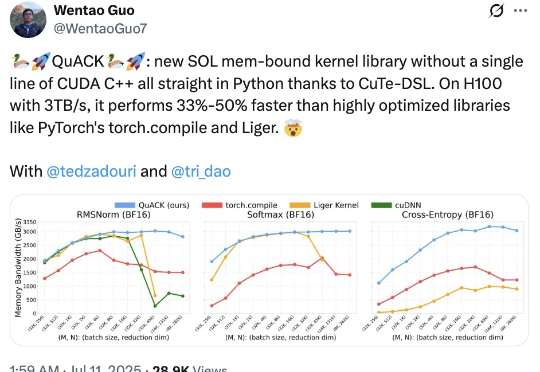
无需CUDA代码,给H100加速33%-50%! Flash Attention、Mamba作者之一Tri Dao的新作火了。
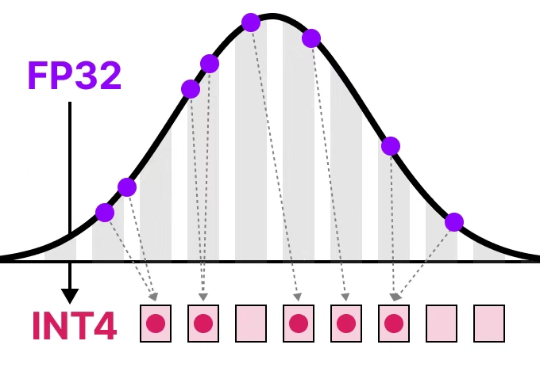
清华大学朱军教授团队提出SageAttention3,利用FP4量化实现推理加速,比FlashAttention快5倍,同时探索了8比特注意力用于训练任务的可行性,在微调中实现了无损性能。