Attention真的可靠吗?上海大学联合南开大学揭示多模态模型中一个被忽视的重要偏置问题
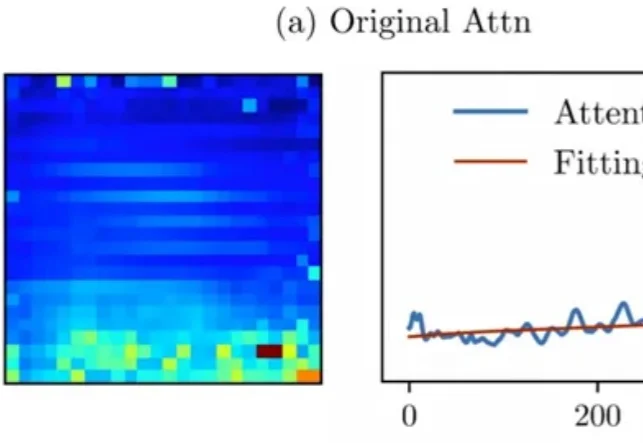
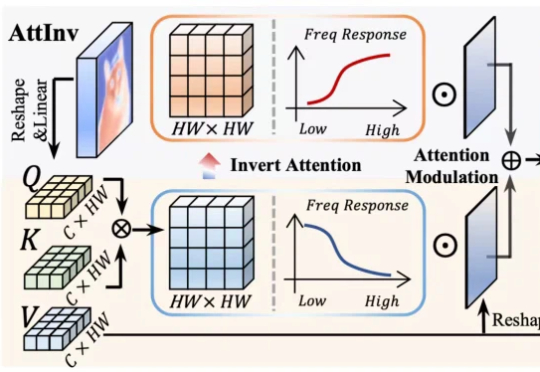
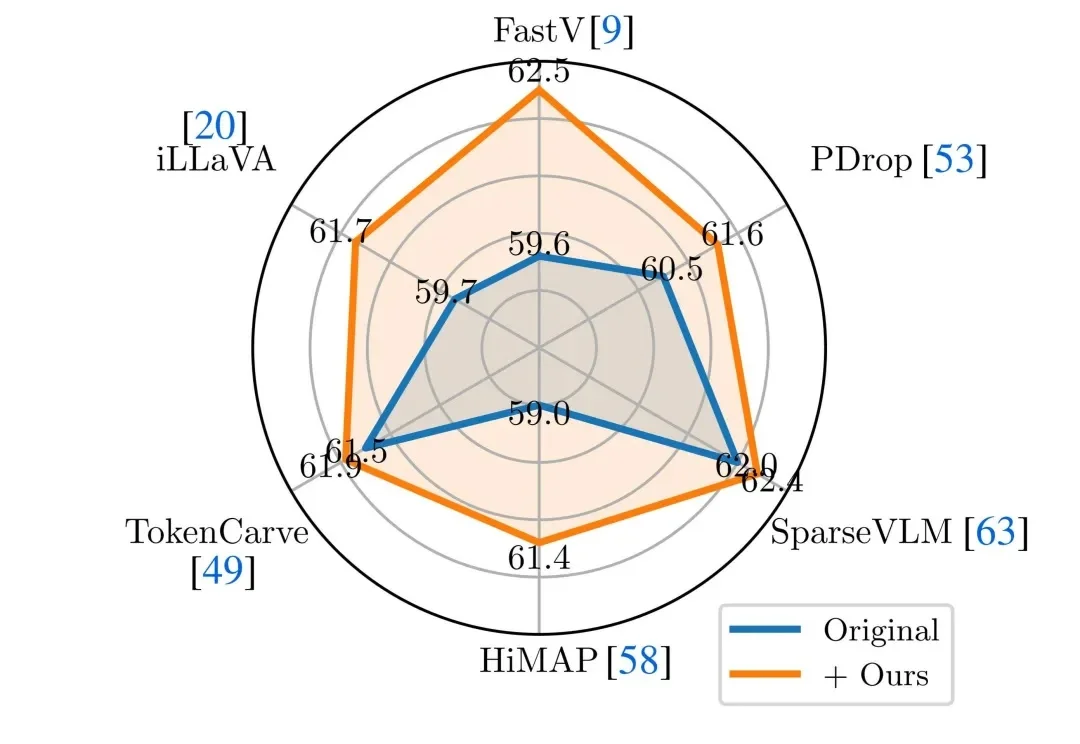
Attention真的可靠吗?上海大学联合南开大学揭示多模态模型中一个被忽视的重要偏置问题近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。
来自主题: AI技术研报
11697 点击 2026-02-06 10:39