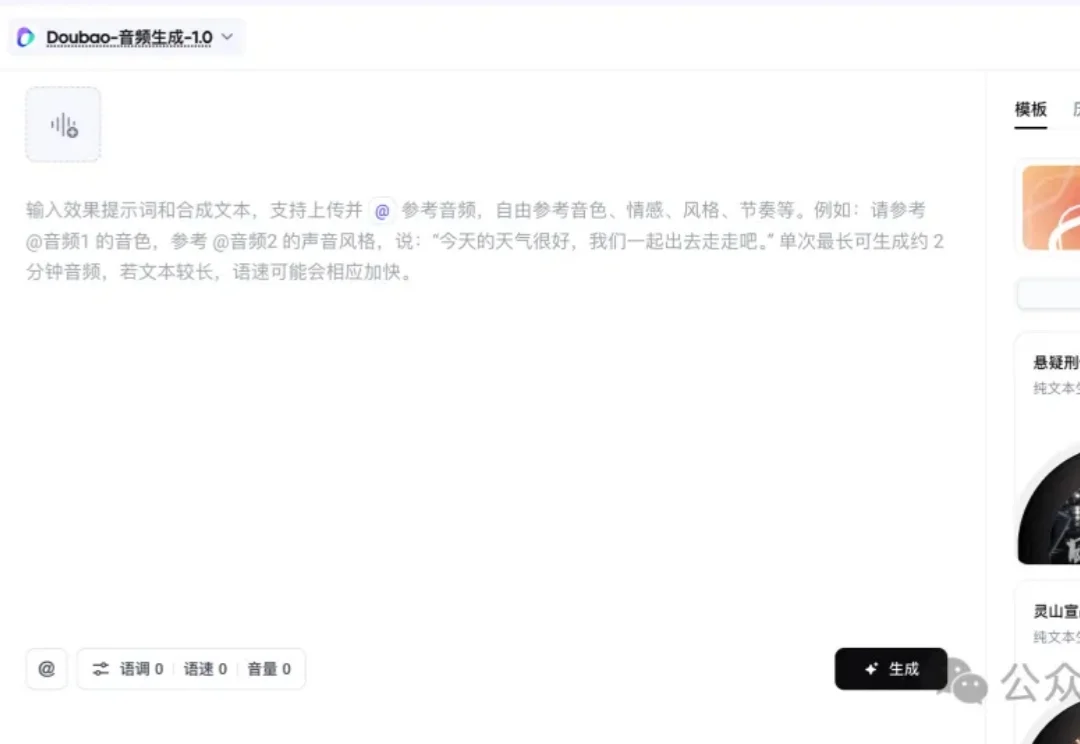
实测豆包音频生成模型:语音模型的Seedance2.0时刻来了!
实测豆包音频生成模型:语音模型的Seedance2.0时刻来了!火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。
来自主题: AI产品测评
7987 点击 2026-06-24 10:29
 搜索
搜索
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。
Boson AI 与 SGLang-Omni 团队宣布,SGLang-Omni 已完成对 Higgs Audio v3 TTS 的端到端 Serving 支持。作为一家成立于 2023 年的 AI 基础设施公司,李沐与 Alex Smola共同创立了 Boson AI,聚焦大模型时代的系统与基础设施创新。

a16z Speedrun SR006里有60家公司,57%做B2B。只有一家做Audio。我们和它的创始人Artin聊了45分钟,发现它踩中的东西比看起来大得多。SUN — AI-native audio learning, built around youAI让音频内容的生成成本暴跌80倍,但没有人把这件事变成一个主动为你服务的消费级学习产品

《读佳》获知,Soul推出AI语音创作平台“AudioFactory”,基于生成式人工智能模型技术为用户提供丰富、多样的AI功能服务,包括但不限于播客AI生成、语音生成合成、AI生成文案等,具体以播客生成、音色克隆等AI语音功能为主,或为其冲击港股IPO再添技术筹码。

阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。

模思智能成立于2024年,位于上海徐汇区,由上海创智学院与复旦大学联合孵化,是国内少数完成“全模态基座模型能力闭环”的初创公司之一,致力于构建统一Token表达框架下的“情境智能”能力,推动Agent系统在真实世界中的自主交互与任务执行。

语音合成大家都不陌生,这两年市面上各种AI配音也层出不穷。

2026 年,阿联酋哈利法大学的邹航博士和他所在的团队,做出了全世界第一个射频大模型,名字叫 RF GPT。这个模型能直接看懂无线信号,就像 GPT 4o 能看懂图片、Qwen2 Audio 能听懂声音一样。你把无线信号扔给它,它不仅能告诉你这里面有几种信号、分别是什么技术,还能分析出有没有信号在打架、哪个是 5G 哪个是蓝牙、甚至能数出来 WiFi 网络里有多少个用户同时在用。

相似度超越Seed-TTS、MiniMax-Speech等知名模型。昨晚,美团LongCat团队发布了文本转语音模型LongCat-AudioDiT,并开源1B、3.5B参数量的版本。这一模型的最大特点,是彻底抛弃了梅尔谱等中间表示,直接在波形潜空间进行基于扩散模型的文本转语音。通俗地说,这一模型直接根据声音本身的规律进行生成,“雕刻”出最原始的声音波形,从根源阻断数据转换的级联误差。

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。