小红书,再造一个更有「声」命力的社区
小红书,再造一个更有「声」命力的社区2026 马年注定迎来一个「AI 味」最浓的春节。
来自主题: AI技术研报
10245 点击 2026-02-12 15:34
 搜索
搜索
2026 马年注定迎来一个「AI 味」最浓的春节。
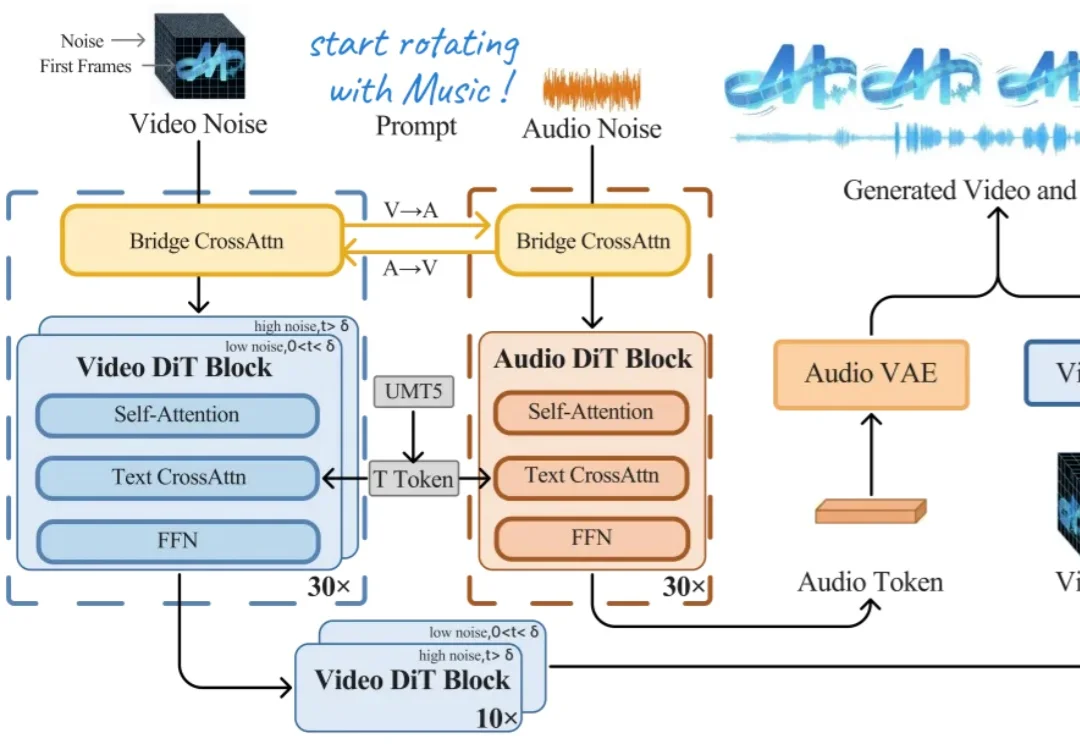
今天上午,上海创智学院 OpenMOSS 团队联合初创公司模思智能(MOSI),正式发布了端到端音视频生成模型 —— MOVA(MOSS-Video-and-Audio)。
时代变了,就连 Linus Torvalds 现在也氛围编程(Vibe Coding)了。

文本领域的大模型满分选手,换成语音就集体挂科?大模型引以为傲的多轮对话逻辑,在真实人声面前竟然如此脆弱。Scale AI正式发布首个原生音频多轮对话基准Audio MultiChallenge,直接撕开了大模型靠合成语音评测维持的优等生假象。实验显示,强如Gemini 3 Pro在真实场景下的通过率也仅过半数,而GPT-4o Audio的表现更是令人大跌眼镜。
继 SAM(Segment Anything Model)、SAM 3D 后,Meta 又有了新动作。

谷歌发布Gemini 2.5 Flash原生音频模型,不仅能保留语调进行实时语音翻译,更让AI在复杂指令和连续对话中像真人一样自然流畅。这一更新标志着AI从简单的「文本转语音」跨越到了真正的「拟人化交互」时代。
在多模态生成领域,由视频生成音频(Video-to-Audio,V2A)的任务要求模型理解视频语义,还要在时间维度上精准对齐声音与动态。早期的 V2A 方法采用自回归(Auto-Regressive)的方式将视频特征作为前缀来逐个生成音频 token,或者以掩码预测(Mask-Prediction)的方式并行地预测音频 token,逐步生成完整音频。
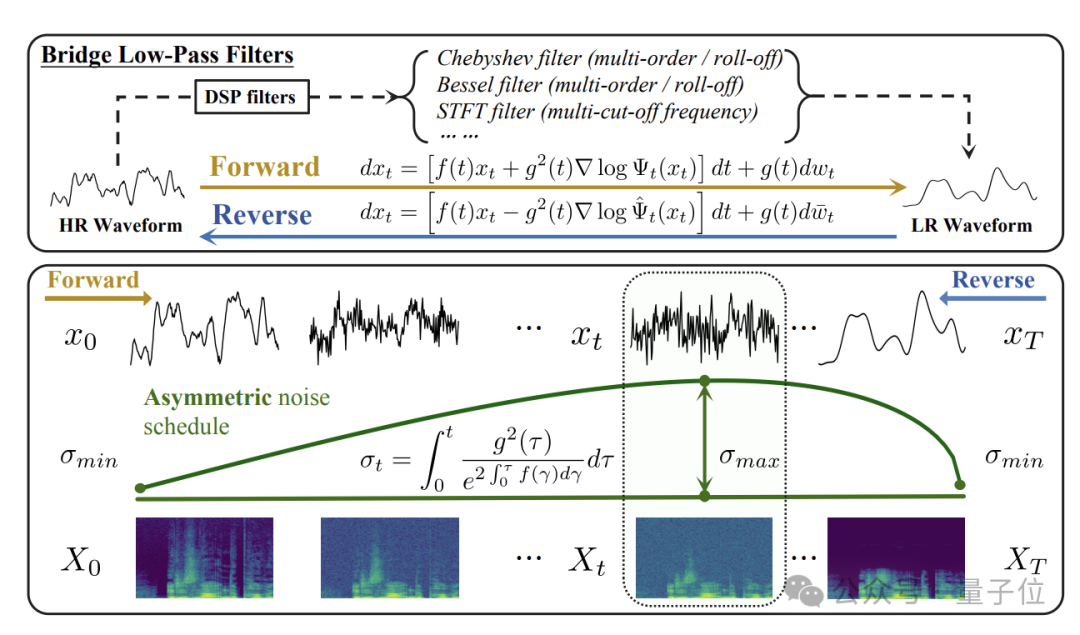
在这一背景下,清华大学与生数科技(Shengshu AI)团队围绕桥类生成模型与音频超分任务展开系统研究,先后在语音领域顶级会议ICASSP 2025和机器学习顶级会议NeurIPS 2025发表了两项连续成果:
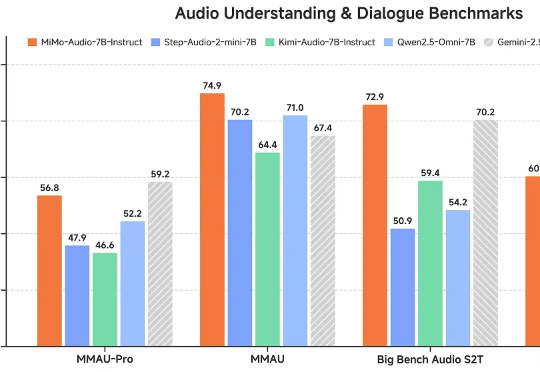
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。

智东西9月15日报道,今天,阿里巴巴通义实验室推出了FunAudio-ASR端到端语音识别大模型。这款模型通过创新的Context模块,针对性优化了“幻觉”、“串语种”等关键问题,在高噪声的场景下,幻觉率从78.5%下降至10.7%,下降幅度接近70%。