邢波再出手:上次「骂」完世界模型,这次轮到智能体了
邢波再出手:上次「骂」完世界模型,这次轮到智能体了去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。
来自主题: AI技术研报
6755 点击 2026-07-01 15:43
 搜索
搜索
去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。
前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。

我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。

说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。
经常切换使用CC、Codex、OpenClaw这类Agent的人会发现:同一个模型,放进不同系统里,表现可能完全不同。
就在刚刚,被Anthropic视为「太危险」的绝密大模型Mythos,竟在谷歌云悄悄解禁。CMU最新实测爆出,它在真实漏洞攻防中,断层碾压GPT-5.5。

就在今天,Carnegie Mellon University(CMU:卡内基梅隆大学)2026 年毕业典礼上,身价逼近 1860 亿美元的「皮衣刀客」黄仁勋站上演讲台,接过科学与技术荣誉博士学位。

来自USC、CMU、CUHK和OpenAI的全华阵容研究团队,提出了一种叫FD-loss的方法,把“算统计的样本池”和“算梯度的batch”彻底解耦。依靠数万张图像组成的大容量缓存队列或指数移动平均机制,稳定完成分布估算,仅针对当下小批量数据开展梯度回传。
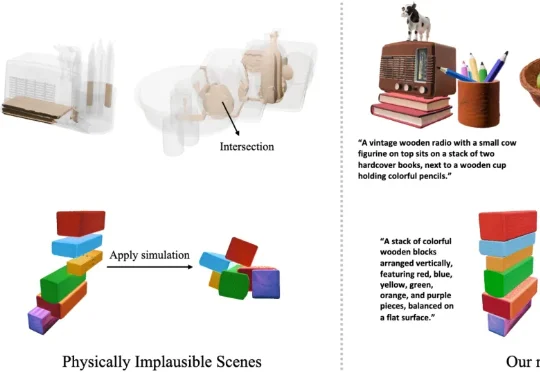
现在的 3D AIGC 已经可以很快生成场景,但离真正落地还有一段距离。很多场景看起来还行,一进物理模拟就会暴露问题,比如物体悬空、互相穿插,甚至还没碰就散。这些问题让它们很难直接用于游戏、XR 或机器人等实际场景。

AI科技评论独家获悉,卡内基梅隆⼤学机器⼈研究院(CMURI)博⼠后、悉尼⼤学(USYD)⻓聘助理教授WilliamZhi联合创办具⾝智能公司⸺ZenoAI(芝诺机器⼈),致⼒于打造通⽤全栈物理智能(Full-stackPhysicalAI),提供可靠的全⾝灵巧操作解决⽅案。