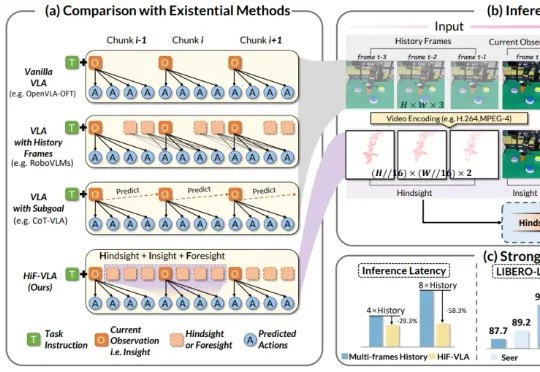
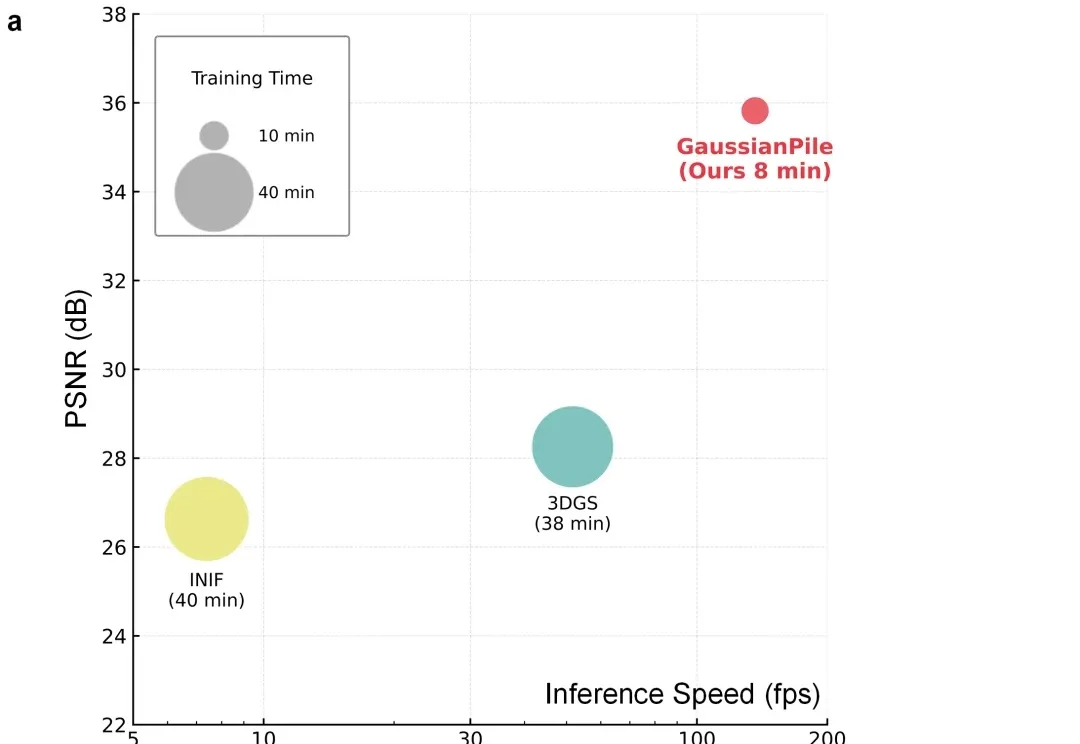
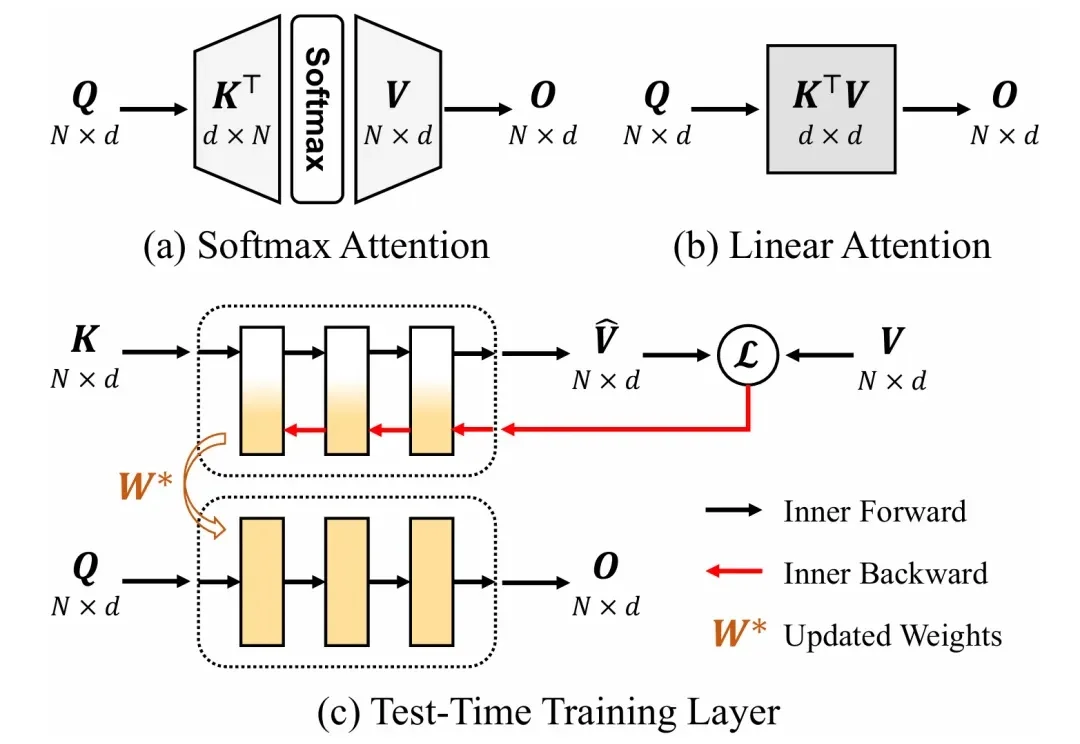
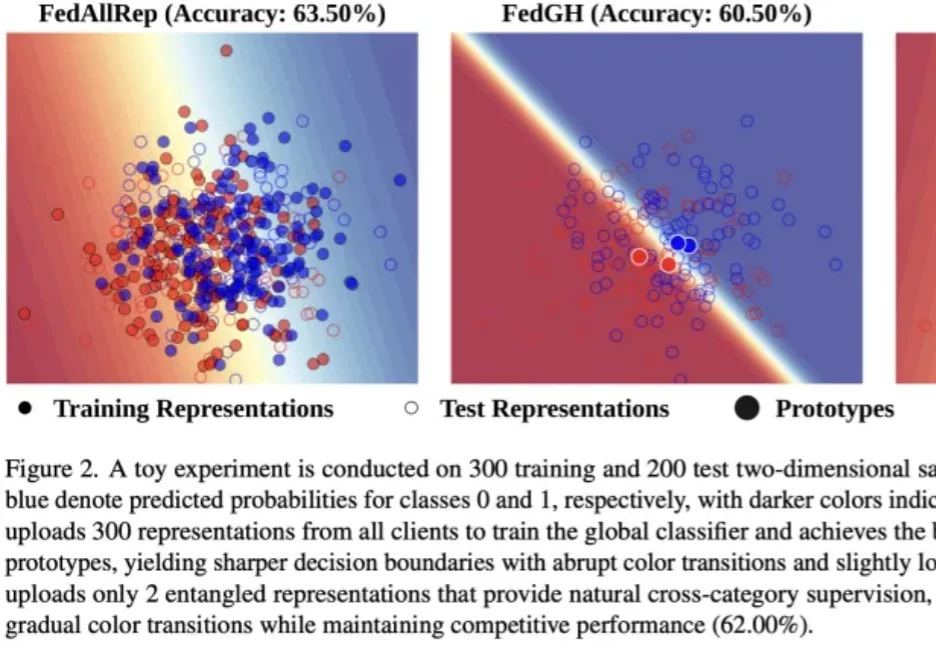
CVPR 2026|LLM会写3D视觉代码吗?清华联合智源用GeoCodeBench给出答案
CVPR 2026|LLM会写3D视觉代码吗?清华联合智源用GeoCodeBench给出答案近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,
来自主题: AI技术研报
9834 点击 2026-06-07 10:54