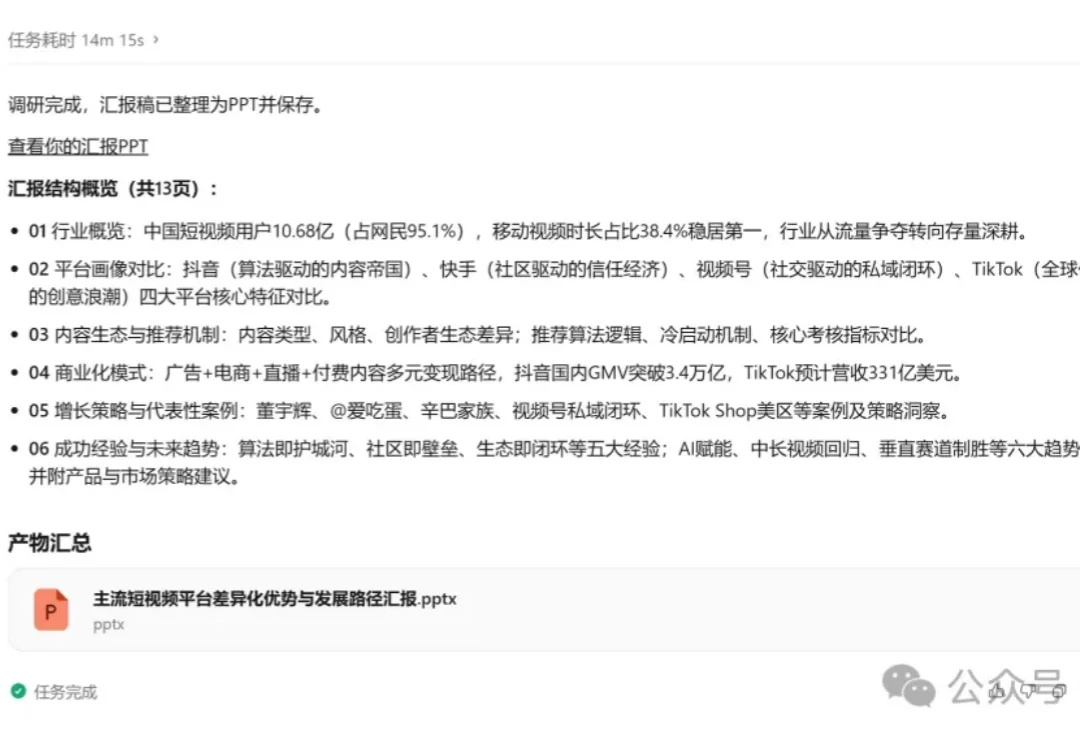
传美团全面限制团队使用豆包,此前还曾限用阿里千问
传美团全面限制团队使用豆包,此前还曾限用阿里千问7月2日,据大厂日爆消息,美团内部开始限制使用豆包大模型。消息称,美团向所有涉及到豆包大模型的业务部门下发通知,要求自查并规划迁移至LongCat、DeepSeek等模型,若无法迁移,需单独走审批流程。对此消息,截至发稿,美团暂无官方回应。据媒体报道,这并非美团首次收紧外部大模型的使用。今年4月,美团对内部大模型使用做出调整,不再推荐业务使用阿里云提供的Qwen模型。若业务仍需使用,需上报审批。
来自主题: AI资讯
9301 点击 2026-07-03 10:17