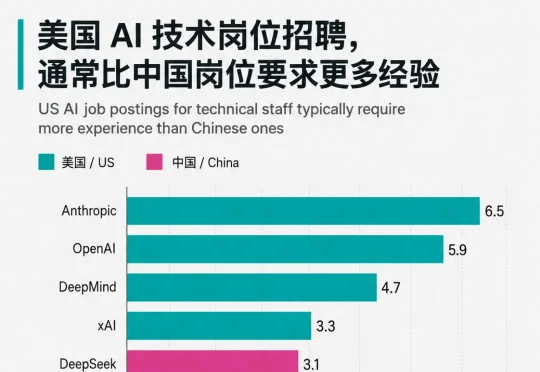
扒开1604份招聘,DeepSeek们最狠的大招藏在招人里
扒开1604份招聘,DeepSeek们最狠的大招藏在招人里同样是进顶尖 AI 公司当工程师,在中国你只要 1.6 年经验,在美国却得熬到 5.5 年。换句话说,一个中国应届生刚拿到毕业证,就可能坐在 DeepSeek 的工位上调大模型;而他的美国同行还得在别的公司再「实习」四年,才够格投一份前沿 AI 实验室的简历。
来自主题: AI资讯
7903 点击 2026-06-27 12:26
 搜索
搜索
同样是进顶尖 AI 公司当工程师,在中国你只要 1.6 年经验,在美国却得熬到 5.5 年。换句话说,一个中国应届生刚拿到毕业证,就可能坐在 DeepSeek 的工位上调大模型;而他的美国同行还得在别的公司再「实习」四年,才够格投一份前沿 AI 实验室的简历。

来自至知创新研究院(IQuest Research)、中国人民大学高瓴人工智能学院、KAUST等机构的研究团队提出了FORT,一个面向Deep Search Agent的shortcut-resistant training-data synthesis framework。

当全球具身智能行业还在争论技术路线时,一家中国公司已经率先定义并跑通了自己的答案。深度机智提出的「人类学习」路线——以人类数据为起点、动作建模为中心、机器人为 AI 而生——正在被英伟达、Physical Intelligence 等海外头部机构沿同一方向跟进。
刚刚才发现,那堪称DeepMind「推理之王」的男人——周登勇(Denny Zhou),早已离开了谷歌。现在的东家是Meta,在MSL担任研究科学家。整个过程极其低调。没有长篇大论的告别信,没有Meta的高调官宣,如果不是LinkedIn上的职位信息悄悄更新,外界甚至不知道这位大牛已经易主。

大模型浪潮席卷全球数年,技术形态持续迭代,也开始从办公、编程领域,深度渗透到科研这一核心赛道。从中科大夯实数理根基,到哈佛、MIT 完成联合培养,青年学者陈勇超横跨力学、机器人、自然语言处理、大模型等多个领域,完整亲历 AI 一轮轮技术变革。

当大模型公司还在竞争更长的上下文窗口、更强的推理能力和更复杂的 Agent 工作流时,一家名为 Engram 的新公司选择押注另一个问题:AI 能不能像人一样,持续从每天接触到的资料、对话和经验中学习?
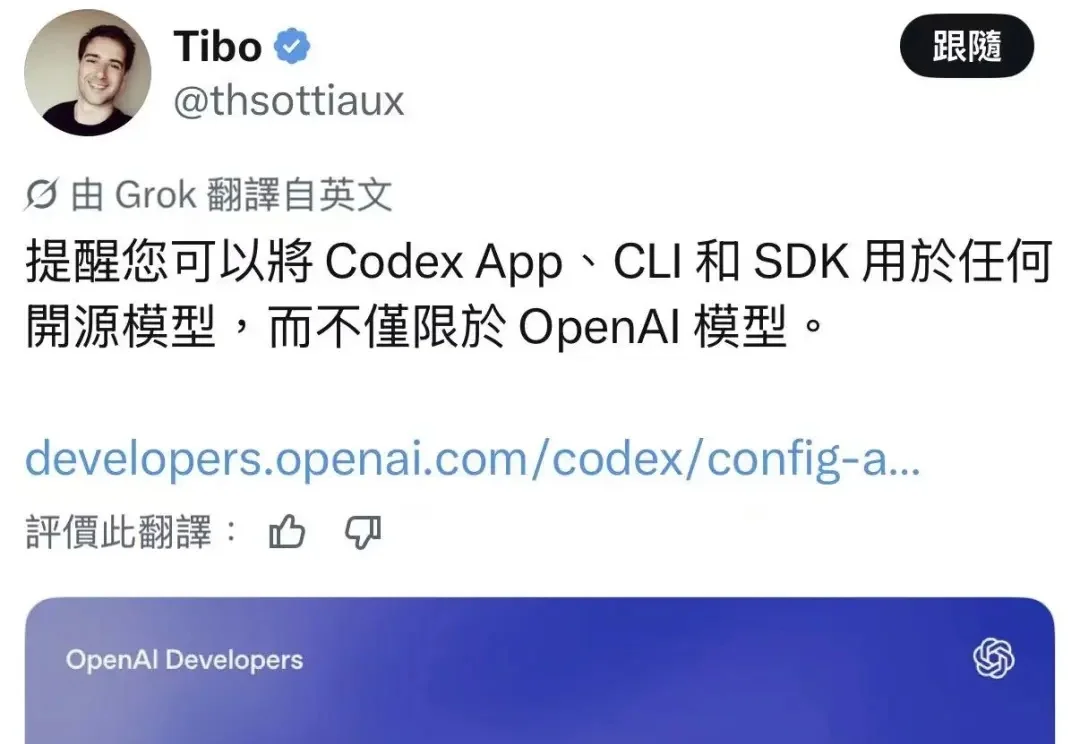
6月17日,X 上 OpenAI Codex 团队负责人 Tibo(@thsottiaux)发了一条推文,提醒大家 Codex App、CLI 和 SDK 现在可以接任何开源模型,不只限于 OpenAI 自己的模型。

Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。

好你个微软,当起大模型“倒爷”来了?!
最新开源的Unlimited OCR,总参数3B,实际激活仅500M——放在大模型时代几乎是个零头。但就是这个小到离谱的模型,在OmniDocBench v1.5上拿下93.23%的综合分,v1.6更是达到93.92%,直接刷新了端到端SOTA。