
全球最大游戏博主「偷师」DeepSeek,爆改国产大模型干翻 ChatGPT
全球最大游戏博主「偷师」DeepSeek,爆改国产大模型干翻 ChatGPT全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。
来自主题: AI资讯
9155 点击 2026-02-28 15:34
 搜索
搜索
全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。

这篇文章就想从更高层的角度抽丝剥茧:OpenClaw到底做对了什么,为什么是它火,以及这跟我们有什么关系。我有一个暴论:OpenClaw火的原因,和去年这个时候DeepSeek火的原因,是高度类似的。
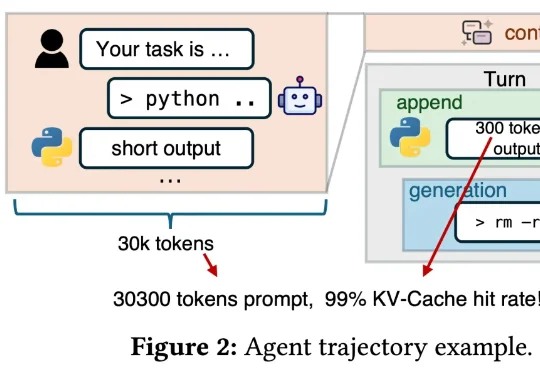
「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。

基于Gemini 3 Deep Think的谷歌数学智能体Aletheia在更难的挑战赛FirstProof中拿下的最佳成绩。在公布的完整成绩单中,10道题Aletheia全程0人工参与解出6道,其中5题专家全票通过,还有一题拿到了5/7的通过率。

最近,炸裂消息一个接一个。首先,DeepSeek V4将在一周内上线。第二,它跳过英伟达,把访问权限首先给了某国内芯片厂商。另外,Anthropic因为蒸馏事件,也被群嘲了。

科技账号 Legit 率先披露,V4 的轻量版本代号为「sealion-lite(海狮轻量版)」,目前已在至少一家推理服务商处展开内测,相关方均签署了严格的保密协议。

DeepSeek员工节后一上班,美国AI圈又要抖三抖了(doge)。就从十几个小时前开始,DeepSeek的GitHub仓库突然一阵猛更新,Merge了一堆PR:维护者主要是mowentian——DeepSeekMoE等论文的署名作者之一Huang Panpan。他这一干活不要紧,大洋彼岸“V4来了???”的紧张神经,又被瞬间挑了起来。

创始人回炉敲代码、重整DeepMind军团、每周工作100小时……Google DeepMind掌舵人Demis Hassabis亲述过去一年谷歌与OpenAI的战事,他表示谷歌已找回状态,AGI或在2030年降临,人类将进入「后稀缺」时代。

今天,美国大模型独角兽Anthropic连续发布多则推文、博客,指控DeepSeek、月之暗面和MiniMax三家中国AI实验室,正对Claude进行“工业级规模的蒸馏攻击”。
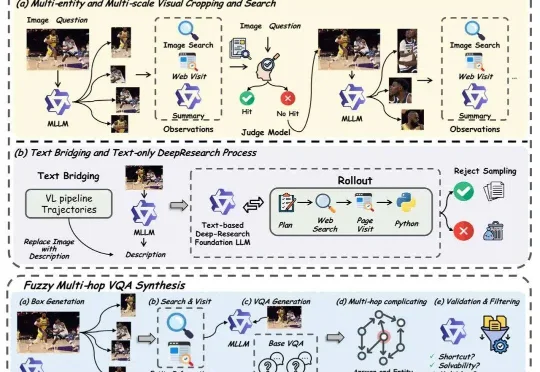
DeepResearch 的价值在于把「查资料」变成「做研究」:不是搜到一条就回答,而是会连续多轮地提出问题、去不同地方找证据、互相对照核实、再把信息整理成结构清晰的结论。这样做能显著降低「凭感觉瞎编