
效率拉满!DeepSeek一键提效核对Excel表格,真的绝了
效率拉满!DeepSeek一键提效核对Excel表格,真的绝了“蔚公子,DeepSeek核对两个Excel表格怎么做啊?”小伙伴上周问我。
来自主题: AI资讯
11384 点击 2025-06-17 10:33
 搜索
搜索
“蔚公子,DeepSeek核对两个Excel表格怎么做啊?”小伙伴上周问我。
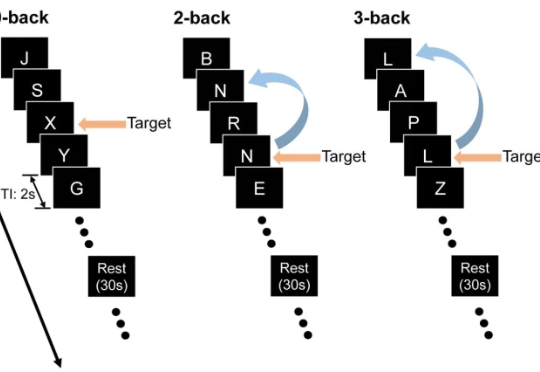
最近,来自约翰・霍普金斯大学与中国人民大学的团队设计了三套实验,专门把关键线索藏在上下文之外,逼模型「凭记忆」作答,从而检验它们是否真的在脑海里保留了信息。

Era of Experience 这篇文章中提到:如果要实现 AGI, 构建能完成复杂任务的通用 agent,必须借助“经验”这一媒介,这里的“经验”就是指强化学习过程中模型和 agent 积累的、人类数据集中不存在的高质量数据。

仅用不到1200行代码,实现最小化且完全可读的vLLM!DeepSeek研究员俞星凯搞了个开源项目引得大伙拍手叫绝。项目名为Nano-vLLM(纳米级-vLLM),有三大特点:快速离线推理:推理速度可与vLLM相媲美
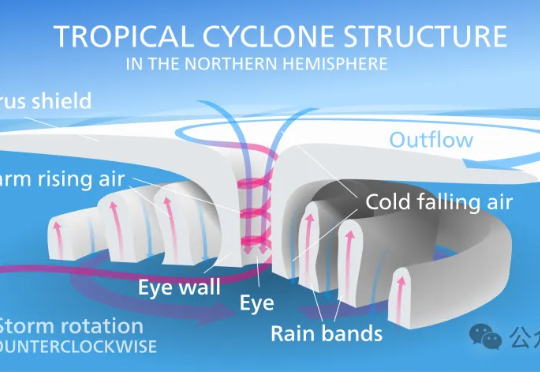
昨天,谷歌DeepMind与谷歌研究团队正式推出交互式气象平台Weather Lab,用于共享人工智能天气模型。在热带气旋路径预测方面,谷歌这次的新模型刷新SOTA,是首个在性能上明确超越主流物理模型的AI预测模型。

4月份,李飞飞教授领先编制的《2025年人工智能指数报告》提供的数据显示,2024年全年具有特殊影响力的模型(Notable AI models)当中,排名前5的几乎都来自美国、中国的科技巨头。
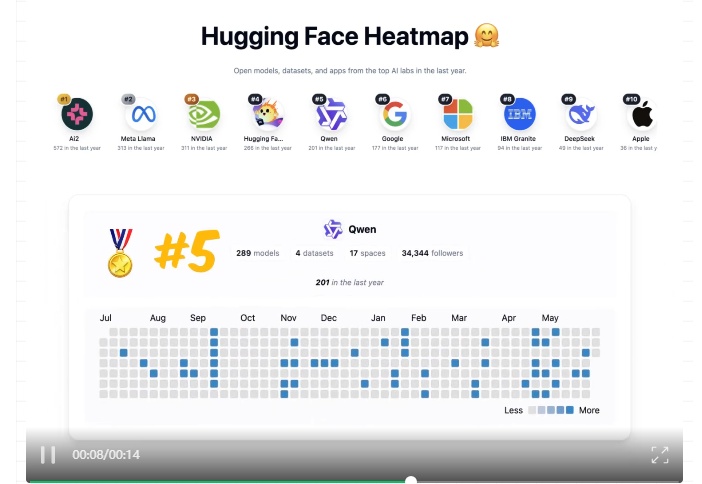
全球知名开源AI平台Hugging Face近日发布开放权重模型贡献榜,中国团队Qwen和DeepSeek成功入围前15名,彰显了中国在全球开源AI领域的技术实力与影响力。该榜单表彰为开源社区提供高质量模型权重的团队,其模型广泛应用于学术与产业创新。

谷歌DeepMind重磅出击,开源首个形式化数学猜想库,获陶哲轩力挺!从解析数论的兰道猜想开始,这个开源项目将为AI破解数学难题的未来铺路。

作者介绍: 本文作者来自通义实验室 RAG 团队,致力于面向下一代 RAG 技术进行基础研究。该团队 WebWalker 工作近期也被 ACL 2025 main conference 录用。

小扎亲手挖人,很疯狂。