DeepSeek识图模式全量上线,却认不出自家老板梁文锋
DeepSeek识图模式全量上线,却认不出自家老板梁文锋端午节前,DeepSeek 不出所料又有了新动作:官方平台全量推送了识图模式,手机端 App 也发布了更新,打开就能看到。此前,已经有不少网友体验过这个功能,但当时它还处在小范围的灰度测试阶段,只有部分用户能够在官方 App 或网页版里看到。但是今天下午,很多人都表示自己也能用了。
来自主题: AI资讯
8911 点击 2026-06-18 21:57
 搜索
搜索
端午节前,DeepSeek 不出所料又有了新动作:官方平台全量推送了识图模式,手机端 App 也发布了更新,打开就能看到。此前,已经有不少网友体验过这个功能,但当时它还处在小范围的灰度测试阶段,只有部分用户能够在官方 App 或网页版里看到。但是今天下午,很多人都表示自己也能用了。

关于 DeepSeek 的融资信息,已经漫天遍野。已知信息,「elsewhere」不再赘述。以下,是我们了解到的一些未被展示过的故事或情节。先说那场投资人会议,也就是那个口耳相传的“四小时会议”。
当地时间6月16日,微软宣布将企业AI工具Copilot Cowork转向按使用量计费。另据外媒Axios报道,在扩大该工具访问范围的同时,Copilot Cowork近期考虑引入由微软托管的DeepSeek模型,作为更低成本的模型选项。
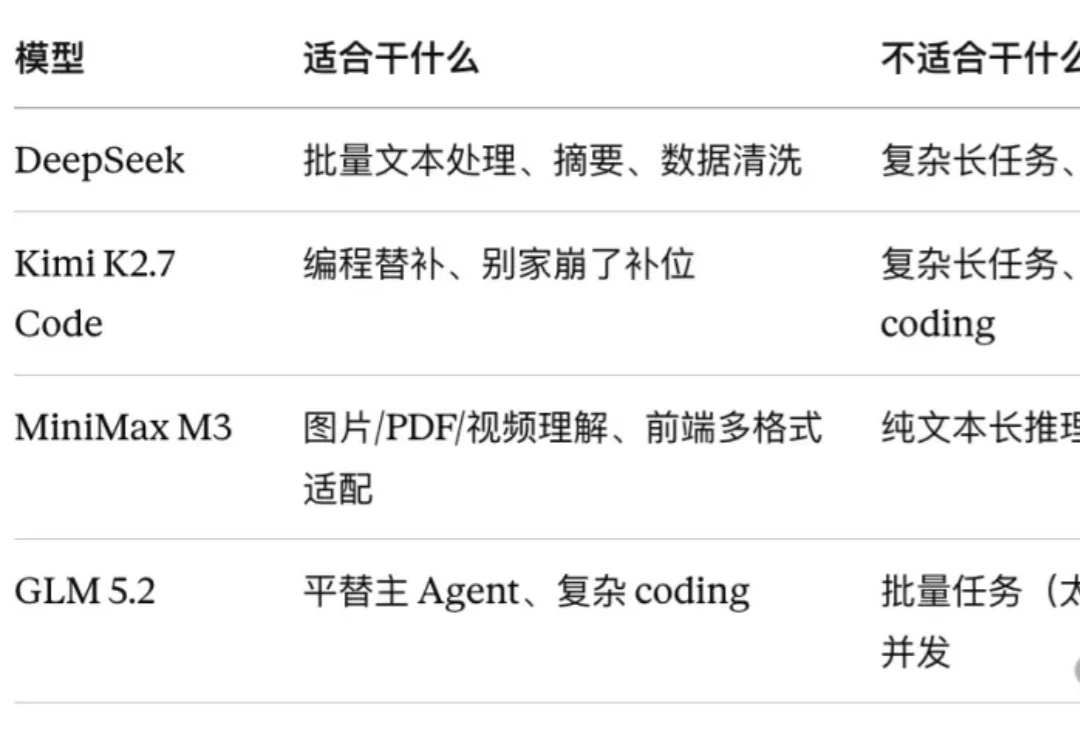
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。
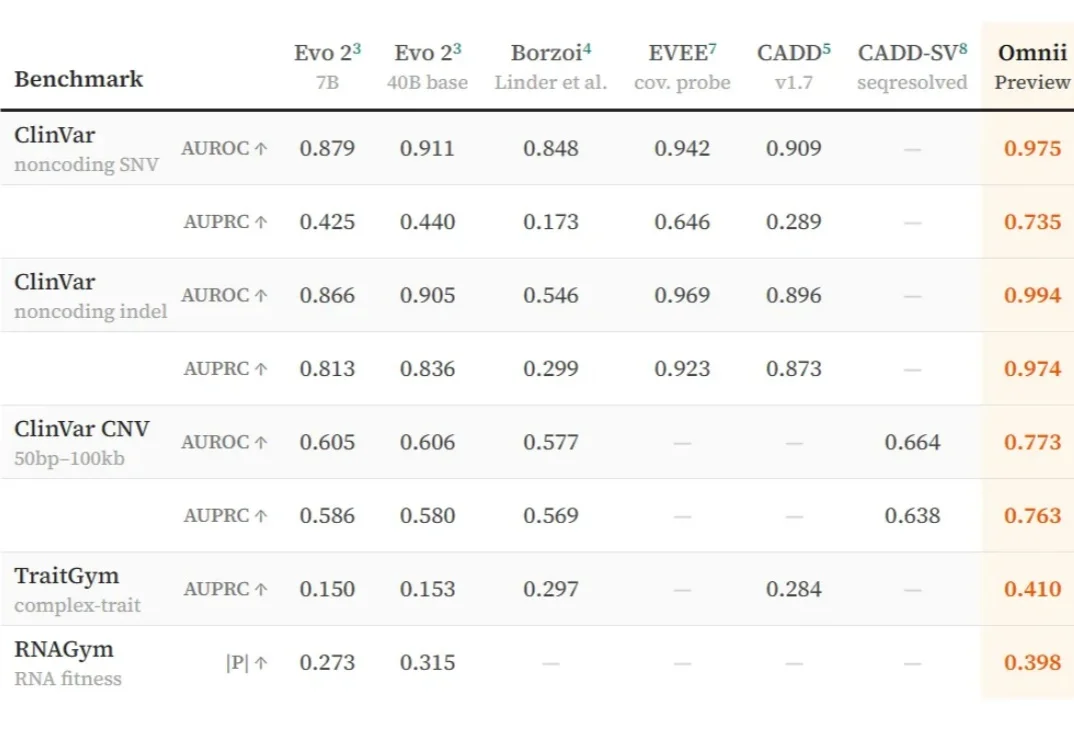
最大生物学AI模型Evo2的幕后团队,要把所有生物信息整合到一套AI里!
《科创板日报》记者从多家投资机构获悉,DeepSeek首轮融资目前或已敲定,其募资总额超500亿元人民币(约合74亿美元),投后估值突破500亿美元(约合3380亿元人民币)。这是中国AI行业迄今规模最大的单轮融资。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。

刚刚,据外媒The Information援引两名知情人士报道,DeepSeek近期已完成成立以来的首轮外部融资,募资总额超500亿元人民币(折合74亿美元),本轮融资采用特殊交易架构。这是中国AI行业迄今规模最大的单轮融资。
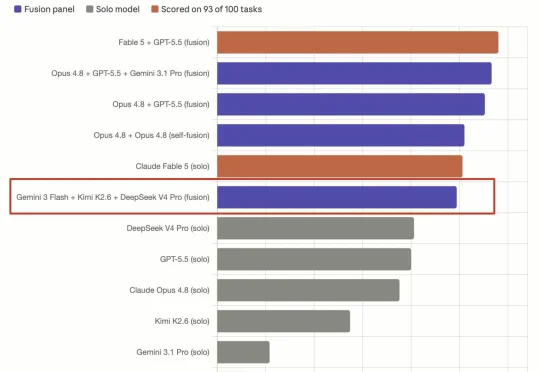
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。

“你将有机会参与从MW(兆瓦)到GW(吉瓦)级基础设施的规划与建设。”