
刚刚,Mind Lab开源V1系列模型Preview,749B参数,专为Agent 后训练
刚刚,Mind Lab开源V1系列模型Preview,749B参数,专为Agent 后训练过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。
来自主题: AI技术研报
5934 点击 2026-06-08 15:29
 搜索
搜索
过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

致力于成为金融界“DeepSeek”。金融垂域大模型公司Grace Investment Machine(简称GIM)宣布一连完成过亿元天使轮和天使+轮融资。成立于2025年7月,GIM正在做一件事:为金融行业打造一个垂直领域的DeepSeek——专为投资决策而生的推理大模型。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

Codex 又又又大更新,前一天负责人还在说,是不是要改名 ChadGPT,网友在下面评论说,不如直接将 ChatGPT 重新命名为 Codex。

刚刚,据路透社报道,多位知情人士透露,DeepSeek即将完成成立以来的首轮对外融资,拟募集约500亿元(约合74亿美元),投资方包括腾讯和电池制造商宁德时代。知情人士说,本轮融资完成后,DeepSeek的投后估值将达到3500亿至4000亿元

“AI新物种”企业级Token生产平台TokenBox™。

紧跟DeepSeek价格战,小米掏出技术底牌!
Hunter Bown 没想到,自己会在差点因职业转型陷入困境后,被一个开源项目重新推回牌桌。
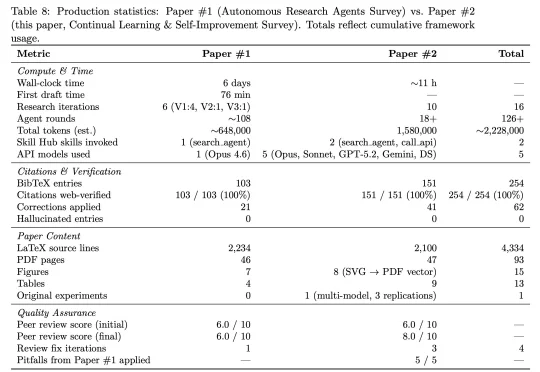
DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。
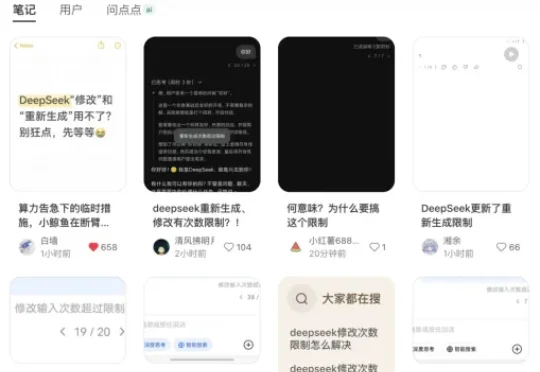
5月29日下午,不少网友发现,DeepSeek重新生成、修改有次数限制了。连续修改或重新生成几次后,页面会提示达到上限。有网友反馈,在普通对话中,重新生成3到6次后就会达到上限;而在专家模式下,可能只有3次机会。修改输入次数上限一般是6次。