
强化学习没作用?人大DelTA精准识别关键token,推理正确率大幅上升
强化学习没作用?人大DelTA精准识别关键token,推理正确率大幅上升做大模型RL微调,你是不是也踩过这些坑?
来自主题: AI技术研报
9767 点击 2026-07-03 09:49
 搜索
搜索
做大模型RL微调,你是不是也踩过这些坑?
德塔智能试图为双足人形机器人构建能够理解空间、协调全身并完成真实任务的基础模型。 原生人形机器人基础模型公司德塔智能(Delta Intelligence)近日已连续完成种子+轮、天使轮及天使+轮融资。

近日,北京德塔源创智能科技有限公司(简称:德塔智能 Delta Intelligence)宣布完成三轮超亿元融资,由高瓴创投等加注,并引入乐聚、智元、星海图等头部主机厂商战略入局。

UC Berkeley、UW、AI2 等机构联合团队最新工作提出:在恰当的训练范式下,强化学习(RL)不仅能「打磨」已有能力,更能逼出「全新算法」级的推理模式。他们构建了一个专门验证这一命题的测试框架 DELTA,并观察到从「零奖励」到接近100%突破式跃迁的「RL grokking」现象。
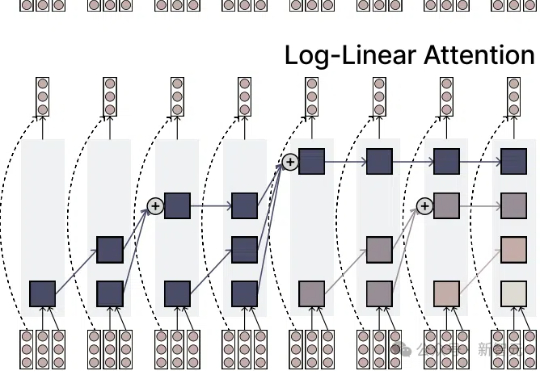
注意力机制的「平方枷锁」,再次被撬开!一招Fenwick树分段,用掩码矩阵,让注意力焕发对数级效率。更厉害的是,它无缝对接线性注意力家族,Mamba-2、DeltaNet 全员提速,跑分全面开花。长序列处理迈入log时代!
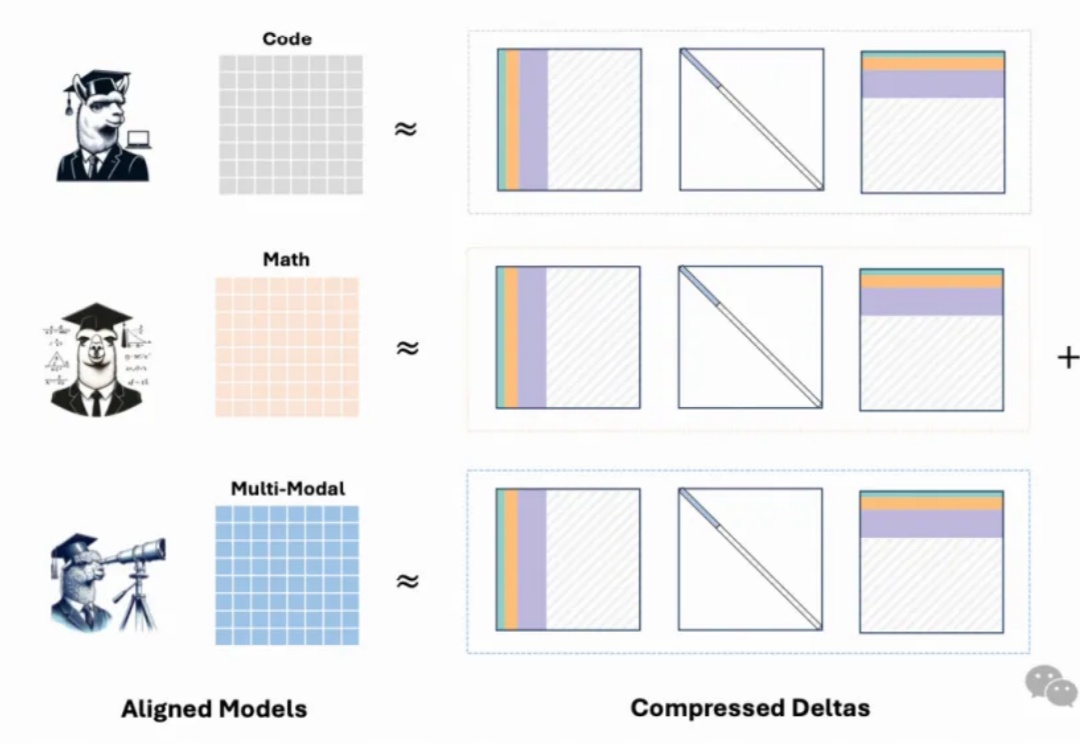
最新模型增量压缩技术,一个80G的A100 GPU能够轻松加载多达50个7B模型,节省显存约8倍,同时模型性能几乎与压缩前的微调模型相当。