生物学的EDA时刻来了!
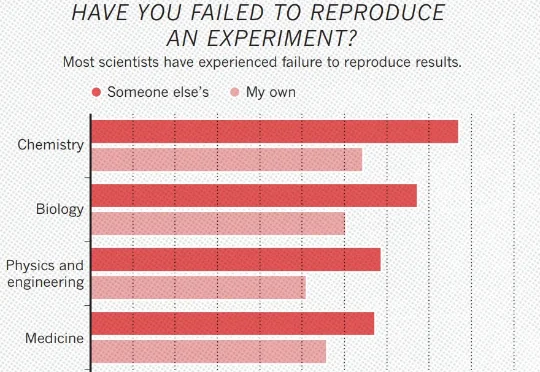
生物学的EDA时刻来了!2025 年 12 月,OpenAI 联合多家实验室发布了一份湿实验室报告。报告给出了一个令人振奋的核心结论:GPT-5 通过多轮迭代,自主优化了一个分子克隆方案,效率提升了 79 倍。它提出了一种此前从未被报道过的酶组合——RecA 重组酶与噬菌体 T4 的 gp32 蛋白协同作用,让 DNA 末端配对效率大幅跃升。
来自主题: AI资讯
9070 点击 2026-06-28 10:55
 搜索
搜索
2025 年 12 月,OpenAI 联合多家实验室发布了一份湿实验室报告。报告给出了一个令人振奋的核心结论:GPT-5 通过多轮迭代,自主优化了一个分子克隆方案,效率提升了 79 倍。它提出了一种此前从未被报道过的酶组合——RecA 重组酶与噬菌体 T4 的 gp32 蛋白协同作用,让 DNA 末端配对效率大幅跃升。
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。

180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。

当 AI 智能体真正开始干活,它的每一次请求,都要经过一个你看不见的「中间人」。

昨晚,字节新模型Seedance 2.0 Mini深夜来袭,该模型主打性价比,侧重于提供更低的价格以及更快的生成速度。Seedance 2.0 Mini虽然定价更低,但保留了核心能力参考生成,用户可以通过融合提示词与最多12个多种模态的参考素材(包括6张图片、3段音频、3段视频)来锁定人物一致性、精细化控制运动轨迹、卡准剧情节奏。
《读佳》获知,腾讯“TDream”带着“创造可玩的世界”的定位低调开启内测。“说句肺腑之言,这个产品,我觉得打破了我对腾讯的认知。”一位用户看了TDream生成《山月》视频作品后,十分感慨。他觉得,这个产品可以和字节的Seedance2.0、HappyHorse掰掰手腕。

视频生成,早已不止于视觉。

如果模型能力断层领先,那么买单的人自然会出现。

对于 Seedance 视频生成模型,大家都不陌生了。
近日,字节旗下AI视频创作工具小云雀的短剧Agent正式更新到2.0版本。自Seedance 2.0这一视频生成模型横空出世以来,小云雀一直是其原生支持的平台。由于整体使用门槛相对较低,小云雀也逐渐积累起一批AI短剧和AI短片创作者。