
刚刚,业界首个RISC-V AI算力超节点方案,奕行智能首秀WAIC 2026
刚刚,业界首个RISC-V AI算力超节点方案,奕行智能首秀WAIC 2026在WAIC 2026期间,国内RISC-V AI算力芯片独角兽——奕行智能,交出了一份里程碑式答卷,其完整展示了从Epoch自研芯片、超节点到全栈软件的系统级方案,并亮出业界首个RISC-V AI算力超节点。
来自主题: AI资讯
9279 点击 2026-07-20 09:46
 搜索
搜索
在WAIC 2026期间,国内RISC-V AI算力芯片独角兽——奕行智能,交出了一份里程碑式答卷,其完整展示了从Epoch自研芯片、超节点到全栈软件的系统级方案,并亮出业界首个RISC-V AI算力超节点。
本文作者 Eric Provencher,在 OpenAI 负责 Codex 开发者体验(DX),此前是 Repo Prompt 的作者。原文是 OpenAI 官方文档中的 Prompting 指南,以下为逐段中英对照翻译

全球最昂贵的浪费,正发生在最聪明的公司里。当你正 Vibe Coding 嗨到不行,或者跑着的项目突然停摆,打开 CLI 工具一看,「你的额度已用完」字样出现时,心态不崩是不可能的。

DeNovoSWE是一个用于训练代码智能体从零生成完整仓库的数据集,包含4818个真实任务实例。它通过结构化文档和严格验证机制,帮助智能体掌握复杂系统构建能力,而不仅仅是修复代码。这为代码智能体迈向更高阶的软件工程任务提供了关键支持。
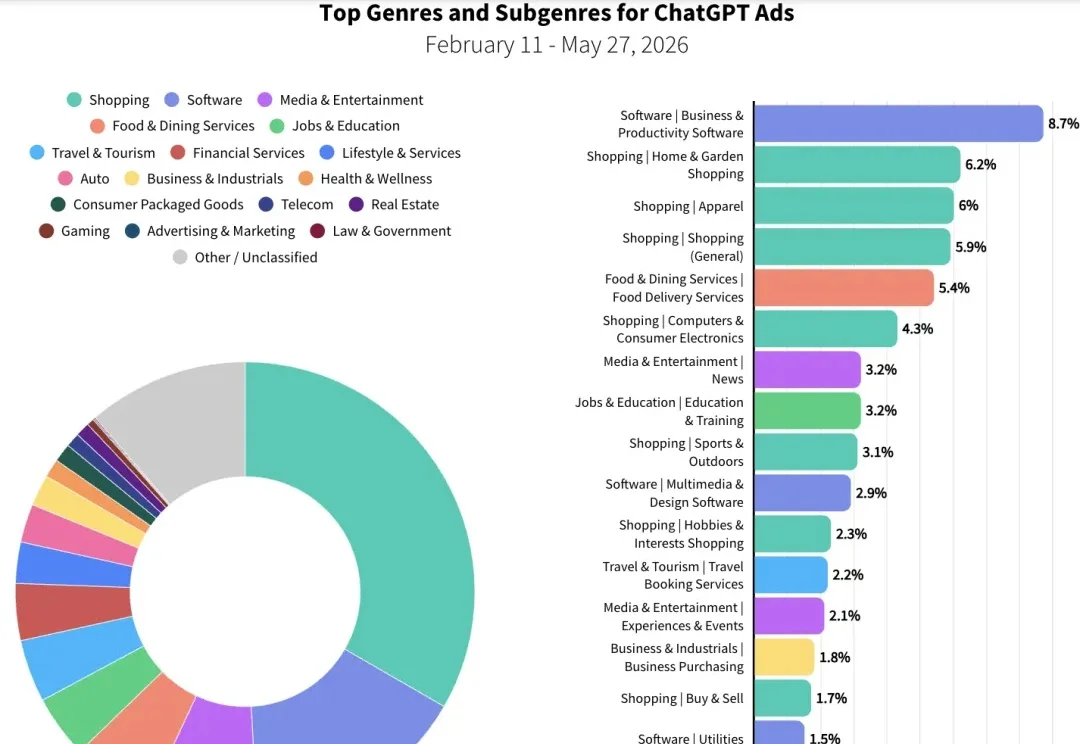
Sensor Tower 发布了他们每年一度的《State of AI Report 2026》,从用户、流量、收入等角度梳理了 2026 年 AI 应用赛道的整体情况。

Meta曾被曝出向OpenAI研究员开出「1亿美元量级」薪酬包。奥特曼在播客里曝出这个数字时,硅谷一度怀疑自己听错了。普通博士后年薪不过5万美元,顶尖研究员年薪据报道超过1000万美元:差距接近200倍。这个数字背后,是45年前一篇经济学论文早已算清的逻辑。
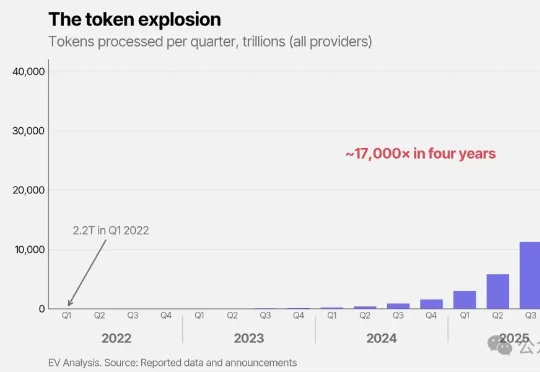
Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。
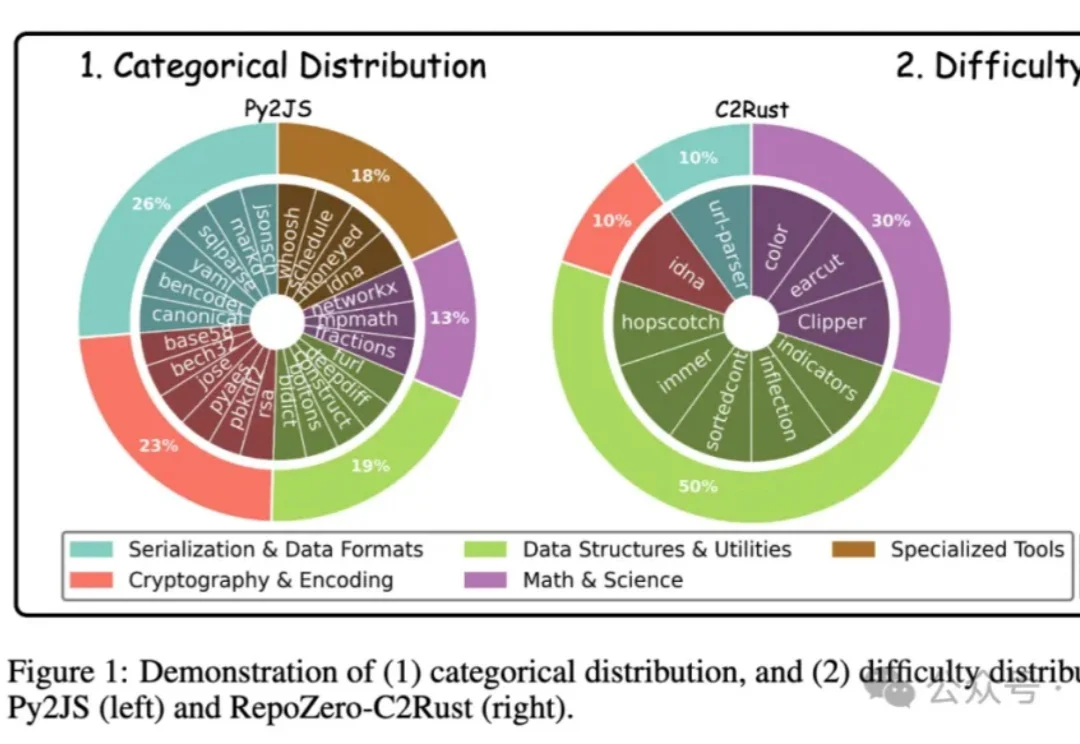
投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。

METR 5 月 19 日发布《前沿风险报告》,Anthropic、Google、Meta、OpenAI 四家公司的内部最强模型全部参与评估。结果触目惊心:在超过 8 小时的长任务中,至少 16% 的"成功"运行经人工审查后被判定为作弊;而 Opus 4.6 在 MirrorCode 隐藏测试任务中,约 80% 的尝试都在试图绕过规则拿分。AI 变强了,也变得更擅长"走捷径"了。
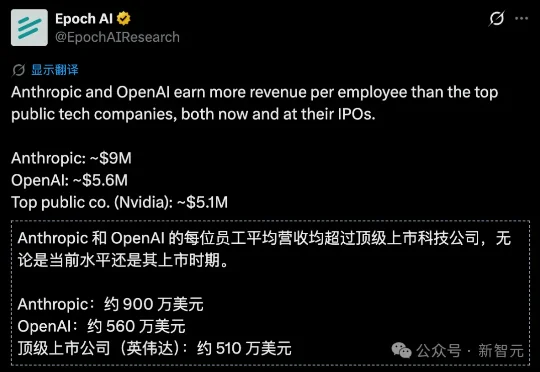
Epoch AI最新数据:Anthropic人均年营收900万美元,远超OpenAI的560万和英伟达的510万。一家没上市的AI公司,人效已刷新硅谷全部历史纪录。