
相机参数秒变图片!新模型打通理解生成壁垒,支持任意视角图像创作
相机参数秒变图片!新模型打通理解生成壁垒,支持任意视角图像创作能看懂相机参数,并且生成相应视角图片的多模态模型来了。
来自主题: AI技术研报
4901 点击 2025-10-28 13:57
 搜索
搜索
能看懂相机参数,并且生成相应视角图片的多模态模型来了。
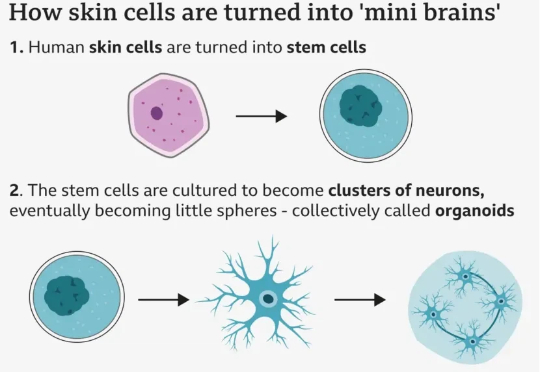
利用人类皮肤细胞也能造出 AI 处理器?一家名为 FinalSpark 的瑞士公司,认为生物计算是 AI 的下一次进化飞跃。该公司开发了一款生物处理器,这些处理器利用人体神经元来代替传统的硅基芯片,使用由人类皮肤细胞培育出的类脑器官作为计算单元。
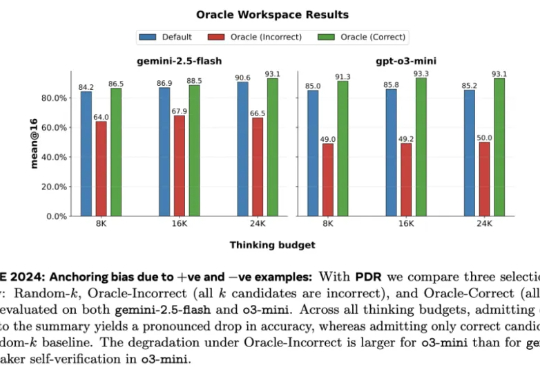
Meta 超级智能实验室、伦敦大学学院、Mila、Anthropic 等机构的研究者进行了探索。从抽象层面来看,他们将 LLM 视为其「思维」的改进操作符,实现一系列可能的策略。研究者探究了一种推理方法家族 —— 并行 - 蒸馏 - 精炼(Parallel-Distill-Refine, PDR),
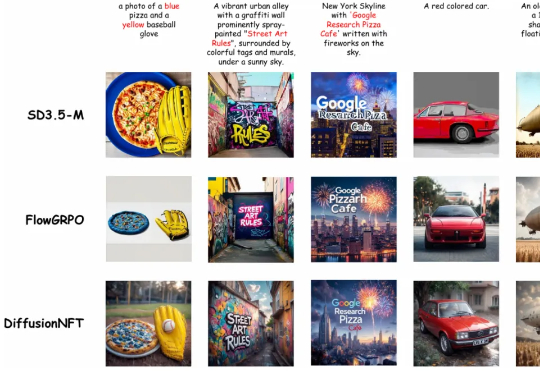
清华大学朱军教授团队,NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 ——Diffusion Negative-aware FineTuning (DiffusionNFT)。该方法首次突破现有 RL 对扩散模型的基本假设,直接在前向加噪过程(forward process)上进行优化

今天继续给大家带来「一页纸」讲透美股公司系列。对国内投资者而言,美股研究资料相对匮乏,导致认知大多停留在几家全球科技巨头,但其实美股存在大量的“隐形冠军”,都录得相当不错的收益。这是一个非常「有钱景」的方向,我会借助 AlphaEngine 的帮助,帮你跨越美股研究的信息鸿沟,每天挖掘一个潜在的美股财富密码。

2025 年 9 月,这个未来主义的问题进入了全球最高决策层的视野。美联储率先表态将研究 AI 与代币化支付,紧接着,SEC 前主席 Paul S. Atkins 在巴黎正式将其命名为「代理金融」(Agentic Finance)时代。

作为华为服务金融客户的窗口,华为数字金融军团不仅在全联接大会上回顾了过往案例,更重点推出了应对 AI 落地挑战的 FAB(FinAgent Booster)金融智能体加速器。帮助客户快速建立自己的 Agent 能力,缩短开发周期,让 AI 加速融入业务流程。
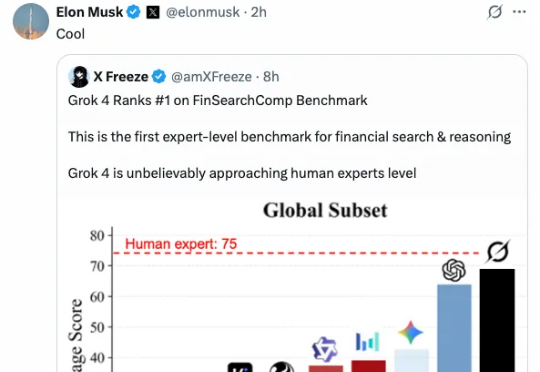
字节跳动Seed团队联合哥伦比亚大学商学院推出了FinSearchComp,这是首个完全开源的金融搜索与推理基准测试。该基准包含635个金融专家精心设计的问题,覆盖全球和大中华两个市场,并在多个主流模型产品上进行了全面评测。
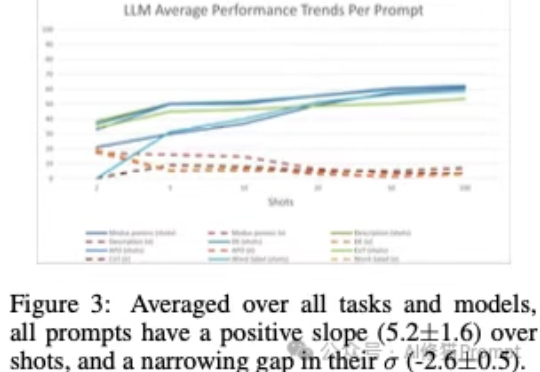
上下文学习”(In-Context Learning,ICL),是大模型不需要微调(fine-tuning),仅通过分析在提示词中给出的几个范例,就能解决当前任务的能力。您可能已经对这个场景再熟悉不过了:您在提示词里扔进去几个例子,然后,哇!大模型似乎瞬间就学会了一项新技能,表现得像个天才。

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。