GLM-5.3你来定!智谱唐杰全球征集意见,评论区清一色:视觉
GLM-5.3你来定!智谱唐杰全球征集意见,评论区清一色:视觉最近,清华教授、智谱灵魂人物唐杰聊得有点high。
来自主题: AI资讯
9258 点击 2026-06-30 15:42
 搜索
搜索
最近,清华教授、智谱灵魂人物唐杰聊得有点high。
这个周末,智谱没闲着。

Anthropic增加绿卡认证后,最开心是智谱,直接原地化身战狼,高呼「前沿智能属于所有人」,提前把专注Coding的GLM5.2发了。

昨夜,全球最大的 AI 开源社区 Hugging Face 官宣了一项前所未有的决定:自掏腰包为智谱 AI 最新开源的旗舰模型 GLM-5.2 提供长达 6 小时的全球免费算力支持。这是 Hugging Face 第一次真金白银为国产模型开这种 “专属 VIP 通道”,海外网友纷纷直呼这波 “倒贴” 好!

最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。

大家好,我是袋鼠帝。 如果你家的猫狗真的能说话,它们开口第一句会说什么?
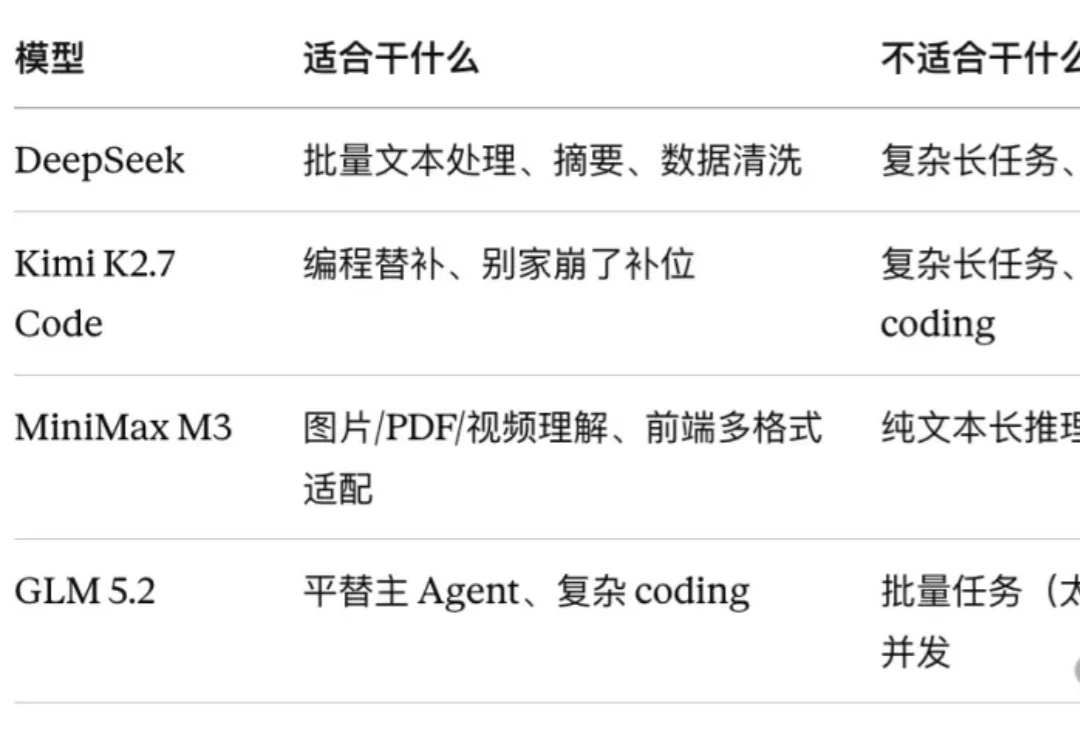
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。
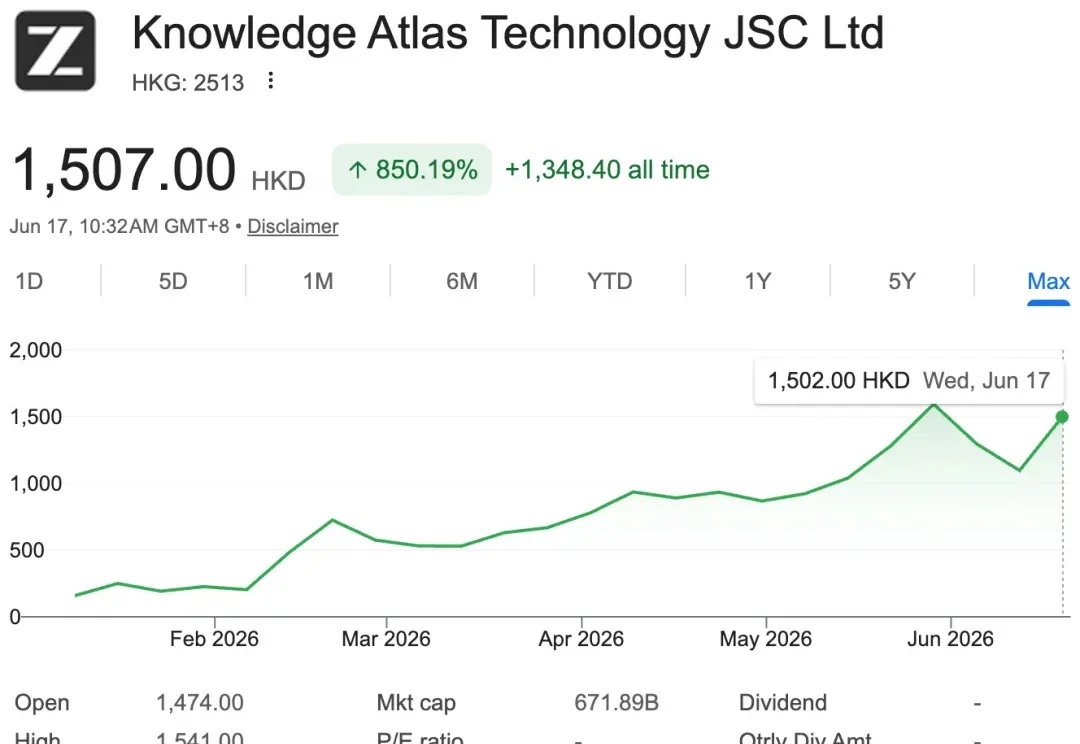
前几天 Fable 5 对海外用户关停的时候,智谱突然宣布向 GLM Coding Plan 全量用户开放了 GLM-5.2,并表示「前沿智能不应只属于少数人,也不应被少数规则随手收回。」

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。
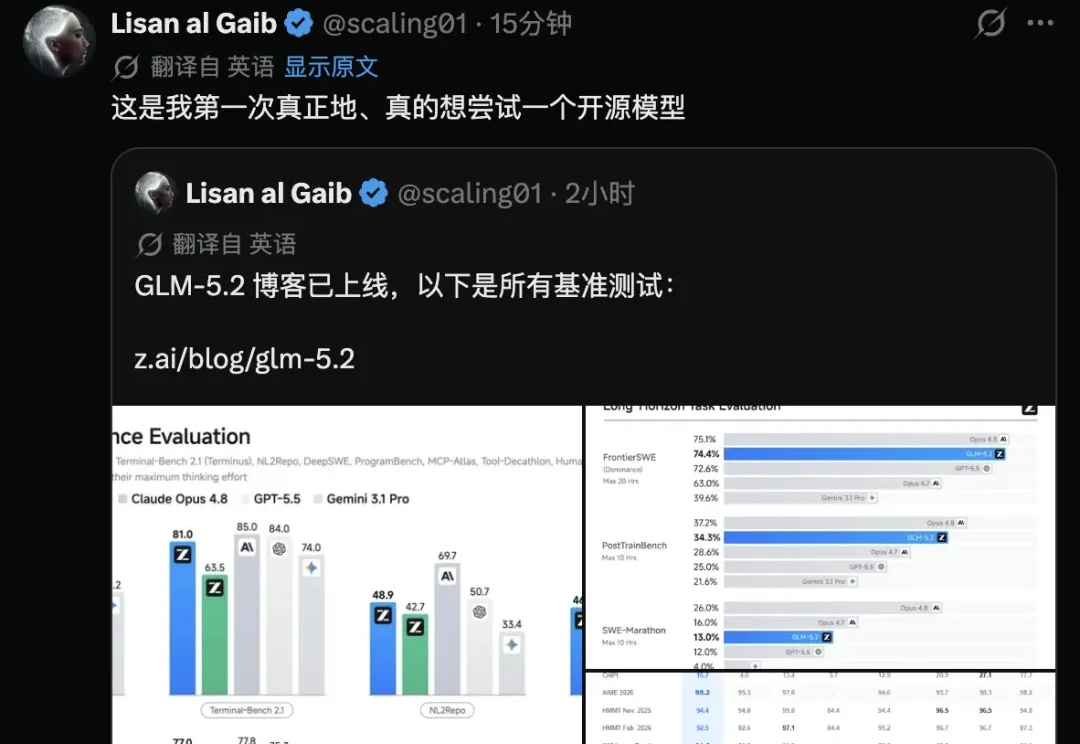
GLM-5.2 正式发布,震撼全网,主打长程任务能力,配合 1M token 上下文窗口,且完全开源(MIT 协议)。在相近的 token 消耗下,GLM-5.2 的能力大致介于 Opus 4.7 和 Opus 4.8 之间,参数仅为753B。