苹果再发论文:精准定位LLM幻觉,GPT-5、o3都办不到
苹果再发论文:精准定位LLM幻觉,GPT-5、o3都办不到论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。
来自主题: AI资讯
10303 点击 2025-10-07 22:11
 搜索
搜索
论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。

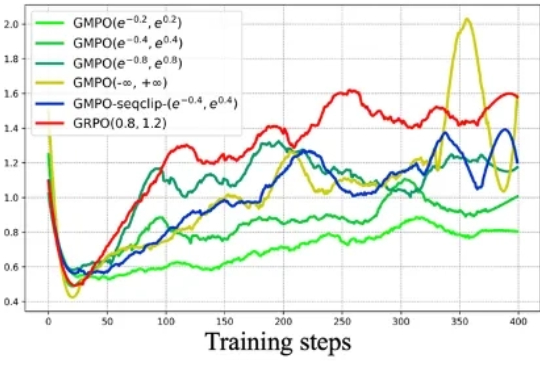
近期,北京大学与字节团队提出了名为 BranchGRPO 的新型树形强化学习方法。不同于顺序展开的 DanceGRPO,BranchGRPO 通过在扩散反演过程中引入分叉(branching)与剪枝(pruning),让多个轨迹共享前缀、在中间步骤分裂,并通过逐层奖励融合实现稠密反馈。
GRPO 就像一个树节点,从这里开始开枝散叶。
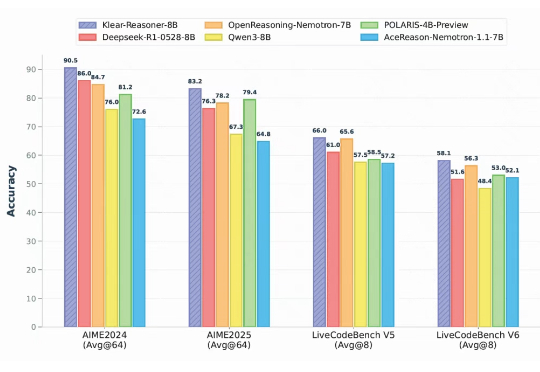
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
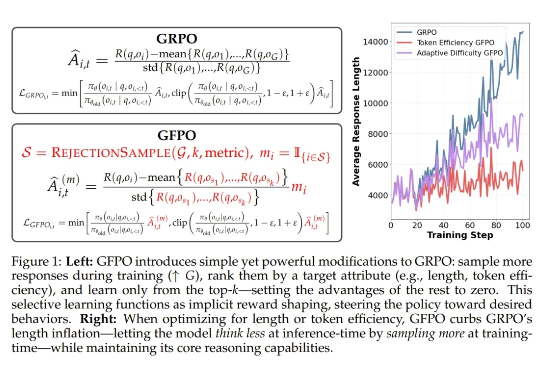
用过 DeepSeek-R1 等推理模型的人,大概都遇到过这种情况:一个稍微棘手的问题,模型像陷入沉思一样长篇大论地推下去,耗时耗算力,结果却未必靠谱。现在,我们或许有了解决方案。
近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。
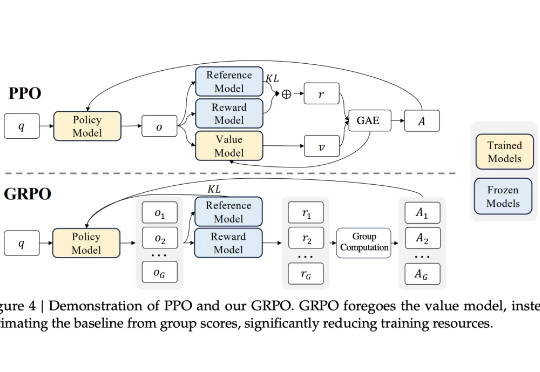
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。
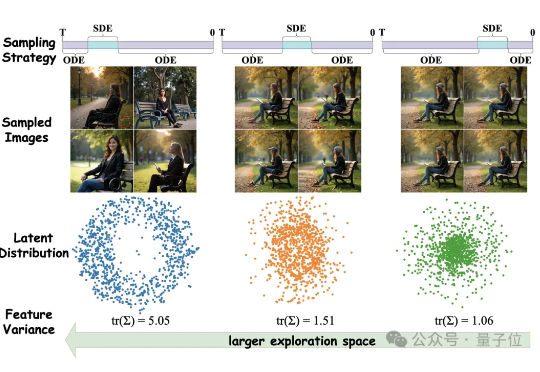
图像生成不光要好看,更要高效。 混元基础模型团队提出全新框架MixGRPO,该框架通过结合随机微分方程(SDE)和常微分方程(ODE),利用混合采样策略的灵活性,简化了MDP中的优化流程,从而提升了效率的同时还增强了性能。
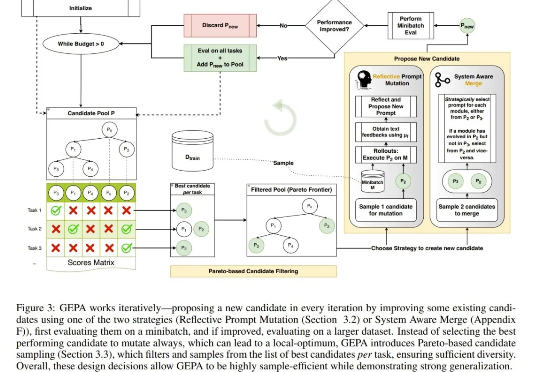
仅靠提示词优化就能超越 DeepSeek 开发的 GRPO 强化学习算法? 是的,你没有看错。近日上线 arXiv 的一篇论文正是凭此吸引了无数眼球。
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。