
阿里HappyHorse突然上线!实测让马斯克和奥尔特曼法庭开撕,还手搓了GTA6
阿里HappyHorse突然上线!实测让马斯克和奥尔特曼法庭开撕,还手搓了GTA6今天,阿里ATH创新事业部的最新视频生成与编辑模型HappyHorse 1.0(官方译名:快乐小马)开启灰度测试。创作者可在阿里云百炼平台和HappyHorse官网注册使用,大众用户可在千问App中体验。
来自主题: AI资讯
9090 点击 2026-04-27 20:10
 搜索
搜索
今天,阿里ATH创新事业部的最新视频生成与编辑模型HappyHorse 1.0(官方译名:快乐小马)开启灰度测试。创作者可在阿里云百炼平台和HappyHorse官网注册使用,大众用户可在千问App中体验。

4 月初,LM Arena 评测平台上出现了三个匿名图像模型,代号分别是 maskingtape-alpha、packingtape-alpha、gaffertape-alpha。几小时后它们消失了。OpenAI 官方还没有正式宣布这个模型,但根据 API 返回的元数据和用户侧的测试记录,它已经有了一个被广泛接受的名字:GPT Image 2。
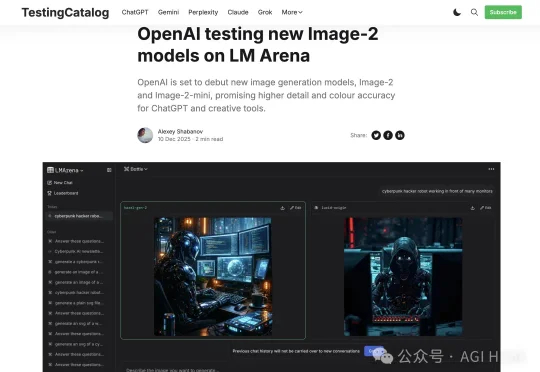
OpenAI 的下一代图像模型 GPT-Image-2,今天在 Chatbot Arena 上被人发现了。独立开发者 levelsio 率先爆料,这个模型以三个代号悄悄上线了 Arena:maskingtape-alpha、gaffertape-alpha、packingtape-alpha。
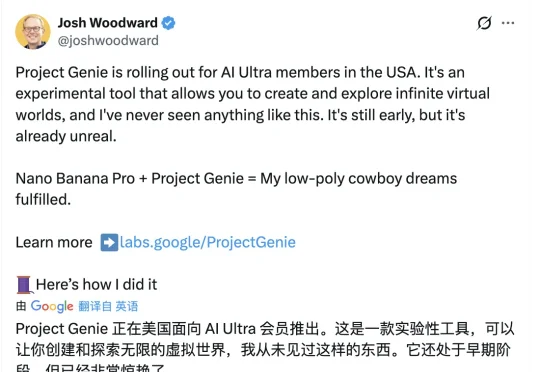
谷歌正式开放世界模型Genie 3的实验性研究原型Project Genie。一夜间暴打了游戏公司市值。《GTA》开发商Take-Two Interactive缩水10%,在线游戏平台Roblox 下跌了超过12%,最惨的是游戏引擎制造商Unity下跌了21%。

家人们, 大概是从去年下半年上下文工程这个概念火了之后,我开始有意识的进行一些碎片化的记录。
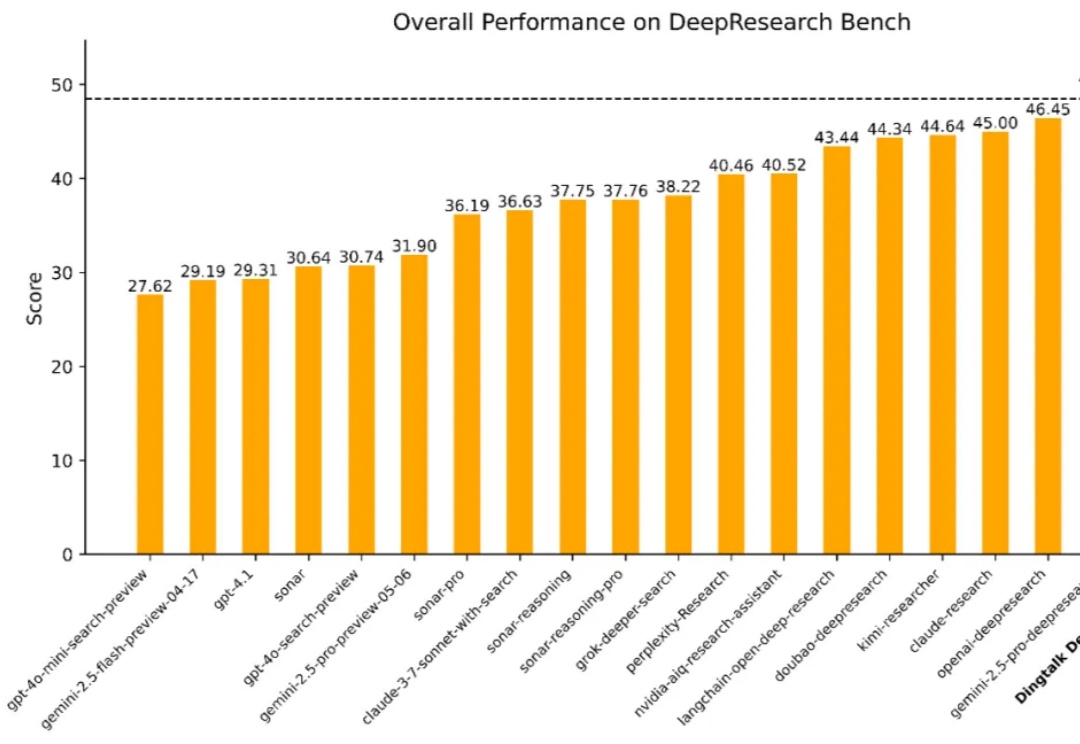
在数字经济浪潮中,企业对于高效、精准的信息获取与决策支持的需求日益迫切。从前沿科学探索到行业趋势分析,再到企业级决策支持,一个能够从海量异构数据源中提取关键知识、执行多步骤推理并生成结构化或多模态输出的「深度研究系统」正变得不可或缺。
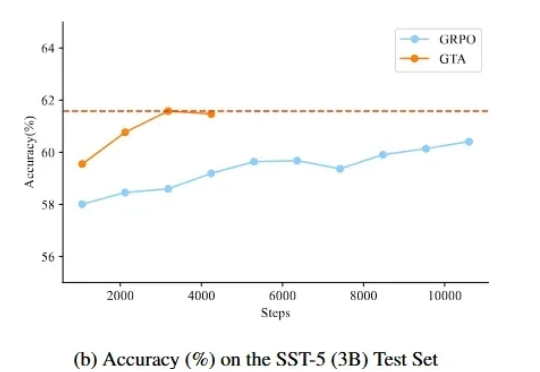
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。

AI 硬件,已经成为大模型之后,又一个令人兴奋的领域。 正如 AI Agent 从通用开始走向垂直,AI 硬件,也已经逐渐分化到「陪伴」、「工作」等各个垂直领域。

大家好,我是袋鼠帝。最近我感觉又好起来了,居然受到了阿里爸爸的关照。前几天,收到了一个阿里旗下钉钉新发布的AI硬件:DingTalk A1。

所有办公协作工具,都具备效率工具和「牛马桎梏」的双重属性,天然容易触动打工人的神经,在 AI 带着职业取代的舆论席卷而来的当下,更是如此。