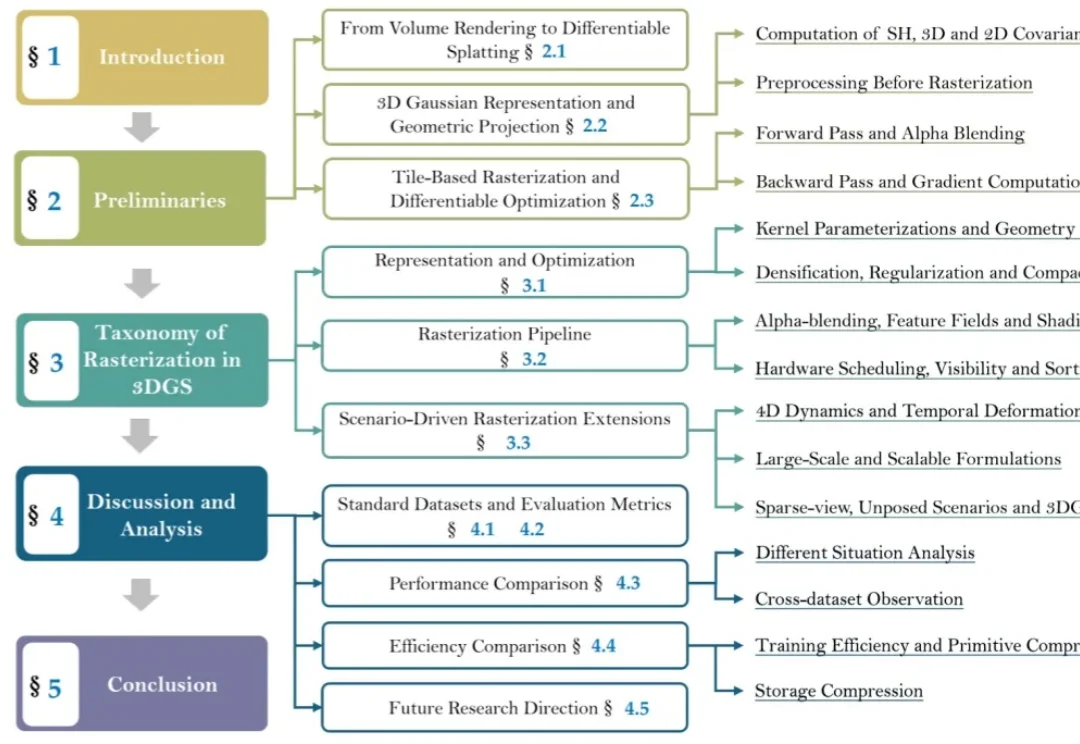
一个场景吃掉700MB显存!3DGS存储焦虑怎么解?这篇综述划了五个方向
一个场景吃掉700MB显存!3DGS存储焦虑怎么解?这篇综述划了五个方向过去三年,3D Gaussian Splatting(3DGS)几乎成为实时3D场景重建与新视角合成的“默认答案”。
来自主题: AI技术研报
7724 点击 2026-07-27 15:49
 搜索
搜索
过去三年,3D Gaussian Splatting(3DGS)几乎成为实时3D场景重建与新视角合成的“默认答案”。
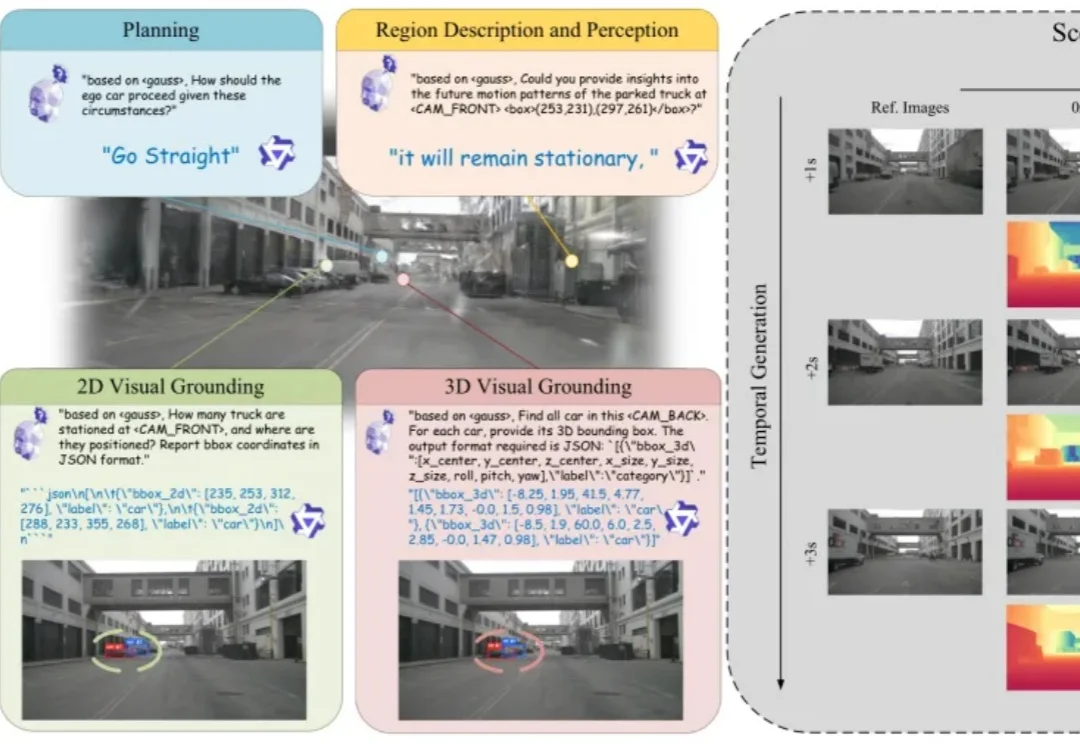
自动驾驶世界模型的研究目标已经从单纯预测未来视觉帧,扩展到构建可用于场景理解、空间定位和后续决策的世界表示。如果模型只能生成外观上合理的未来图像,却无法回答场景中有哪些目标、目标位于何处,以及不同视角下的空间结构如何变化,那么它仍然缺少对三维驾驶环境的显式建模能力。
空间智能与世界模型初创公司知天下(苏州)人工智能科技有限公司(以下简称“知天下”)近日已完成天使轮融资。知天下是一家专注于高斯泼溅(3D Gaussian Splatting,简称3DGS)三维重建与生成技术的AI企业,于 2024 年初推出 3DGS 免费重建与发布服务
近年来,3D Gaussian Splatting(3DGS)在三维视觉和图形学中展现出很强的表示与渲染能力。相比传统体素或神经辐射场,它用一组可优化的各向异性高斯来表示三维场景,既能保留连续空间结构,又能实现高速渲染。

如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。
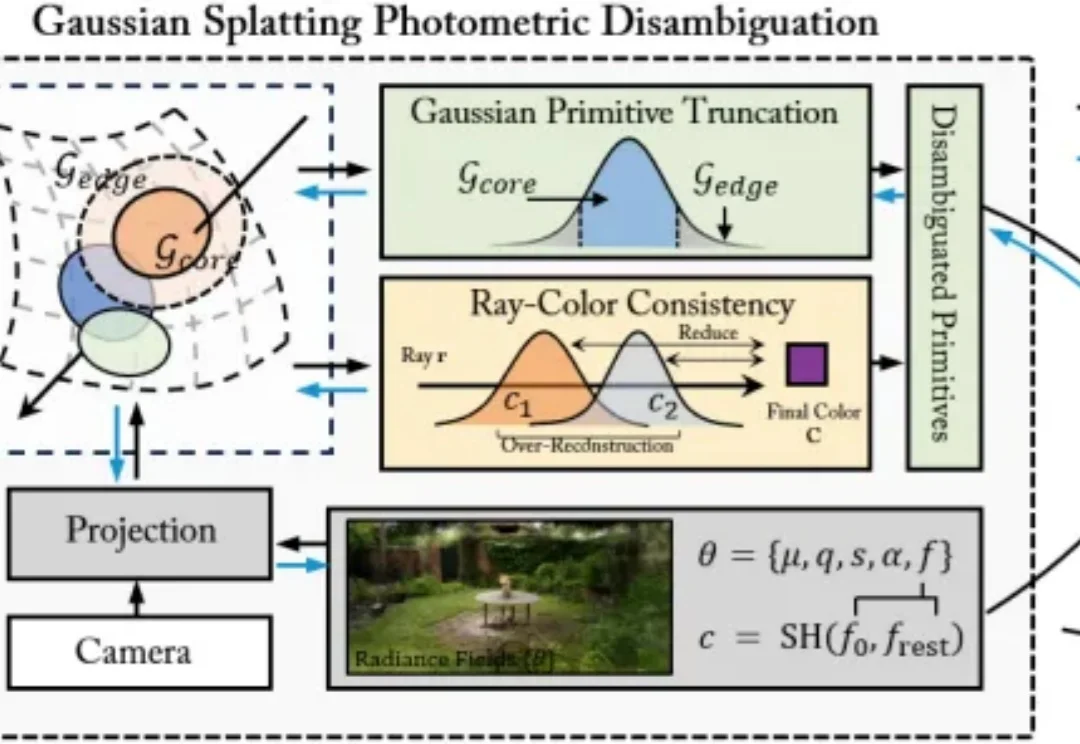
近年来,3D 高斯泼溅(3D Gaussian Splatting, 3DGS)凭借其卓越的新视角合成能力和实时的渲染效率,极大地推动了神经渲染技术的发展。然而,当研究者试图直接从 3DGS 中提取精确的 3D 几何表面(Mesh 等)时,往往会面临严重的几何失真问题。
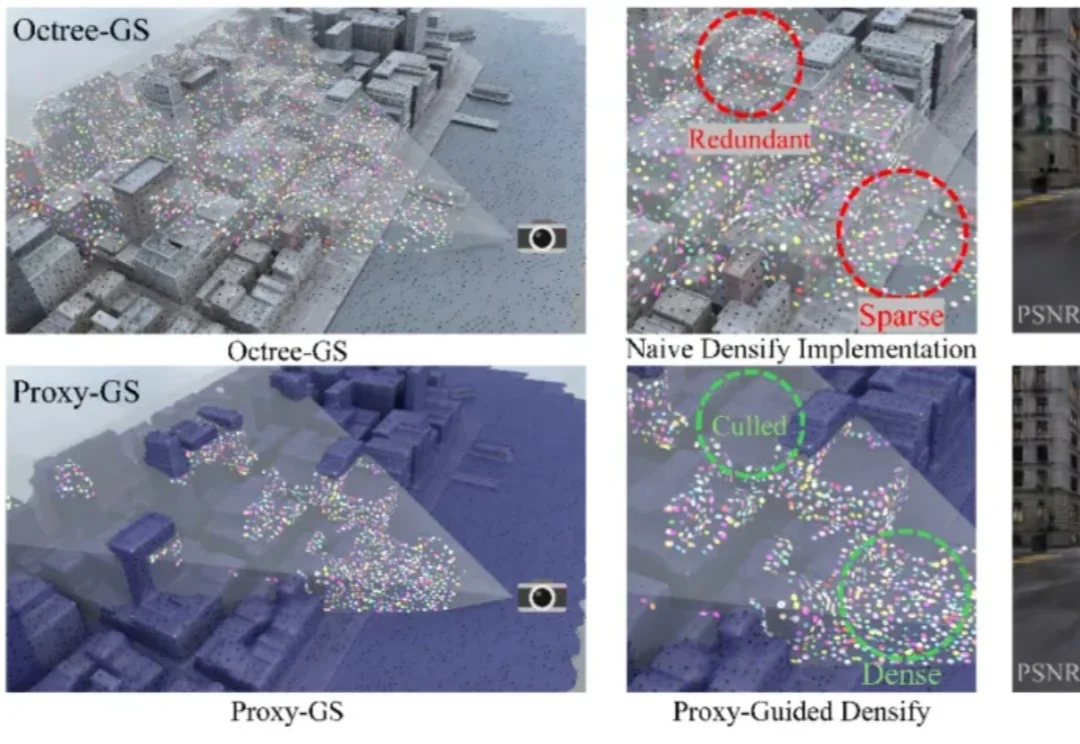
上海交通大学钟志航团队联合上海人工智能实验室、西北工业大学、四川大学等高校在 CVPR 2026 上提出Proxy-GS(Proxy-GS: Unified Occlusion Priors for Training and Inference in Structured 3D Gaussian Splatting),面向基于 MLP 的结构化 3D 高斯溅射(3DGS),

5天时间,AI就搞定了原本需要6个月完成的菲尔兹奖级数学成果的形式化证明。

在三维视觉领域,3D Gaussian Splatting (3DGS) 是近年来大热的三维场景建模方法。它通过成千上万的高斯球在空间中“泼洒”,拼合成一个高质量的三维世界,就像是把一片空白的舞台,用彩色的光斑和粒子逐渐铺满,最后呈现出一幅立体的画卷。
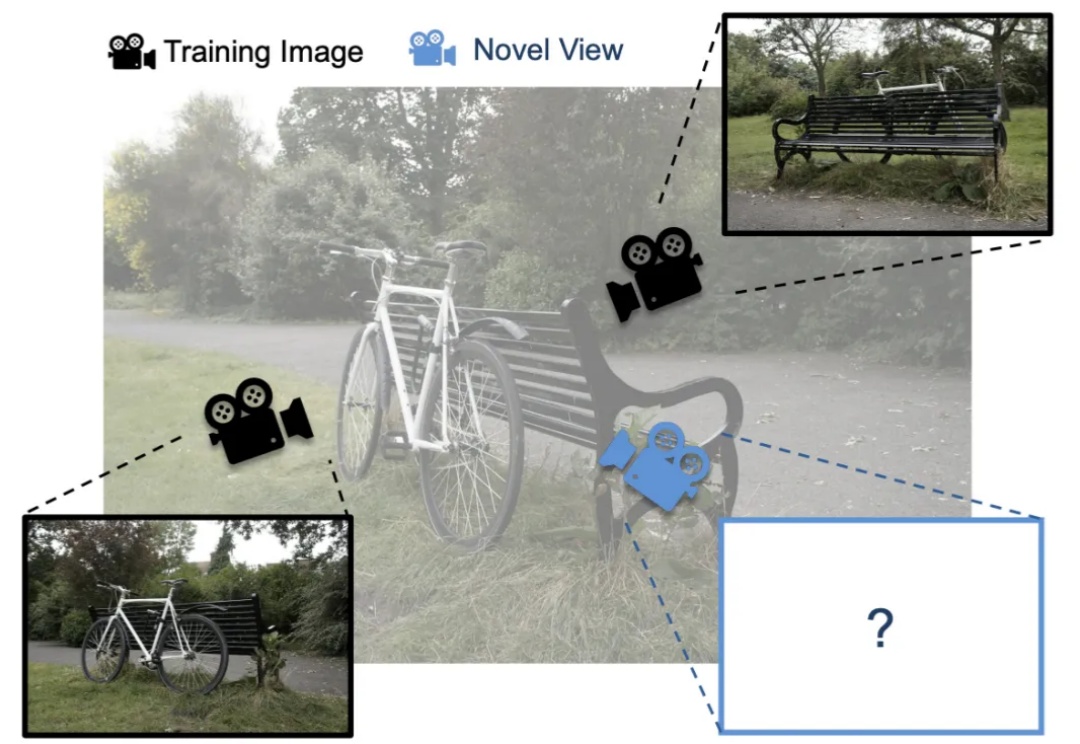
3D Gaussian Splatting (3DGS) 是一种日益流行的新视角合成方法,给定 3D 场景的一组带位姿的图像(即带有位置和方向的图像),3DGS 会迭代训练一个场景表示,该表示由大量各向异性 3D 高斯体组成,用以捕捉场景的外观和几何形状。