悄悄做到第一梯队,「DeeVid AI」拿下3000万欧美用户
悄悄做到第一梯队,「DeeVid AI」拿下3000万欧美用户当我们从业内人士处听到,一款专注欧美市场的 AI 视频 Agent 产品「DeeVid AI」,上线才一年半,注册用户达 3000 万,ARR 也做到数千万美元量级,多少有些意外。这家公司此前并不起眼,没有大额融资的高光时刻,也很少出现在赛道的公开讨论里。
来自主题: AI资讯
9523 点击 2026-07-22 23:36
 搜索
搜索
当我们从业内人士处听到,一款专注欧美市场的 AI 视频 Agent 产品「DeeVid AI」,上线才一年半,注册用户达 3000 万,ARR 也做到数千万美元量级,多少有些意外。这家公司此前并不起眼,没有大额融资的高光时刻,也很少出现在赛道的公开讨论里。

刚刚,字节也坐不住了,推出了 Trae Work 官方知识库教程。我让 Agent 查了下,这个知识库目前大约有 46w 字,85 篇文档。 不得不说,不愧是字节,写文档还是很有一手的!

一觉醒来,Hermes Agent用户圈子直接炸了锅,官方放出了最新的版本:水银。恰如其名,最新版本主打一个“快”,丝滑流畅如水银泻地,冷启动速度提高了80%,但这次更新,“快”仅仅是开胃菜。

刚刚,阿里旗下的Qoder正式推出了Qoder Security,直击AI Coding的安全风险问题。在这个工具中,代码安全内生于 Qoder,贯穿从编码到提交的每一步。Qoder Security的发布,让Qoder成为国内首个交付「编码会话内三层安全护航 + 发现问题同会话修复」能力Agentic Coding产品。

腾讯的设计Agent平台Miora,今天终于全面开放了。之前一直需要邀请码,还得预约排队,而今天,终于正式全量上线。别的不说,你永远可以相信腾讯的产品设计和审美。网址在此:miora.design
今天,腾讯正式发布了其首个研究智能体(Research Agent)——Hyra(Hunyuan Research Agent)。Hyra能够像科研人员一样,提出假设、完成实验、总结经验,再基于经验不断提出新的方案,最终实现递归自我改进(Recursive Self-Improvement,RSI)。

Agent时代,APP应用商店都开始「革自己的命」了。

开始忘记软件以后,创作才真正开始。
Flova 很受关注,融资是一方面,两轮融资,红杉、IDG 和云九资本投资,累计超 8000 万美元,据说是目前视频 Agent 产品的最大融资。而更主要的原因,可能是创始人郭列。郭列 2013 年做出脸萌,之后是 FaceU 激萌,2018 年被字节跳动以 3 亿美金并购,随后在字节孵化了轻颜相机、剪映和醒图。2025 年创业做 Flova,入局视频 Agent 赛道。
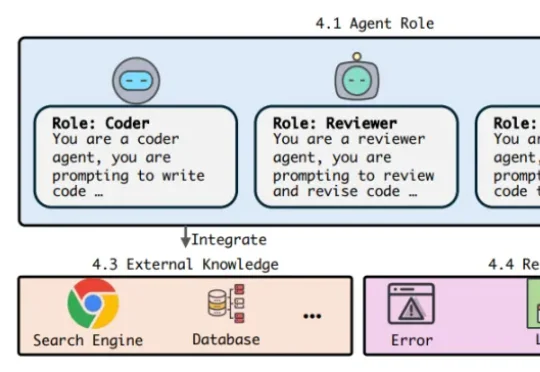
多智能体系统(Multi-Agent Systems,MAS)展示了令人印象深刻的能力:一个模型负责提出方案,另一个模型进行批评,还有模型承担投票、规划或执行。通过角色分工和多轮协作,系统能够解决单个模型难以稳定完成的数学推理、代码生成和知识问答任务。