# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
机器人领域是我们长期关注的赛道,而 Generalist 是当前机器人领域中极少数具备长期竞争潜力的公司,核心优势集中在数据规模、团队能力与清晰的 scaling 路径上。
1. 高质量真机数据是机器人行业公认的核心稀缺资源,凭借 27 万小时的训练数据,Generalist 可能是全球首个在数据规模上达到 GPT-1 量级的机器人团队,有领先其他团队 6-12 个月时间窗口。更引人关注的是,去年 11 月,Generalist 宣称在机器人领域首次验证了类似语言模型的 scaling law。
2. 团队核心成员来自 OpenAI、Boston Dynamics、Google DeepMind 等机构,是 PaLM-E、RT-2 等具身智能里程碑项目的主要贡献者,技术实力非常强大。
3. 团队已经通过一系列的 demo 展示出了清晰的研究路径和模型出色的灵巧性。
我们认为,虽然目前机器人的数据依然非常匮乏,但如果模型性能可通过人类视频与真机数据的混合持续提升,竞争焦点或将从数据规模转向数据配比。率先跑通并工程化最优数据配比的团队,可能不仅能在性能上取得领先,而且能对整个行业产生示范效应。
• Generalist 积累了大量真机数据,有领先其他团队 6-12 个月时间窗口
目前机器人数据采集方式大致可以分为三类:
1. 真机数据采集,即需要与真实世界交互。
1)遥操作(Teleoperation):在前端部署机器人,人类在后端对其进行操控来完成任务并采集数据,数据精度最高,但成本高,受机器人数量、场景的限制;
2)无本体数据采集:不需要真实机器人,人直接操作夹爪或穿戴外骨骼等设备来采集数据。这种方式因为存在缺乏全身信息等问题,对算法要求较高,尤其依赖高精度定位与映射,但更高效、成本更低,也更适合在室外等复杂环境中使用。
2. 纯视频数据采集:仅依赖视频数据进行学习,采集成本低,但数据效率相对不高。
3. 合成数据:通过构建仿真环境,并基于预设规则或程序自动生成数据,具有可控性强、规模化生成的优势。
目前主流观点认为,要训练出可用的机器人模型,还是需要用真机数据。真实数据并非不能扩展,只是无法像仿真那样容易地成倍增长。
自变量机器人的甘如饴曾简单将 LLM 的 Token 量换算为数据时长,来用 LLM 类比当前机器人发展阶段:假设人类语速为 238 词/分钟,且 1 个单词约等于 1.33 个 Token,则 1 小时人类语言数据约等于 1.9 万 Token。在这一口径下,GPT-1 约使用 50 亿 Token,相当于 27 万小时的人类语言数据,GPT-3 的训练规模则上升到约 1580 万小时。
进一步延伸来看,根据 SemiAnalysis,GPT-4 的基础训练数据量约为 13 万亿个 Token,约等于 6.84 亿小时。
而目前行业主流真机训练数据量级在 1 万小时左右,这意味着绝大多数玩家仍处于“前 GPT 时代”,数据在行业内非常缺乏,在这种情况下,自称训练数据达到 27 万小时的 Generalist 可能是目前全球唯一一家在数据规模上刚刚达到 GPT-1 门槛的机器人公司。
而且,要复刻这种规模的数据不仅仅是钱的问题,更是时间的问题。鹿明机器人的丁琰曾表示,仅制造专用的采集硬件就需要 4-6 个月,要复刻 27 万小时数据,至少需要 1000 个人不停采集大半年甚至小一年,因此 Generalist 会有领先其他团队 6-12 个月时间窗口。
• 团队人才密度非常高,技术扎实
团队技术实力非常扎实,三位联创兼具 MIT、Princeton 顶尖学术背景与 Google DeepMind、Boston Dynamics 的业界研发经历,是 PaLM-E、RT-2 等具身智能里程碑项目的主要贡献者,在算法与硬件的协同设计方面拥有实战验证过的技术经验。而且核心成员之间拥有长期的同门学术合作背景及共同创业的经历,这种深厚的信任基础降低了初创期的内部磨合风险与管理成本。
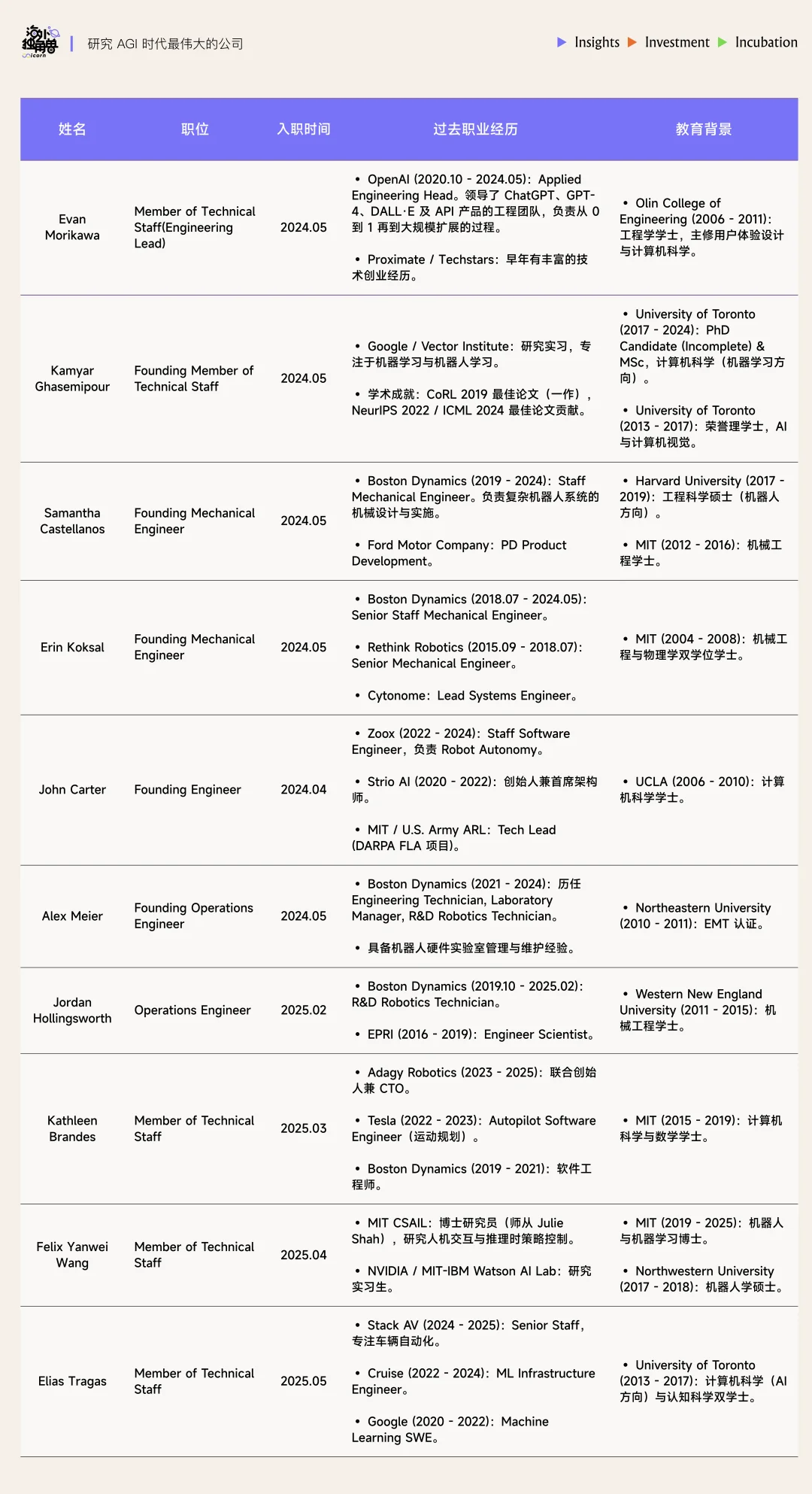
此外,Generalist 将 scaling 视为公司 DNA。Engineering Lead Evan Morikawa 曾是 OpenAI 工程负责人,领导了 ChatGPT、GPT-4、DALL·E 及 API 产品的工程团队,有从 0 到 1 再到大规模扩展的丰富经验。
总的来说,相比另一家明星公司 Physical Intelligence,在核心算法的 Insights 上,Generalist 与 PI 均具备行业顶级实力;在团队构建策略上,PI 更偏向于全明星阵容,成员构成更全面,Generalist 的团队则偏向于精炼。
• 一系列 demo 展示出了模型出色的灵巧性和团队清晰的研究思路
Generalist 在机器人领域最关注灵巧性,从 2025 年 6 月实现的高频动态抛掷,到 9 月组装乐高任务中攻克的亚毫米级精度,再到 GEN-0 在工具使用、柔性物体处理以及高精度装配方面的能力,这一连串的产出展示了 Generalist 在解决物理交互难题上的路线有效性。
而且 Generalist 的模型具备 Low-level 动作生成能力:在端到端控制下,依然能输出丝滑且精准的操作策略。这种让机器人在复杂环境中表现出近似生物本能的灵巧度,是当前市场上非常稀缺、且极难被模仿的能力。
潜在风险
• 不确定性推演:Scaling Law 在机器人领域是否成立?
去年 11 月,Generalist 发布了 GEN-0 模型的同时,声称首次在机器人领域验证了类似语言模型的 scaling law,即随着预训练数据和计算量的增加,下游任务性能呈现可预测的幂律提升。
如果 Scaling Law 不成立,这意味着深度学习在物理世界存在根本性瓶颈,那么整个具身智能赛道的估值逻辑都可能需要重估。但目前的主流观点还是倾向于 Scaling Law 成立,这意味着智能的上限将在一定程度上取决于大规模数据的收集能力,接下来的发展分歧在于需要什么样的数据。
如果基础模型可以通过混合人类视频数据和真机数据来提高性能,那么竞争的要素或许不再只是数据规模本身,而是谁能率先跑通数据的最优配比(recipe)。率先验证并工程化数据混合配比的团队,可能不仅能在模型性能上取得领先,还将实质性推动机器人训练范式的演进,对整个行业产生示范效应。
目前来看,即便引入人类视频数据,模型可能仍需要等量甚至更多的真机数据配合,才能取得理想效果。有学者甚至认为硬件在机器人领域的比重可以达到 70-80%,因此,如果未来机器人训练仍必须依赖大量真机数据,虽然 Generalist 也部署了一些硬件设备来做数据采集,但 Tesla、Figure 等本身具备硬件能力的公司可能会更有优势。
• 机器人的“GPT-3 时刻”仍然需要大量的数据
虽然 Generalist 达到了 GPT-1(27 万小时),但要达到 GPT-3 点水平(1580 万小时),按照 Generalist 目前的采集速度(每周 1 万小时)线性外推,可能还需要 30 年。如果必须靠真机采集才能到 GPT-3,对于初创公司而言,这条路可能在经济上不可行。
这反过来增加了用合成数据或人类视频数据训练模型的迫切性,如果未来发现通过合成数据或人类视频数据就足以训练模型,那么 Generalist 建立的物理采集护城河,可能会被绕过。
• 缺失商业化场景
目前整个机器人行业普遍缺乏明确的商业化落地场景,Generalist 在自建数据采集硬件并与 Scale AI 合作标注的前提下,成本投入会更高。目前公司对外展示的 demo 仍主要停留在叠乐高、叠衣服等层面,相比之下,专注家庭场景的 Sunday 更接近落地应用。
Google 早期发布的 PaLM-E 和 RT-2 等模型成果有类似“随着模型参数增大,模型在具身任务上的表现/泛化越好”的结论,但 Google 并没有公开称已经验证了机器人领域的 scaling law。
2024 年,MIT 和慕尼黑工业大学的研究人员通过对 327 篇论文(包括 Google 发布的模型)进行分析后认为机器人基础模型存在 scaling laws,而且随着模型规模的扩大,新的机器人能力在不断涌现。
去年 11 月,Generalist 声称首次在机器人领域验证了类似语言模型的 scaling law,即随着预训练数据和计算量的增加,下游任务性能呈现可预测的幂律提升。海外社媒普遍认为这是一个重大突破。前 Google DeepMind 科学家 Ted Xiao(参与过 Gemini Robotic、RT-2、RT-1 和 SayCan 项目)在推特上称这个结果非常惊人。

也有评论认为,Generalist 的技术路线还是依赖深度学习,真正的机器人技术突破应该是通过少样本来掌握完成未知任务的能力。但实际上,这是一个非常困难的问题,LLM 目前也没有实现。

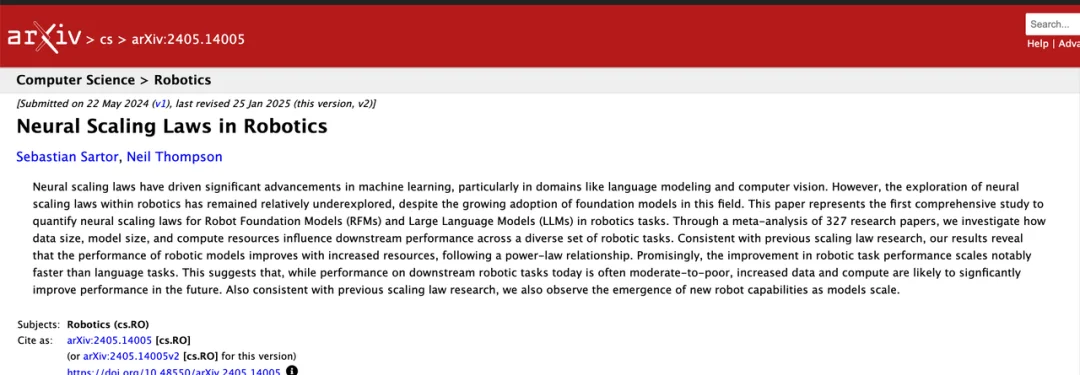
Generalist 团队研模型参数量对模型学习能力的影响时,发现了明显的相变现象:
• 当模型参数较小(例如 1B 级别)时,即便投入海量数据,Training Loss 下降到一定程度后就会停滞,也就是模型“僵化”了,无法吸收更多的数据信息。
• 6B 模型开始受益于 pre-training,并展现出强大的多任务处理能力。当模型扩大到 7B 以上时,发生了相变,即大模型能够持续吸收数据,Training Loss 会持续下降。也就是说,只有跨越这个参数门槛,模型才能真正通过 pre-training 获得通用能力。
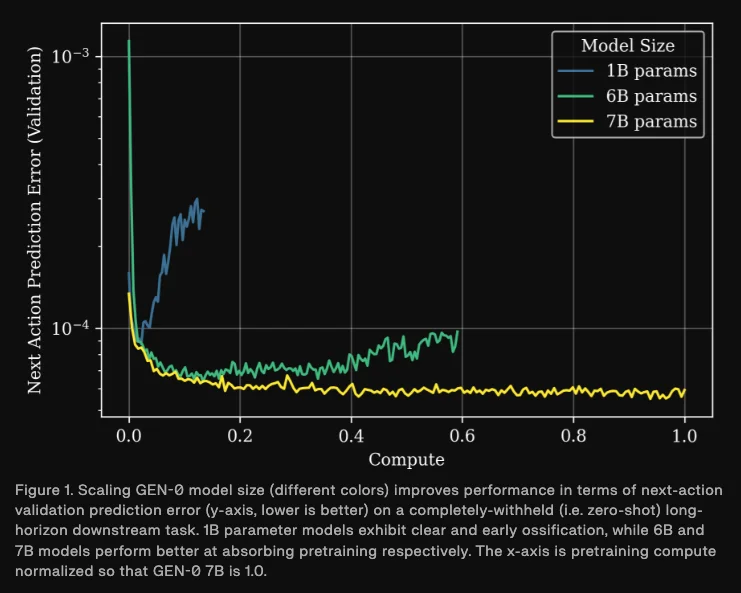
进一步,在足够的模型规模下,pre-training 数据的规模与下游任务的最终表现之间存在显著的幂律关系,并从模型指标和真机实践两个层面对此进行了验证。
在模型指标上,团队截取了使用不同 pre-training 数据量的模型节点,并在 16 个不同的任务集上进行多任务监督微调。结果显示,pre-training 数据越多,下游模型在所有任务上的验证损失(Validation Loss)和下一步动作预测误差均有所下降。
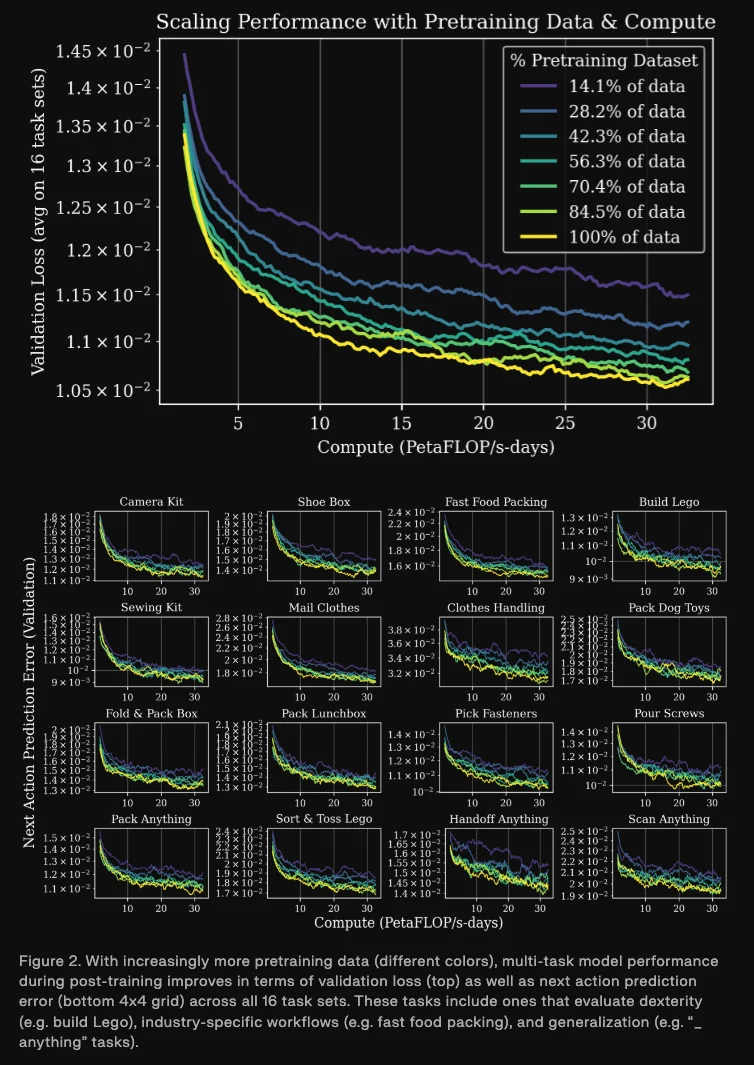
在实践上,通过盲测 A/B 实验,这种趋势被证实可以转移到物理机器人上。团队在实验中确保了 pre-training 与 post training 数据互不重叠,结果显示,增加 pre-training 数据能提高任务成功率:即使在下游数据仅有 5.6 小时的情况下增益也十分显著;而当全量 pre-training 数据与充足的下游数据(550+小时)结合时,任务成功率达到了最高,部分场景峰值高达 99%。
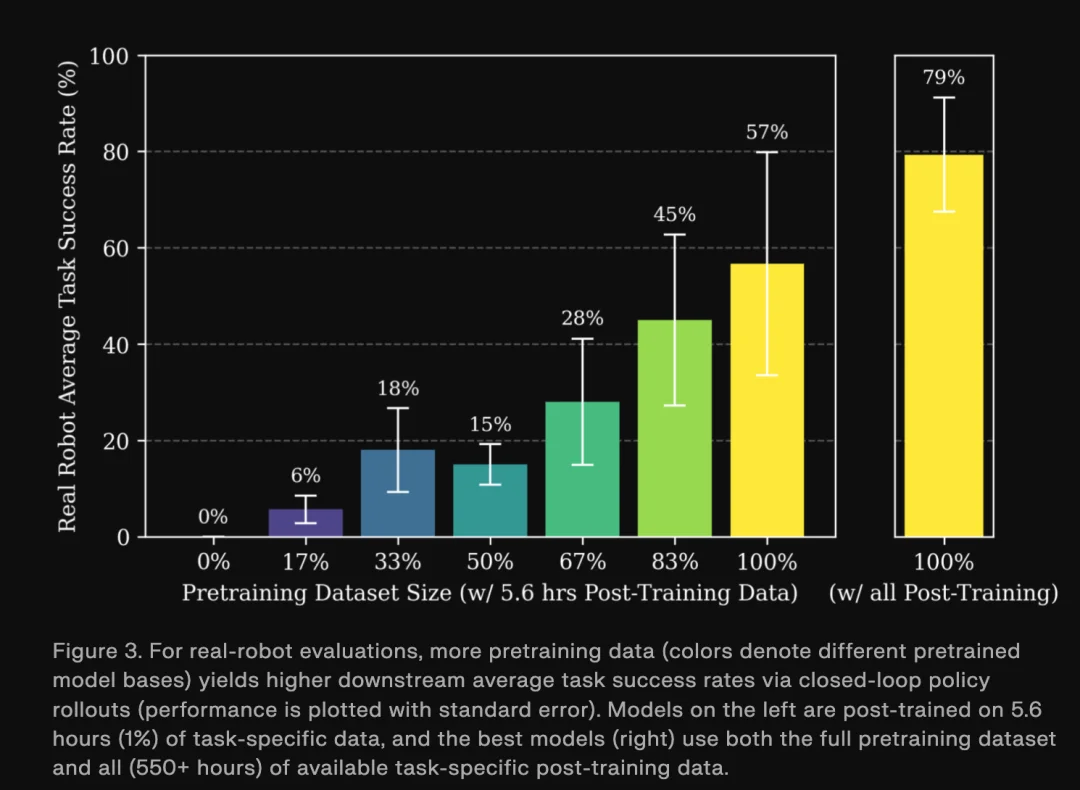
最后,这种性能趋势被总结为可预测的数学模型,基于确立的幂律关系,团队能够回答“达到特定误差需要多少 pre-training 数据”或“更多的 pre-training 数据可以抵消多少下游微调数据预算”等问题。
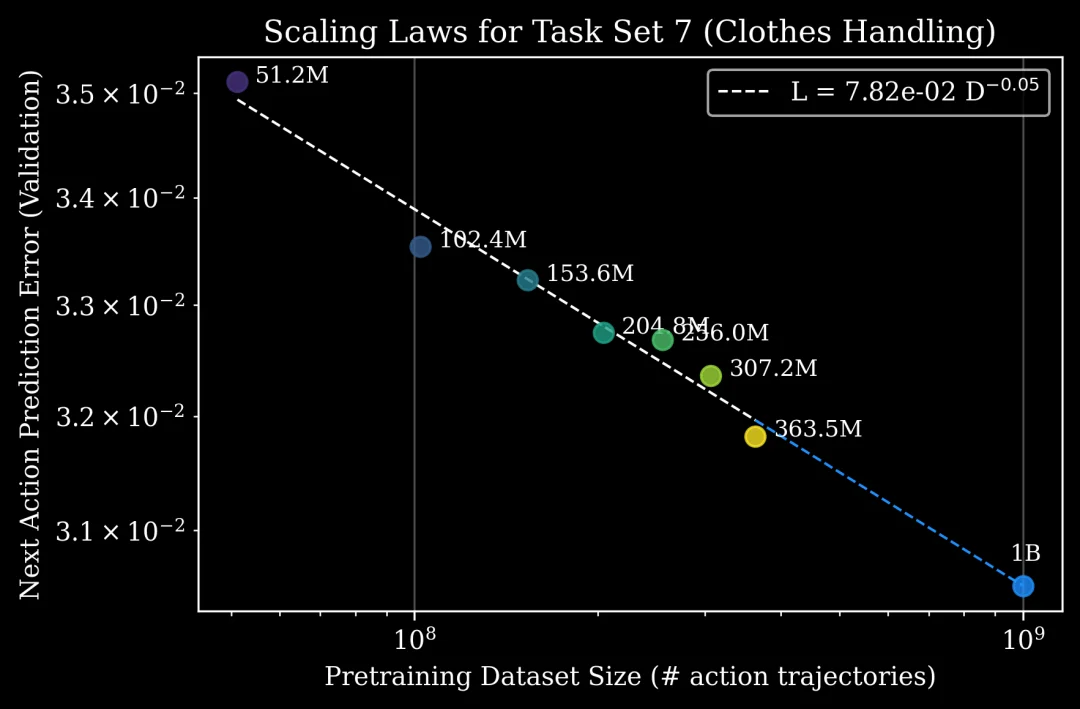
团队还对比了不同数据源对模型性能的影响,发现数据质量和多样性比数据量本身更为重要:来自不同来源(例如不同 data foundry)的 pre-training 数据在不同组合下,会训练出具有不同特征的模型。
比如一些数据配置训练出的模型在预测误差和反向 KL 散度上都较低,这类模型更适合监督微调;另一些数据配置虽然预测误差较高,但反向 KL 散度低,表明模型的输出分布具有更高的多模态性,这对 RL 更有利。
过去,由于人类手部与机械臂在形态和运动方式上的巨大差异,机器人很难直接通过观看人类第一视角视频来学习,通常需要复杂的特征对齐处理。
2025 年 12 月,Physical Intelligence 在 Emergence of Human to Robot Transfer in VLAs 中表明,只要扩大机器人基础模型的 pre-training 规模,模型就会涌现出从人类第一视角视频中学习的能力:
• 在按颜色分鸡蛋、整理梳妆台等任务中,引入相关人类数据后,机器人的性能提升了约 2 倍。
• 如果没有大规模的 Pre-training,模型会将人类和机器人数据视为完全不同的特征,随着 pre-training 中机器人数据多样性的增加,模型内部对人类和机器人的特征表示会自动开始对齐,从而能“听懂”人类视频里的演示。
为了实现这一点,研究团队采用了人类数据和机器人数据协同微调(Co-finetuning)策略,但需要注意的是:
• 微调并非简单地把所有数据混在一起,而是将人类数据与最相关的真机数据混合。以分拣鸡蛋为例,真机数据提供了“将鸡蛋放入纸盒”的基础动作能力,而人类数据则补充了“按颜色分类鸡蛋”的高级逻辑演示。

• PI 在论文中采用的数据混合比例为 1:1,因为 PI 认为 1:1 的比例既可以保留模型原有的机器人操作能力,又可以有效引入人类演示,但 PI 在论文中并没有给出其他配比(如 3:7)的对比实验结果。

Generalist 的 CEO Pete Florence 曾在 Google 主导或参与了多个重要机器人项目,如 PaLM-E、RT-2。

PaLM-E 验证了随着参数规模增大,模型在具身任务上的整体表现会持续提升,并且不会出现传统多任务学习中常见的灾难性遗忘问题。同时,PaLM-E 展现了显著的正向迁移现象:训练语言与视觉任务(如 Web VQA)不仅不会干扰机器人控制,反而能提升机器人的执行能力,体现出“读的书越多,干活越聪明”的特性。在足够大的模型规模下,还涌现出了多模态思维链能力,使模型能够在视觉、语言和动作之间进行更复杂的推理。
RT-2 进一步展示了泛化能力的提升。相较于以 RT-1 为代表、没有从大规模网络语义知识中迁移出语义推理能力的早期模型,RT-2 依托数百亿参数规模的 VLA 架构,以及多模态与机器人数据的联合微调,在未见过具体任务指令的情况下展现出了泛化能力。例如,模型能够理解“捡起那个已灭绝的动物”这一指令,并借助互联网语义知识推断出“恐龙是已灭绝动物”,从而在缺乏对应任务示例的情况下完成操作。
Generalist 成立于 2024 年,目标是构建通用机器人模型,将 scaling AI 与机器人技术视为公司 DNA。公司在机器人领域最关注灵巧性(dexterity),公司认为这需要在数据、模型和硬件层面都有突破。2025 年 3 月,Generalist 完成由 Nvidia(NVentures)和 Boldstart Ventures 领投的种子轮投资。
2025 年 11 月,Generalist 发布了基础模型 GEN-0,并用一个长序列任务来展示 GEN-0 的综合能力:
在完成这个任务过程中,模型没有被灌输分步指令,而是在单一的神经网络流中完成所有步骤,展示了模型在工具使用、柔性物体处理以及高精度装配方面的能力。此外,GEN-0 还展示了跨具身能力:模型已成功部署在 6-DoF 机械臂、7-DoF 机械臂,以及 16+ DoF 的半人形机器人上。

X、reddit 等社交媒体上大众对于 GEN-0 的灵巧度和所能完成任务的精细程度普遍表示赞叹,斯坦福机器人教授 Shuran Song 在 X 上对机器人能够完美地插入箱盖感到“satisfying”。
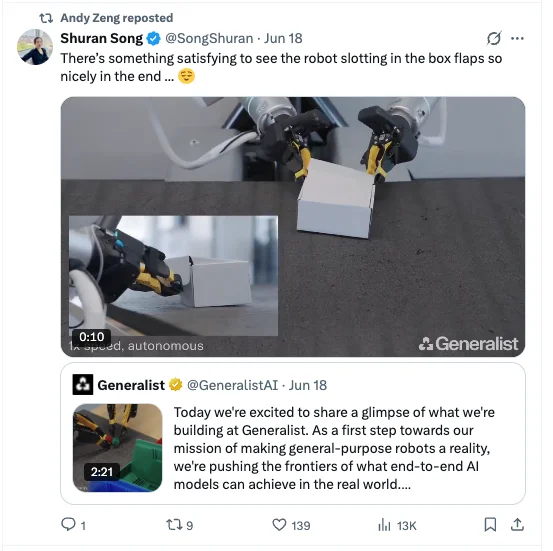
今年 6 月,公司发布了第一篇 blog,在所有 demo 中,机器人都是完全自主的,由深度神经网络实时控制。该网络直接将像素和其他传感器数据映射为 100Hz 的动作指令。Blog 中展示了四个具体的任务:
1. 分拣紧固件:展示了从杂乱中快速抓取、调整方向并分类放置细小、扁平物体的能力。
2. 折叠盒子并包装车锁:展示了处理关节物体(盒子)和可变形物体(链条锁)的长序列能力,以及在该过程中所需的毫米级精度和力度控制。
3. 回收螺丝:展示了工具使用和复杂的双臂配合(如刮掉磁性批头上的螺丝、弯曲纸盘做漏斗)。
4. 拆解、分类并抛掷乐高:展示了强力双臂配合(拆解)、重抓取、泛化(识别不同积木结构和料仓位置)以及高速动作(抛掷)。
9 月,公司在 6 月展示的乐高任务的基础上,又介绍了一项新的内部评估机器人能力的任务:乐高积木的模仿构建。公司引用第三方观点,将乐高积木的模仿构建能力归类为通用机器人的最高等级(Level 4),即能够以极高的精度执行依赖于力的精细任务,并对环境物理力做出细微反应。
具体来说,人类先搭建一个小的乐高结构,机器人通过观察后,能够从零开始复制出完全一样的结构。在这个任务上,公司依然采用端到端的方式,模型直接接收视觉像素输入,并输出 100Hz 的动作指令,而且不需要针对该任务进行特定工程设计,也没有定制的指令代码,机器人完全依靠“看懂”然后“照做”。


这些 demo 的亮点在于:
1. 极高水平的灵巧度:组装乐高比拆解或抛掷(6 月展示的 demo)难得多,因为它需要亚毫米级的精度。机器人需要精确对齐积木的凸粒,并在对齐的瞬间施加恰当的压力进行按压。
2. 视觉理解与模仿能力:机器人不再只是执行预定义的动作,而是具备了“看懂要做什么”的能力。它通过观察人类搭建的成品,自行推导出构建目标。
3. 序列推理能力:机器人不仅要理解最终形态,还要规划步骤。对于每一块积木,模型必须选择正确的颜色和形状,调整方向,将其放置在准备位置,最后正确地组装上去。
4. 泛化能力:虽然目前的 demo 仅限于使用 4 种颜色的 2x4 乐高积木搭建 3 层结构,但其组合的可能性非常庞大。公司估算,即便是在这个限制条件下,也存在约 99840 种可能的组合(基于无色 3 砖组合有 1560 种变体,再乘以颜色的排列组合计算得出)。公司表示这意味着机器人并非死记硬背,而是真正具备了应对多样化结构的能力。
数据采集与处理
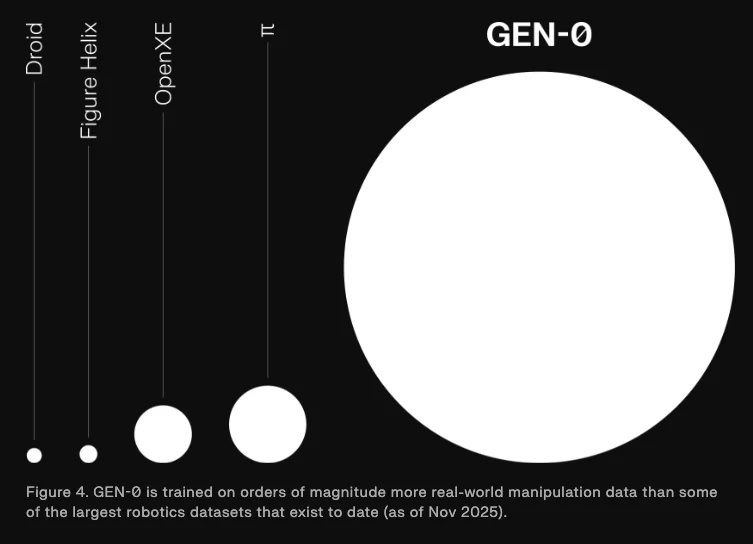
在数据总量上,GEN-0 在 pre-training 上使用了超过 27 万个小时的真实世界机器人操作数据,这些数据来自全球数千个家庭、仓库和工作场所的各种活动,而且数据飞轮还在加速,目前以每周 1 万小时的速度新增。
• Generalist 是如何收集数据的?
Generalist 使用 UMI 进行数据采集,通过在全球范围内部署数千个数据收集设备和机器人,实现了并行化、多样化地数据采集。
Reddit 上有评论表示公司用手套采集数据,手套的手指形状类似机器人的夹爪,让人类在做日常家务和任务时佩戴,而且根据公司发布的数据采集视频推测,佩戴者的头上装有一个摄像头,每只手套上也各有一个摄像头。
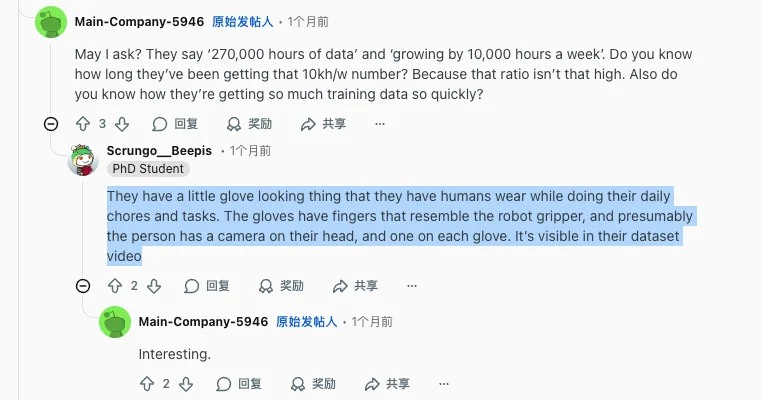
用户评论:他们有一种看起来像小手套的装置,让人类在做日常家务和任务时佩戴。手套的手指形状类似机器人的夹爪,而且可以推测,佩戴者的头上装有一个摄像头,每只手套上也各有一个摄像头。这些在他们的数据集视频中是可以看到的。
Generalist 还与多家 data foundry 合作,在不同环境中采集多样化的数据。通过持续的 A/B 测试,他们可以评估各个合作伙伴的数据质量,并据此调整数据采购比例。

• Generalist 是如何处理这些数据的?
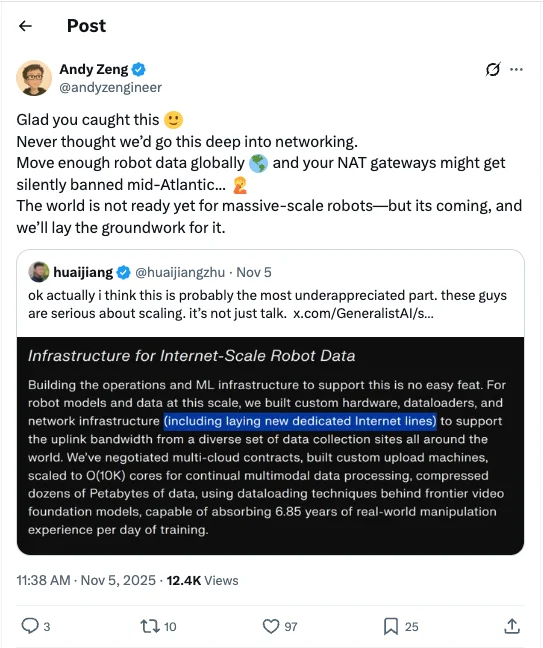
公司构建了专用的硬件和处理管线,甚至铺设了专用网络线路,来支持从各个站点到云端的高带宽数据上传,每天能处理相当于 6.85 年的人类操作经验数据。
• 数据采集成本有多贵?
The information 报告显示,Generalist 数据供应商是 Scale AI。1X 的 Engineering Lead 表示,Scale AI 曾雇佣美国大学生标注 CS 领域的数据,每小时收费 50 美元,再以每小时 200 美元价格卖出去,据此或可简单估算 Generalist 的数据采集成本。
Egocentric data(自我中心数据 / 第一视角数据)指的是从执行者自身视角采集的数据,也就是“我看到什么、我怎么动”的数据,而不是从外部第三视角观察得到的数据。
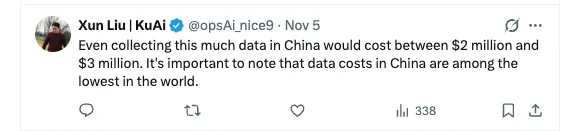
X 上有评论认为,即使是在中国,要收集到训练 GEN-0 的数据也要花费 200-300 万美元。
硬件支持
除了上述数据采集的硬件之外,今年 9 月,Generalist AI 成为 Physical AI Fellowship 项目首批(2025 秋季)入选的 8 家初创公司之一。
这个项目由 MassRobotics 联合 AWS 和 NVIDIA Inception 共同发起,目的是通过提供技术资源来加速物理人工智能(Physical AI)领域的初创公司发展。入选公司主要可以获得以下支持:
• 来自 AWS 生成式 AI 创新中心的科学家和工程师的技术支持。
• 有 20 万美元的 AWS 云服务额度以及 NVIDIA 的硬件和软件技术栈(如 Isaac 平台、NVIDIA Cosmos)支持,同时可通过 NVIDIA Inception 初创企业计划,以优惠价格获取软件和硬件。
• 可以进入 MassRobotics 的全球机器人合作伙伴网络。

除了 Generalist AI,首批名单还包括 Bedrock Robotics、Blue Water Autonomy、Diligent Robotics、RobCo、Tutor Intelligence、Wandercraft 和 Zordi。

模型新架构
传统机器人架构通常将机器人模型系统分为“慢思考”(System 2,高层规划)和“快反应”(System 1,底层控制)。GEN-0 摒弃了这种分离,使用一种称为 Harmonic Reasoning(谐波推理)的机制,这是 GEN-0 区别于传统机器人模型的架构创新。
具体来说,这种架构将感知 Token 和动作 Token 融合在同一个 Transformer 流中进行处理,让模型学会了一边做一边想。它不需要停下来规划,而是能以极高的频率(100Hz+)生成连续、流畅且智能的动作。
Generalist 成员来自 OpenAI、Boston Dynamics、Google DeepMind 等。在加入 Generalist 之前,部分成员参与过 PaLM-E、RT-2 等模型的研究与发布,也曾负责将 ChatGPT 和 GPT-4 拓展到数亿用户规模,或曾参与自动驾驶关键技术以及机器人系统(如 Atlas、Spot、Stretch)的开发工作。
• Pete Florence (CEO & Co-founder)
Florence 曾任 Google DeepMind 高级研究科学家,2019 年博士毕业于 MIT,博士期间专注于视觉引导的机器人操作研究,提出了 Dense Object Nets 等具有代表性的工作,强调从原始感知到动作的端到端学习。毕业后加入 Google,主导或参与了多项重要机器人项目,包括 PaLM-E 和 RT-2。2024 年,Florence 离开 Google 创立了 Generalist。值得一提的是,DeepMind 在今年 3 月发布的 Gemini Robotics 的论文中 4 次引用了 Florence 共同署名的相关研究成果。
• Andrew Barry (CTO & Co-founder)
Andrew Barry 曾任 Boston Dynamics 资深机器人学家,具备扎实的硬件与系统集成背景。2016 年博士毕业于 MIT,博士期间专注于高速自主无人机导航研究,毕业后在 Boston Dynamics 工作五年,参与了 Spot 机器狗机械臂项目的研发。在加入 Generalist 之前,他还曾在 Broad Institute 从事机器学习相关工作。
Andrew 与 Pete 同为 Russ Tedrake 的学生,两人的学术合作开始于一项轻量级无人机立体视觉避障算法研究。此前两人曾共同创办教育类工作坊 Stage One Eduaction,以通俗易懂的方式向儿童教授基础 engineering 知识,已累计教了上万名孩子。
• Andy Zeng (Chief Scientist & Co-founder)
Andy Zeng 曾任 Google DeepMind 研究科学家,主要研究方向为机器人抓取与物体理解。2019 年博士毕业于普林斯顿大学,因在机器人抓取和视觉感知领域的研究多次获奖,包括亚马逊抓取挑战赛的冠军。他的代表作 TossingBot(一个能够自主学习投掷不同物体的系统,第二作者为 Shuran Song)曾获得 RSS 2019 最佳系统论文奖提名。Andy 早在 2018 年便在 Google 实习,后来加入 Google 成为机器人团队的核心成员,与 Pete Florence 合作密切,共同发表超过十七篇论文,并因“让机器人自己写代码”(Code as Policies)等研究而广受关注。
• 其他成员
机器人领域的初创公司非常多,如果用场景复杂度作为纵轴,交付形态作为横轴,可以粗略画出一个美国机器人产业象限图。过去,市场的关注点主要集中在下半区,即工厂、物流等相对结构化的场景,机器人要完成的任务的确定性也更高,随着 LLM 的发展,市场的关注点集中到了上半区。
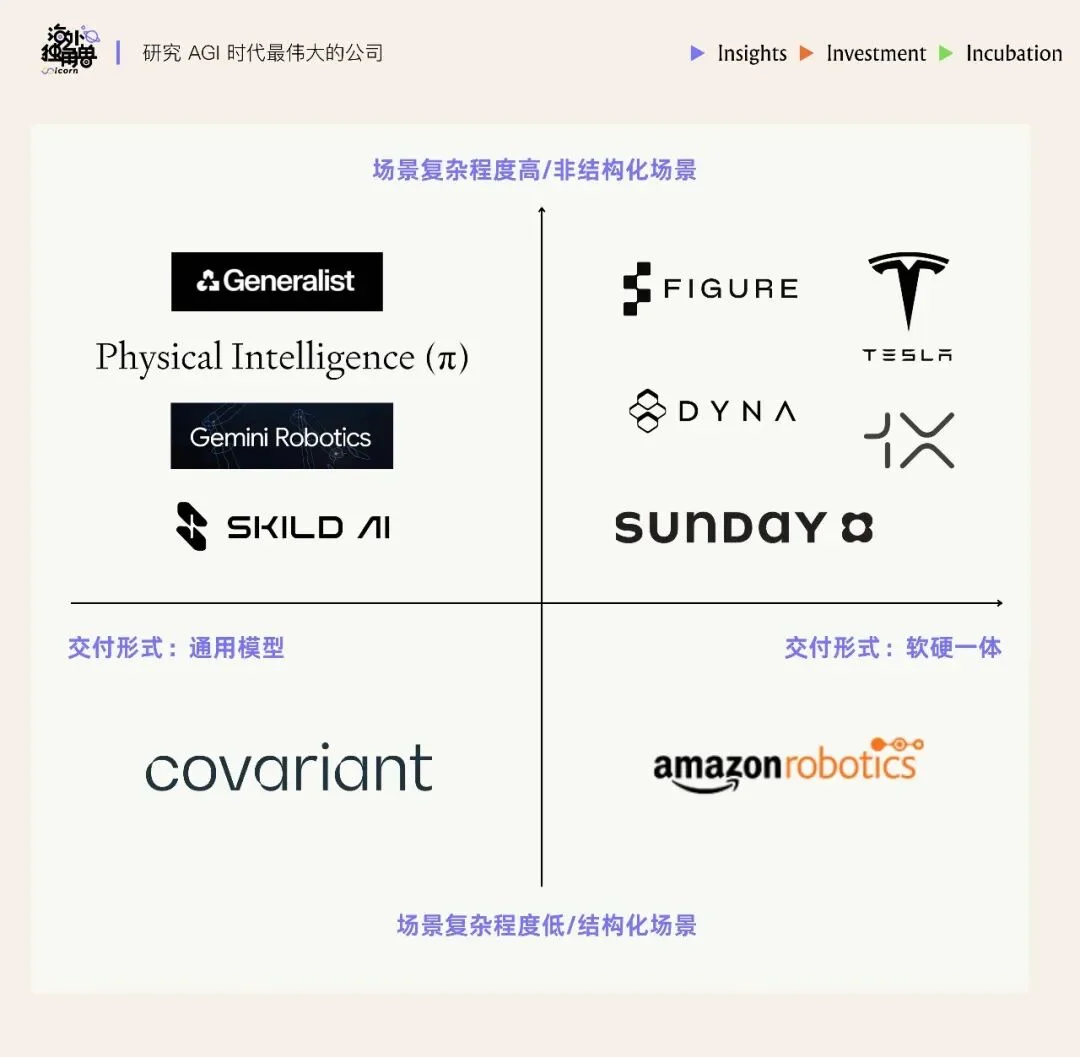
• 第一象限(右上):消费级通用机器人。典型代表是 Sunday,注重实用性,用低成本的手套采集数据,目标是在家庭场景中运用。
• 第二象限(左上):通用具身大脑。这一象限的 bet 在于硬件会商品化,因此只要解决了最难的“大脑”问题,就可以赋能任何硬件。典型代表是 Physical Intelligence,专注于机器人大脑的研发, 并不自己做硬件,但会进行硬件合作。
• 第三象限(左下):在垂直场景做机器人大脑。典型代表是 Covariant,公司从物流领域出发,希望做通用机器人大脑,去年 8 月,Amazon 与 Covariant 达成协议,“收购”了三位联合创始人和核心研究团队,并获得了 RFM-1 模型的非独家授权。
• 第四象限(右下):在垂直场景,比如工厂、仓库等规则明确的地方,通过极致的软硬件整合,把效率做到极限。典型代表是 Amazon Robotics,专注于为了自家仓库效率的极致定制。
Generalist 的优劣势
Generalist 作为新成立的通用机器人大脑公司,位于上图的第二象限。总的来说,Generalist 最大的护城河依然是大量端到端的真机数据和极强的团队技术实力,但也面临着很大竞争压力:Physical Intelligence 拥有更完善的团队组成,并刚完成了巨额融资;Google 拥有大量的 TPU 算力和资金支持,还可以利用 Gemini 模型能力;Sunday 则在家庭场景落地更快。

• Generalist VS Physical Intelligence
在技术上,PI 的 Flow Matching 技术可以直接输出连续平滑的电机信号,解决了传统动作生成模型(如 Google RT-2)因离散化 Token 导致的动作生硬问题,而且 PI 开发的 Recap 算法赋予了模型自我进化能力,能通过专家修正和自我尝试提升任务吞吐量并降低失败率。Generalist 目前仍缺乏这种部署后“越用越强”机制。
在生态和团队建设上,PI 积极构建生态并与机器人硬件公司开放合作,而 Generalist 的 Demo 目前仅限于桌面操作,暂时缺乏实际产线的验证;PI 在团队上由 Chelsea Finn、Sergey Levine 等多位学术界泰斗组成了全明星阵容,团队构建上也更全面,相比之下,Generalist 更加精炼。
此外,PI 在 2025 年 11 月宣布完成 6 亿美元融资,估值高达 56 亿美元,在融资进度上相对更领先。
• Generalist VS Google
在生态上,Google 采取了类似“Android for Robots”的开放策略,通过 Open X-Embodiment 联盟连接全球实验室与硬件厂商,而 Generalist 缺乏 Google 那种能迅速将模型分发到不同硬件本体上的生态掌控力,因此 Generalist 或许得在数据质量和灵巧操作上建立足够高的壁垒。
而且,这是一场资源不对等的持久战,Google 拥有大量的 TPU 算力和资金支持,而 Generalist 作为创业公司,必须时刻关注高昂的数据采集成本带来的资金消耗率问题。
• Generalist VS Sunday
相比 Sunday,Generalist 凭借高质量的数据和精密控制,能够完成非常精密的装配任务,而 Sunday 可能受限于低成本的手套采集方式,缺乏关键的力反馈信息,暂时聚焦于处理容错率较高的家务。
但在商业化落地的赛道上,Sunday 明显走得更快,Sunday 已经明确表示将在 2026 年晚些时候启动 “Founding Family Beta”计划,计划把约 50 个 Memo 机器人放到真实家庭中进行测试和使用。
文章来自于“海外独角兽”,作者 “Haozhen”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
