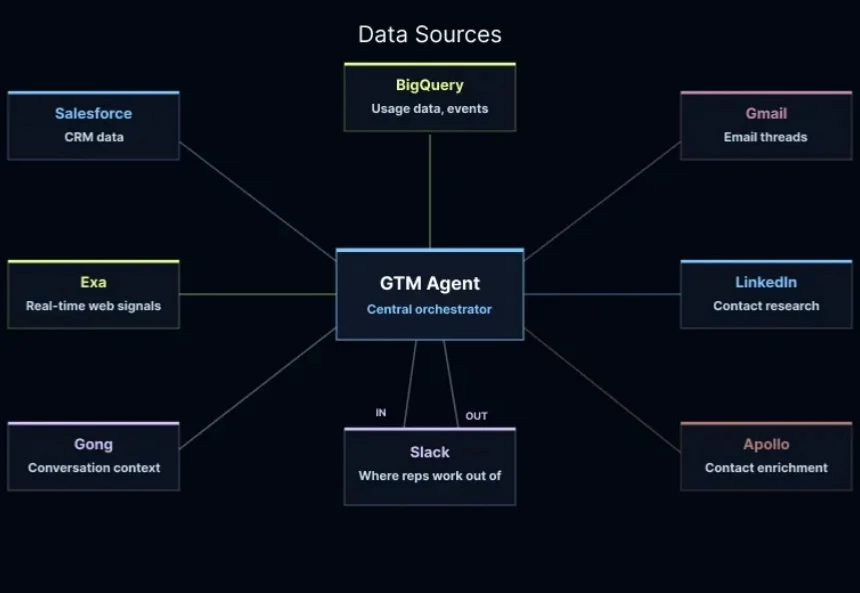
揭秘|LangChain团队用AI agent做销售和营销的最佳实践
揭秘|LangChain团队用AI agent做销售和营销的最佳实践你有没有想过,销售这件事可能会被彻底重新定义?不是那种换个 CRM 系统或者学几个销售话术的小改进,而是从根本上改变销售人员的日常工作方式。
来自主题: AI资讯
7458 点击 2026-06-16 14:15
 搜索
搜索
你有没有想过,销售这件事可能会被彻底重新定义?不是那种换个 CRM 系统或者学几个销售话术的小改进,而是从根本上改变销售人员的日常工作方式。
过去一年,AI 推理模型的使用成本让不少开发者叫苦。

近日,AI制药独角兽Chai Discovery宣布与制药巨头辉瑞达成许合作许可。合作后辉瑞将获得Chai Discovery首次曝光的新一代模型Chai-3的优先访问权限,以及利用辉瑞专有数据、量身定制的定制模型。
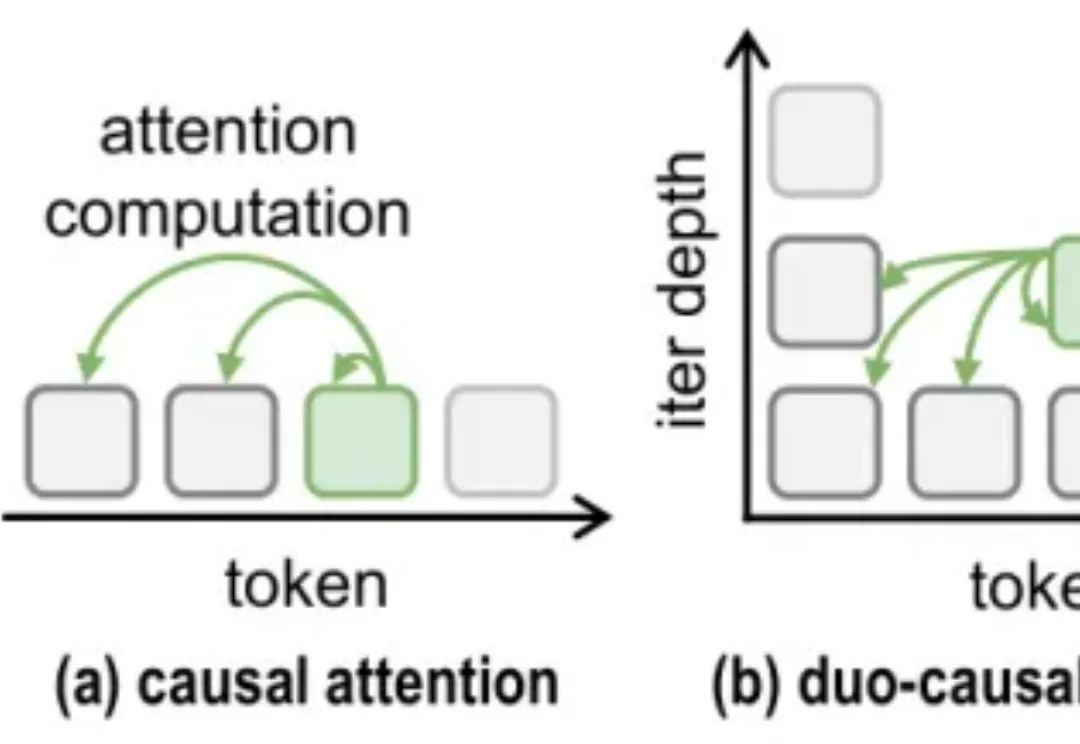
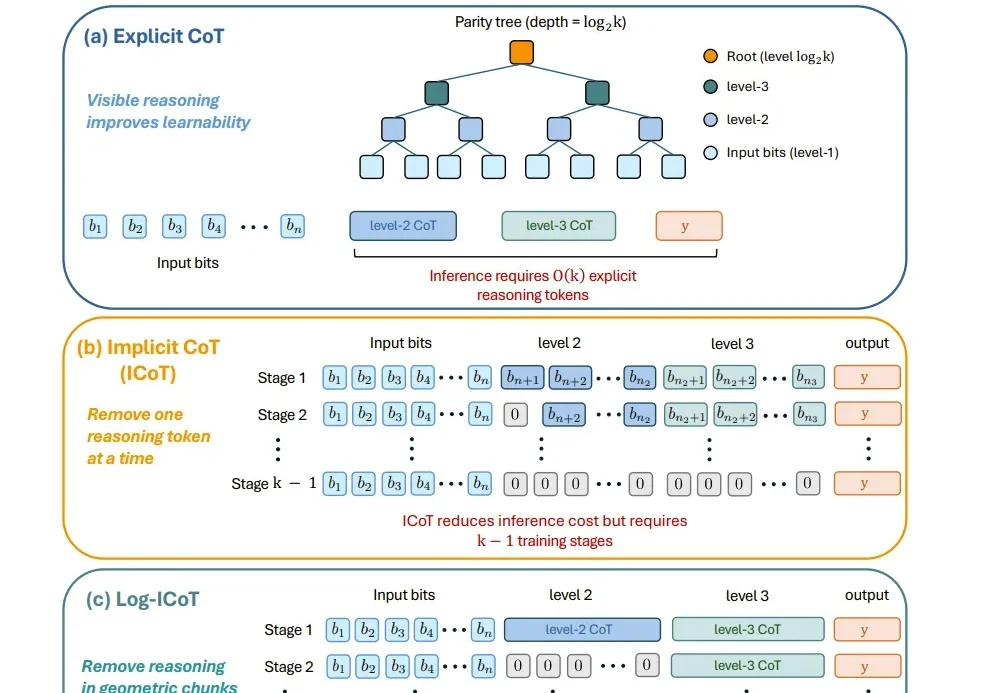
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。
2026 年以来,OpenAI、Anthropic、LangChain 等机构纷纷发布关于 Harness Engineering 的技术博客,OpenClaw、Hermes Agent 等项目的火爆更让 Harness Engineering 成为业界热词。人们的共识正在形成:模型的能力释放,依赖于一套精密的外部框架。
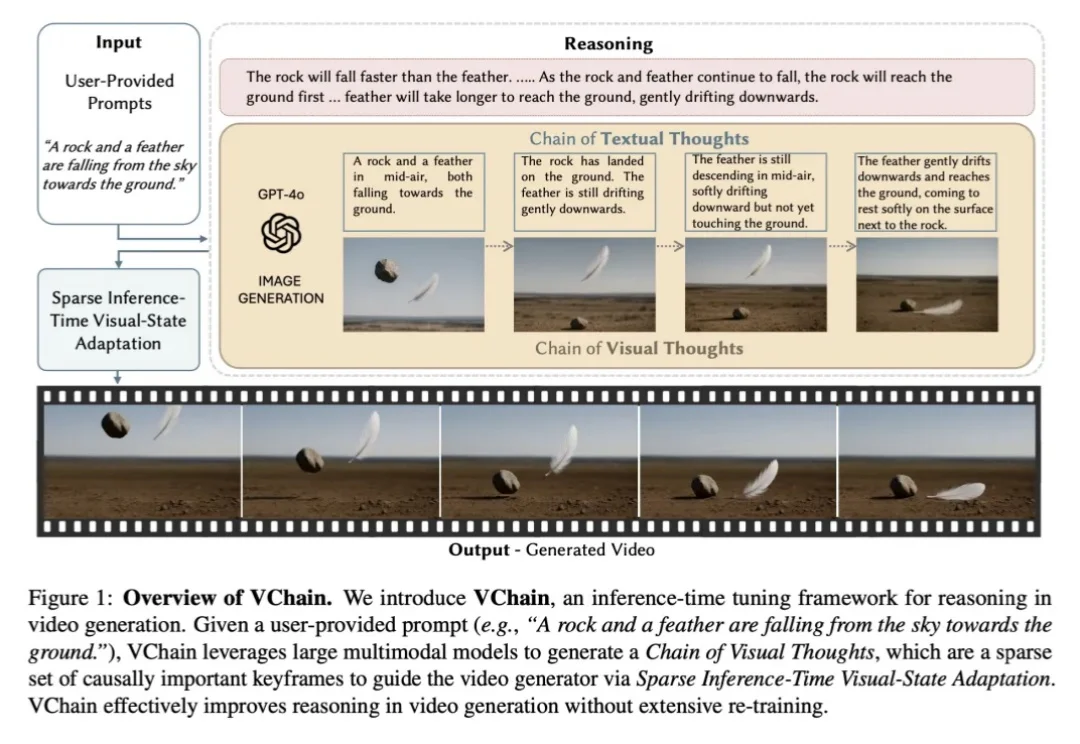
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?
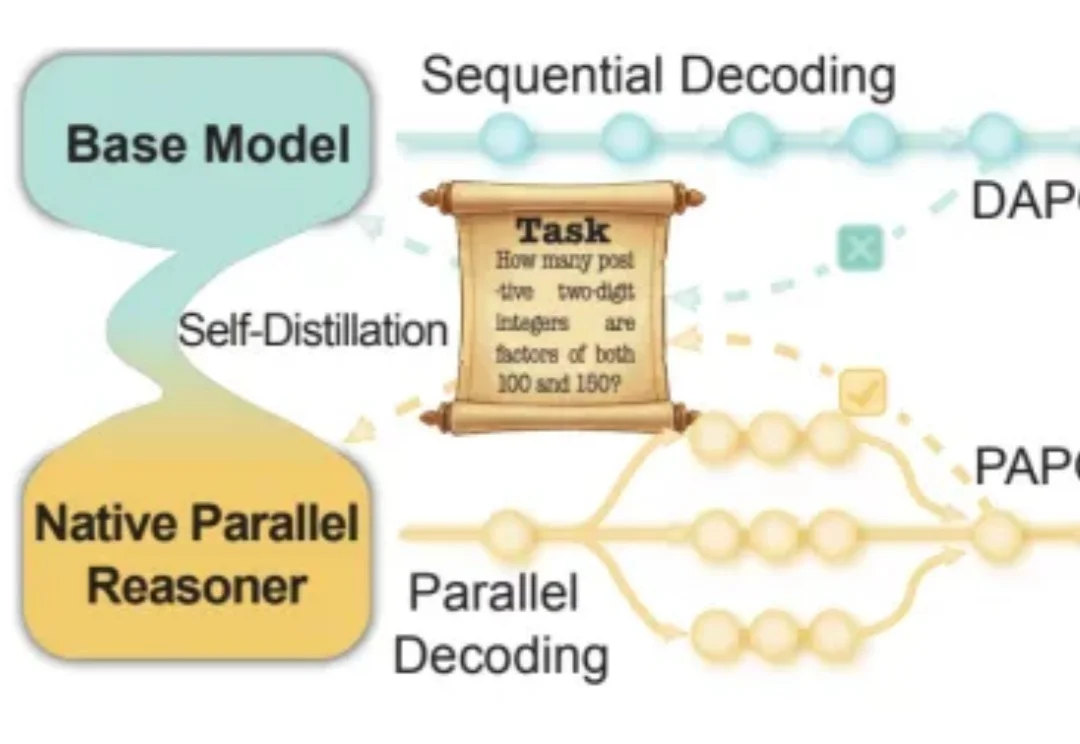
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。

近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。

5月7日,罗氏宣布收购数字病理学公司PathAI,旨在显著加强这家瑞士医疗巨头在 AI 驱动的数字病理学领域的地位。本次收购罗氏将支付 7.5 亿美元的首付款以及高达 3 亿美元的里程碑付款来收购 PathAI,交易总估值潜在达到10.5 亿美元。

在MU Shanghai组织的ClawCon活动上,OpenClaw的社区核心成员自己飞过来,在阿里中心的会议室里,面对着从全国各地赶来的开发者、创业者和用户,和他们一线交流。我们拿到了两个独家对话的机会,受访者是OpenClaw核心维护者Josh,以及OpenClaw Foundation核心成员Vincent Koc。