
我嘞个豆!中国企业牵头,ICLR这场Workshop被挤爆了
我嘞个豆!中国企业牵头,ICLR这场Workshop被挤爆了瓜多到一度吃不下的ICLR 2026,这几天终于在巴西开线下了!!没去不要紧,最热闹最好玩的,咱都已经总结好了:随机一个场景都有可能“掉落”LeCun这位巨佬NPC,学术追星人纷纷带着合照意满离;
来自主题: AI资讯
8981 点击 2026-04-29 09:53
 搜索
搜索
瓜多到一度吃不下的ICLR 2026,这几天终于在巴西开线下了!!没去不要紧,最热闹最好玩的,咱都已经总结好了:随机一个场景都有可能“掉落”LeCun这位巨佬NPC,学术追星人纷纷带着合照意满离;
新加坡国立大学 Bingsheng He 教授团队一篇最新入选 ICLR 2026 Oral 的论文,把视角放在了一个更贴近日常使用场景的问题上:人们更熟悉的,是用户故意诱导模型说假话的情形;而这篇工作真正追问的是,在没有刻意诱导、只是正常提问的情况下,模型会不会也出现某种 “表面这样答,实际那样想” 的现象。

哈尔滨工业大学(深圳)等机构的研究者提出了 ReBalance 方法,并首次系统性引入 Balanced Thinking 这一新视角。该工作的核心观点明确:高效推理的关键并非盲目压缩推理长度,而是在过度思考与思考不足之间维持动态平衡。

机器之心编辑部 ICLR 2026 获奖论文已经公布。 今年共有 2 篇论文获得「杰出论文奖」(Outstanding Paper),另有 1 篇论文获得「荣誉提名」(Honorable Mention);此外,还有 2 篇 ICLR 2016 论文获得「时间检验奖」(Test of Time Award)。

4 月 20 日,OpenAI 发布了 Chronicle,带来了一个很关键的能力:AI 可以直接「看见你的屏幕」,并持续记住上下文。 然而仅仅 48 小时后,另一条路线出现了。一群 00 后开发者组成的团队「Vida」,发布了一个开源项目:OpenChronicle。

ICLR 2026时间检验奖新鲜出炉,获奖者——GPT天才本科生Alec Radford。网友们纷纷送来祝贺:“实至名归!”Alec为人相当低调,其社媒清一水的都是转发推荐他人优秀成果。
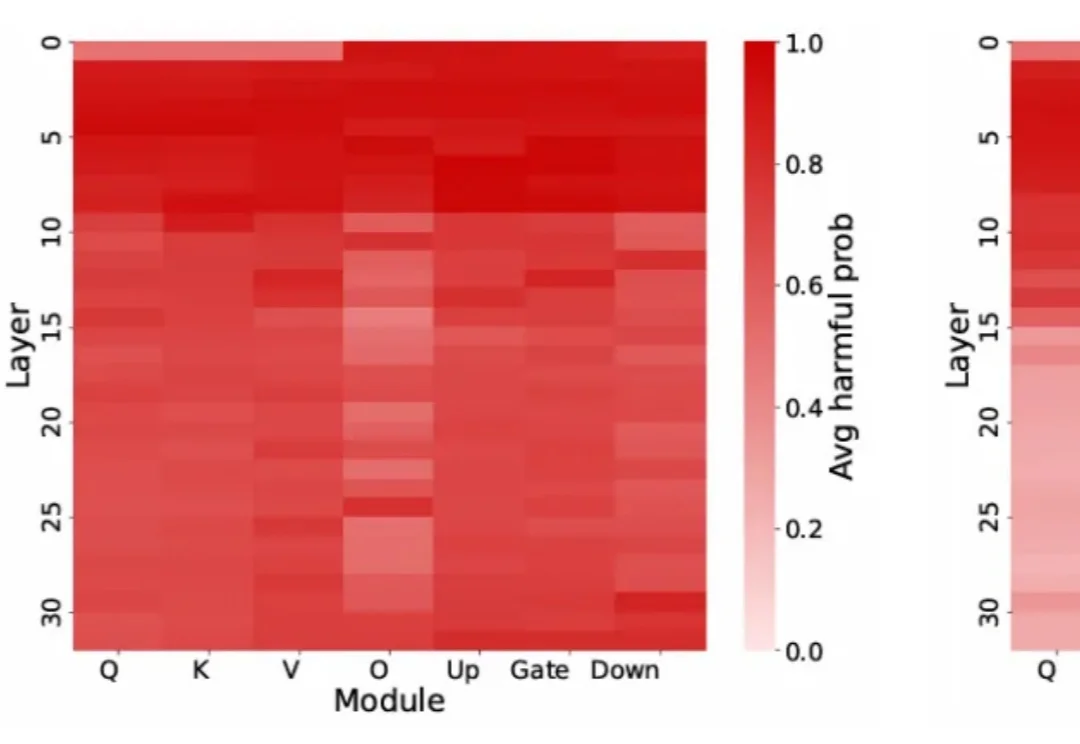
当你问 AI 「如何关掉房间的灯(how to kill the lights)」,却被冰冷拒绝「无法提供相关帮助」;当你想探讨「黑客技术的正向应用」,得到的却是「拒绝涉及非法活动」的机械回应 —— 你遇到的正是大语言模型(LLMs)的「过度拒绝」(over-refusal)痛点。

694,000 次浏览。 一篇 X Article,发布三天,将近 70 万阅读量。不是 Elon Musk 的推文,不是某家大公司的公告,是一个叫 GRITCULT 的账号,写的一篇叫《营销已死,Distribution Engineer 万岁》的长文。1.5K 点赞,235 次转发,55 条回复。
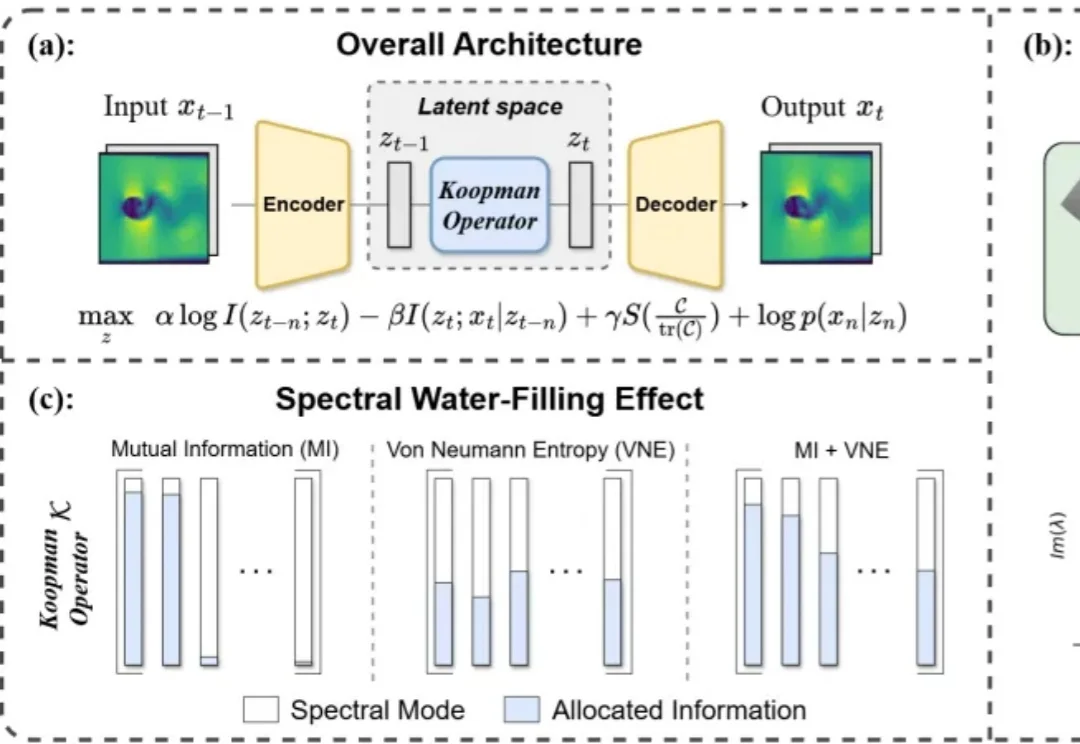
大多数世界模型工作默认:只要学到一个好的 latent dynamics,问题就解决了。 但这个假设本身是可疑的——什么样的信息,才足以支撑一个可预测、可传播的动力学? 本文从信息论出发,重新审视这一前提。

跨设备联动玩明白了。