
谷歌沉默,ICLR 未回应!TurboQuant 争议背后,大厂学术霸权该如何破局?
谷歌沉默,ICLR 未回应!TurboQuant 争议背后,大厂学术霸权该如何破局?AI 论文之争,本质是话语权之争。
来自主题: AI资讯
8111 点击 2026-03-31 14:39
 搜索
搜索
AI 论文之争,本质是话语权之争。
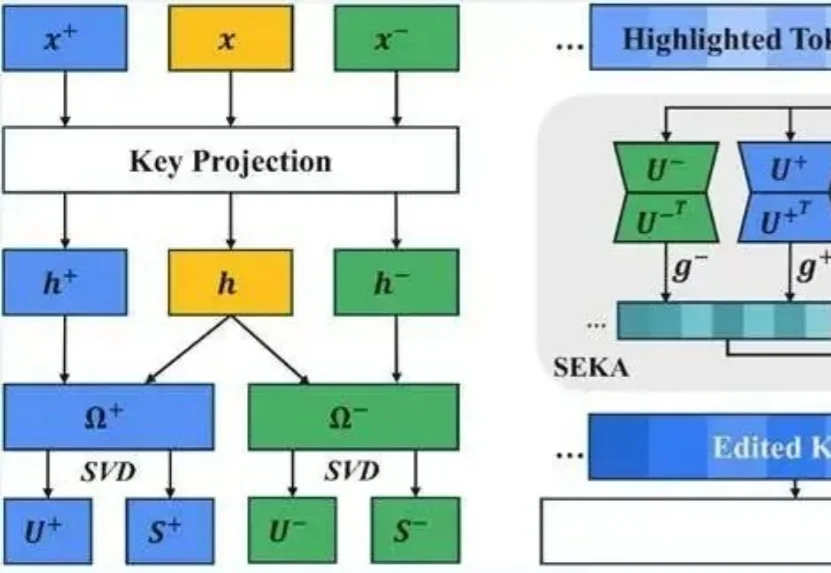
想让大模型重点关注提示词里的某句话可没那么容易。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。
在生成式 AI 领域,视觉分词器(Visual Tokenizer)通常采用固定压缩率 —— 无论是单调的监控画面,还是复杂的动作大片,都被切分为等量的 Token。这种 "一刀切" 的做法不仅会造成巨大的计算冗余,也产生了 “信息量” 不同的 Token,不利于下游理解生成任务处理。
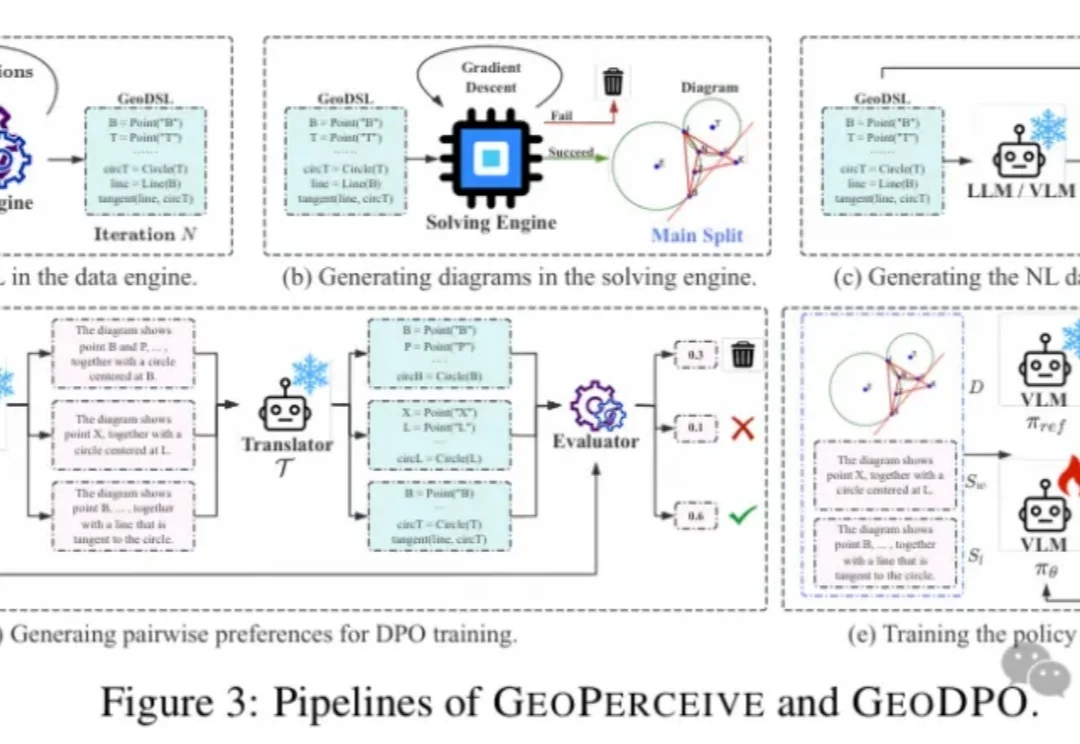
几何问题,真的只是“推理难”吗?

本文综合北京大学王选计算机研究所发布的 ProactiveVideoQA 和 MMDuet2 两篇论文,介绍视频多模态大模型如何实现 “主动交互”—— 在视频播放过程中自主决定何时发起回复,而非等待用户提问。ProactiveVideoQA 提出评估指标和 benchmark,MMDuet2 则通过强化学习训练方法实现了 SOTA 性能,无需精确的回复时间标注即可训练出及时、准确的主动交互模型。
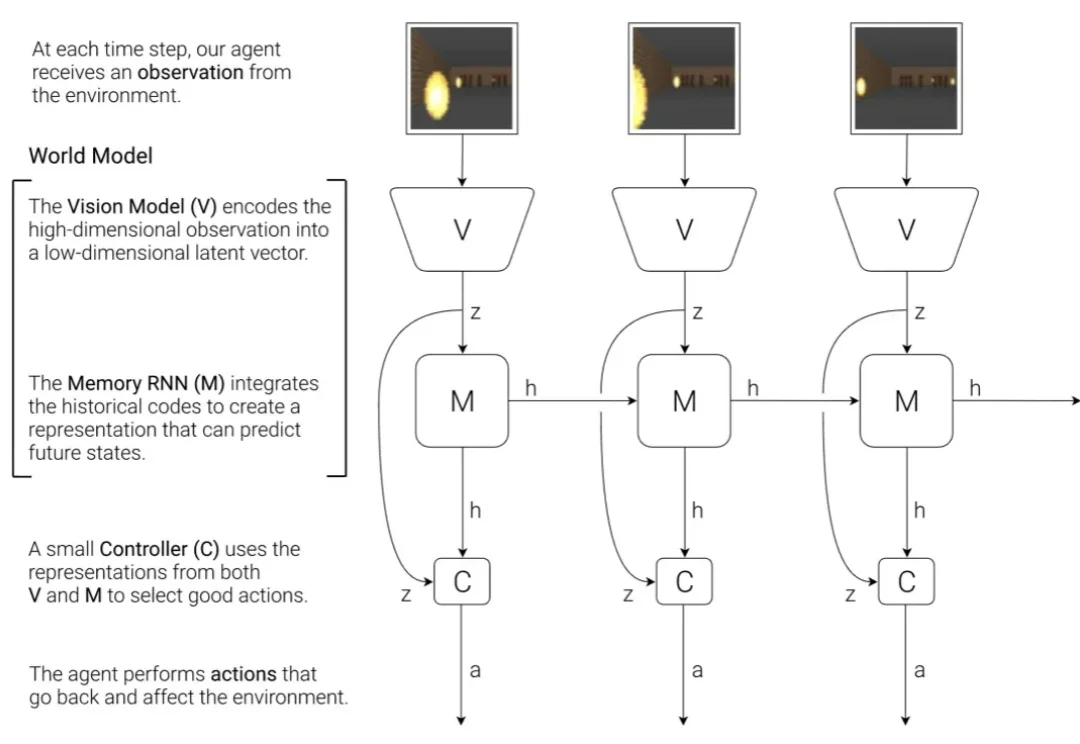
当世界模型越来越大,真正制约它走向「内部模拟器」的,未必是表征能力,而可能是动力学建模。

ICLR'26新研究CPiRi打破时序预测僵局:用冻结底座提取时序特征,轻量模块专注学习通道间真实关系,不靠位置编码「背答案」。测试中通道乱序性能零波动,仅用25%数据即可泛化至全网络,真正实现鲁棒与精准双赢。
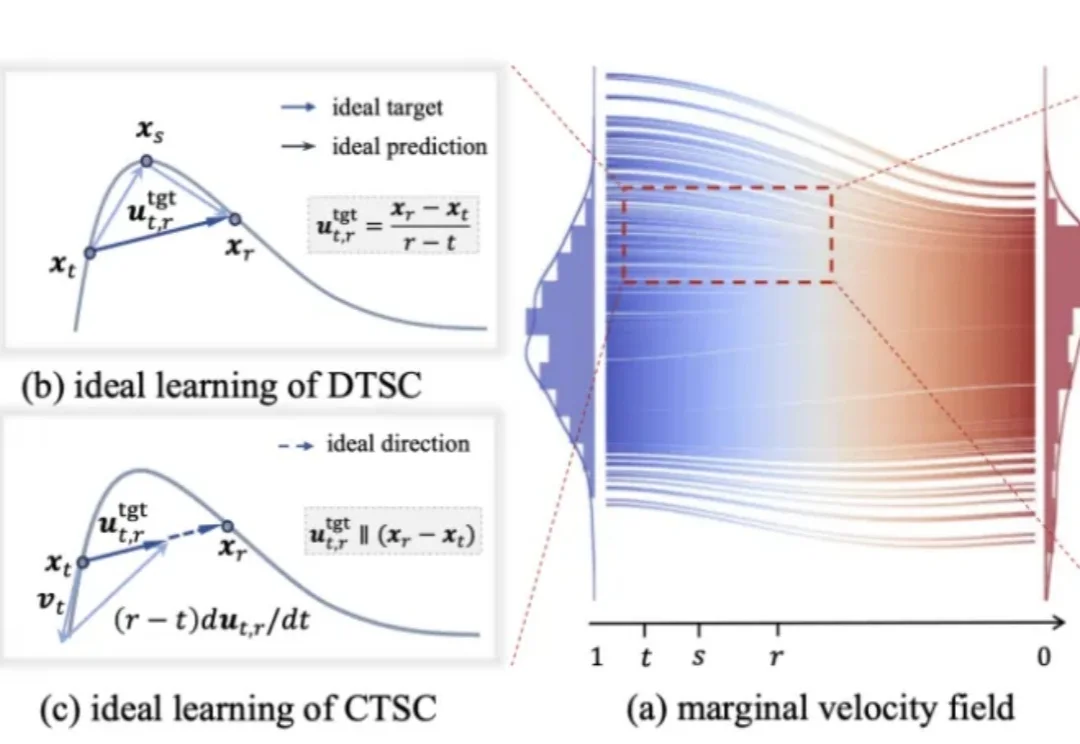
近期,基于捷径化概率流路径(shortcut probability flow trajectory)并从头训练的一步扩散生成模型,展现出强大的实证有效性。然而,这类方法的提出通常建立在较为复杂的理论推导之上,并且往往与具体实现细节高度耦合。这带来一个直接的问题:究竟哪些设计是方法成立的本质要素,哪些又只是可以灵活替换的实现组件。

苦于AI单字拼凑没行气,或是排版秒变“鬼画符”?