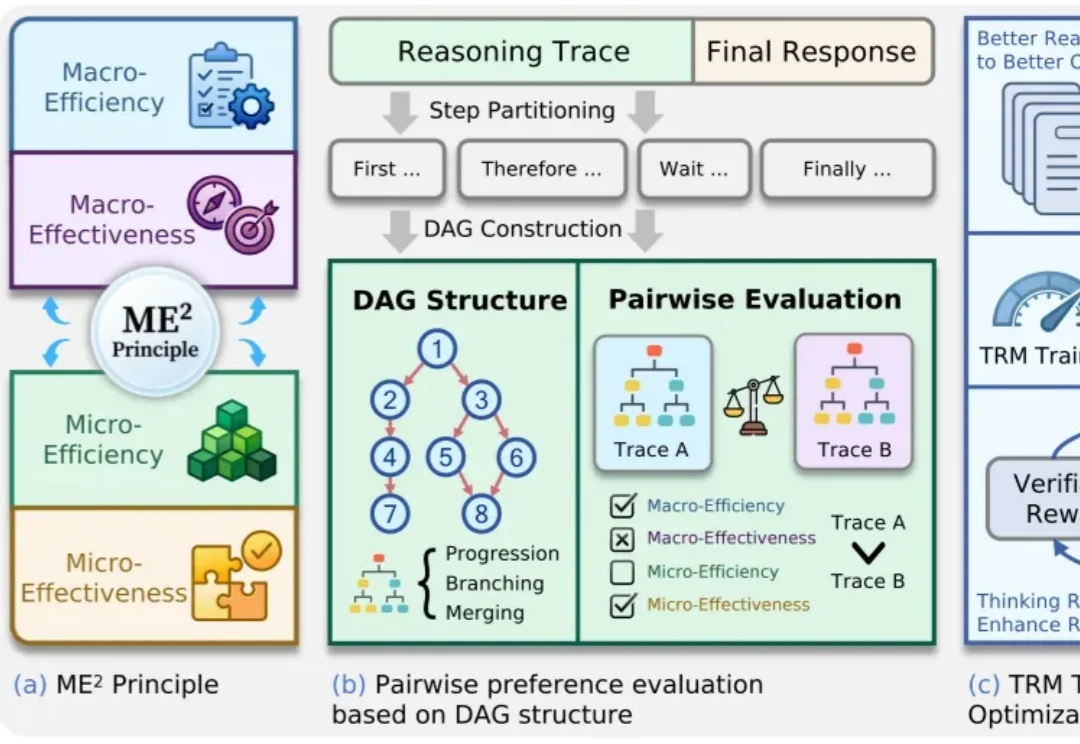
TRM思考奖励模型上线,大模型推理质量终于能量化了 | ICML‘26 Oral
TRM思考奖励模型上线,大模型推理质量终于能量化了 | ICML‘26 Oral大模型推理能力越来越强,但答案对了,思考过程就一定好吗?
来自主题: AI技术研报
5724 点击 2026-06-24 16:03
 搜索
搜索
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?
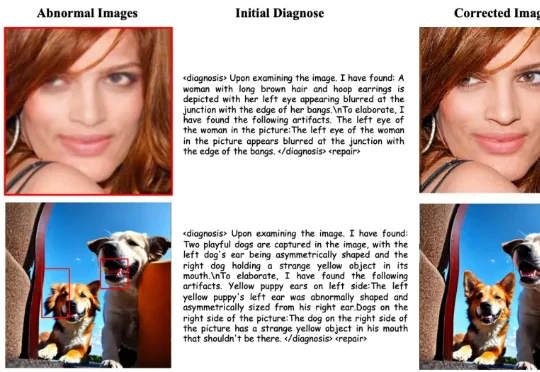
对于 AI 生成图像中可能存在的不自然伪影,我们是否不仅能够将其定位和解释,还能进一步对其进行修复,使图像恢复为更加真实、自然的视觉外观?围绕这一问题,来自北京大学等机构的研究者提出了 GenShield:一个统一的自回归框架,将 AI 生成图像检测 与 图像伪影修复 结合到同一个闭环中,实现从 “诊断” 到 “修复” 的一体化建模。
多智能体系统正在从学界走向业界。 在 Coding、Research 等真实场景里,越来越多系统不再只依赖单个 agent,而是由多个 Agent 分工协作:有人负责规划,有人负责检索,有人调用工具,
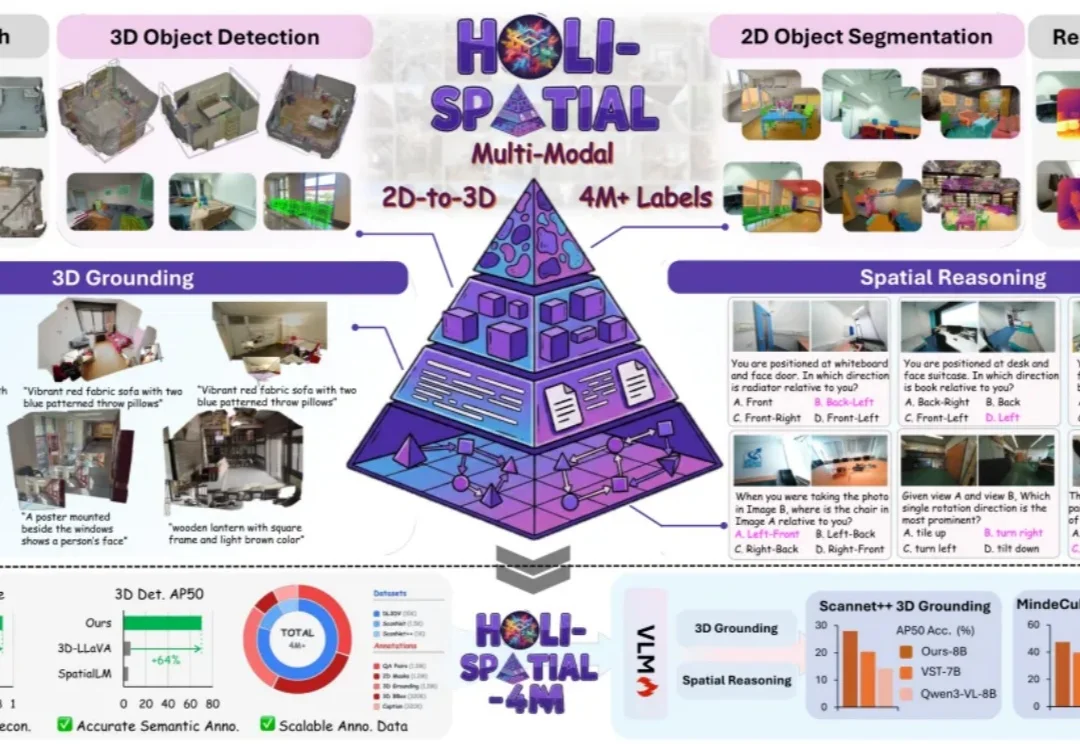
从原始视频出发,无需人工介入,自动生成 3D 重建、深度、2D mask、3D 框、实例描述、3D grounding 和空间问答。Holi-Spatial 试图把「空间智能」的数据生产,推进到自动化、可扩展的新阶段。
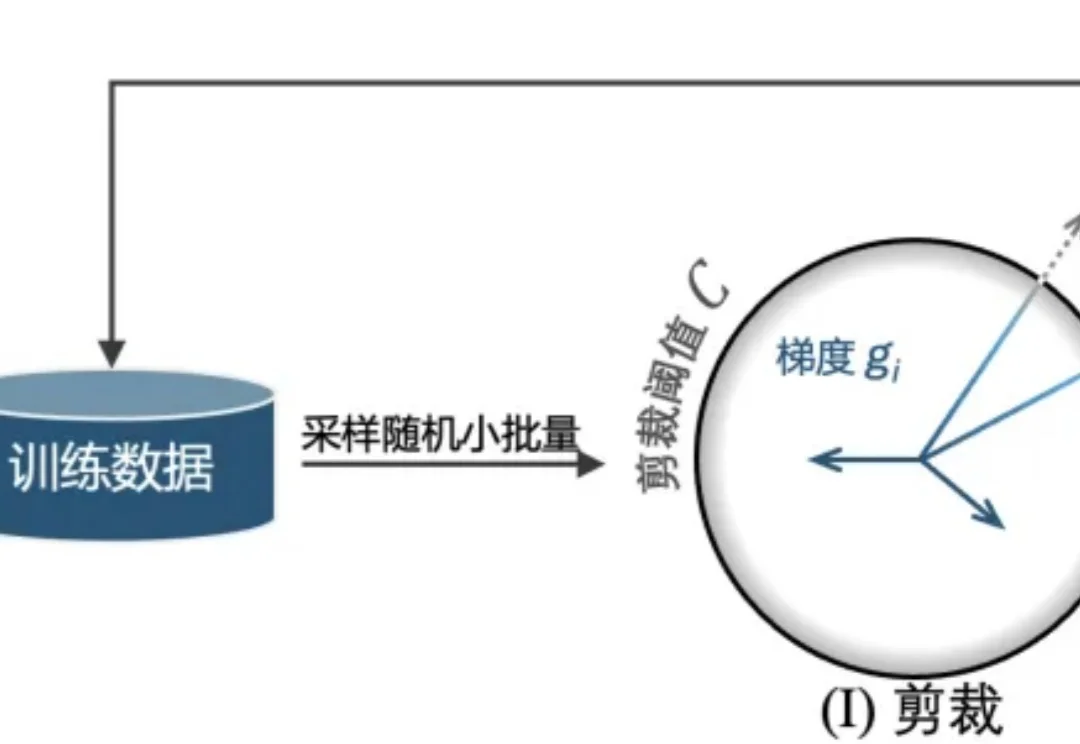
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。
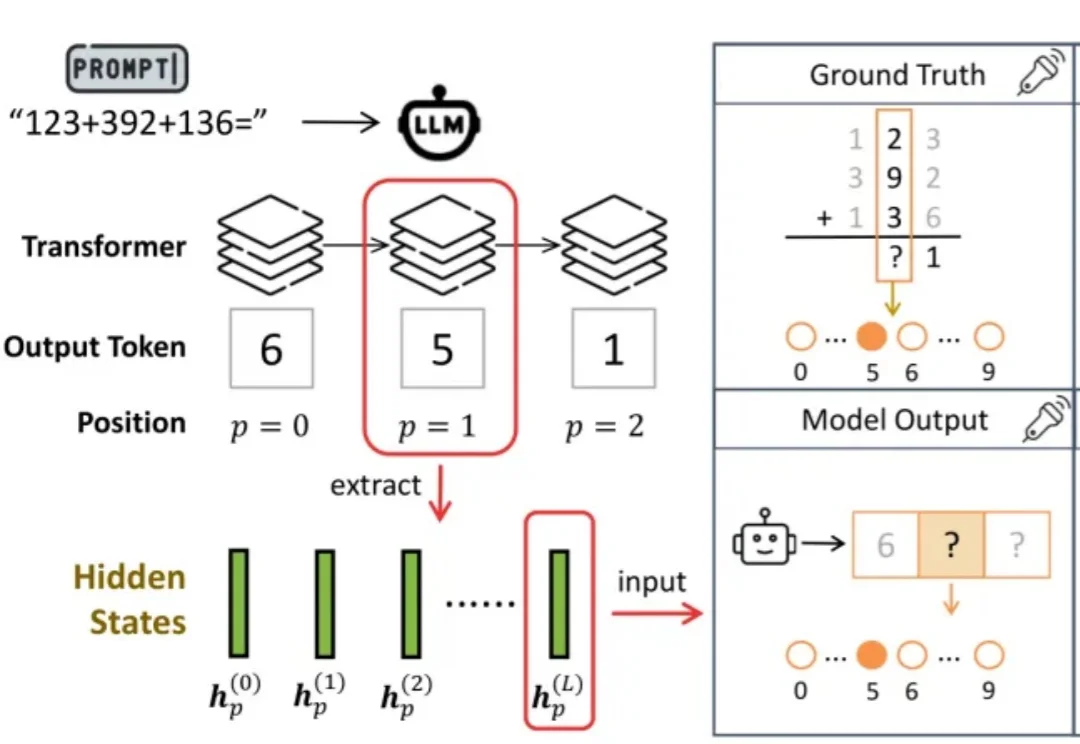
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。
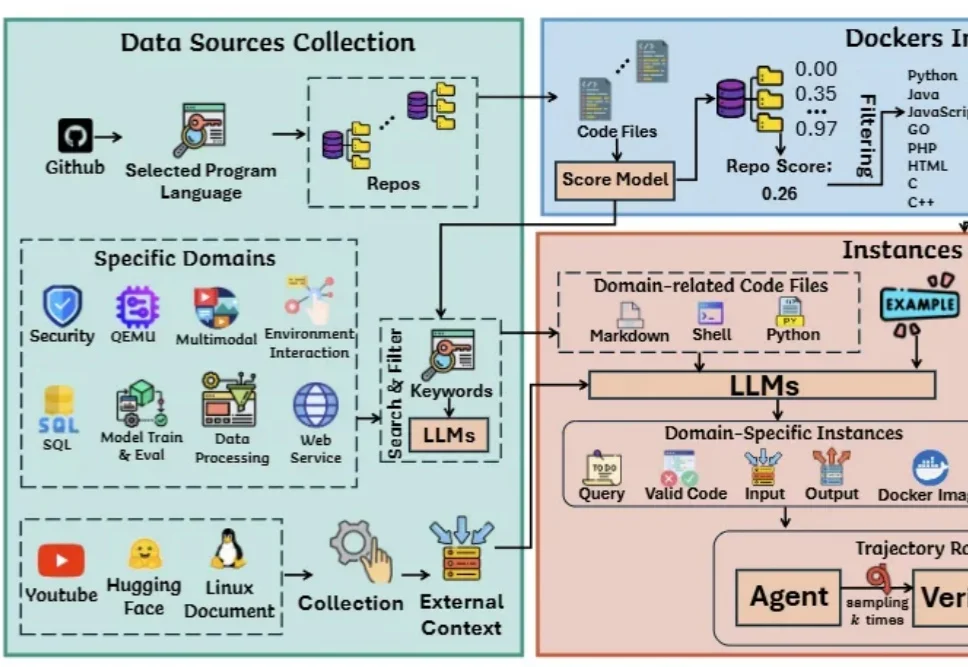
被ICML 2026接收为Spotlight!
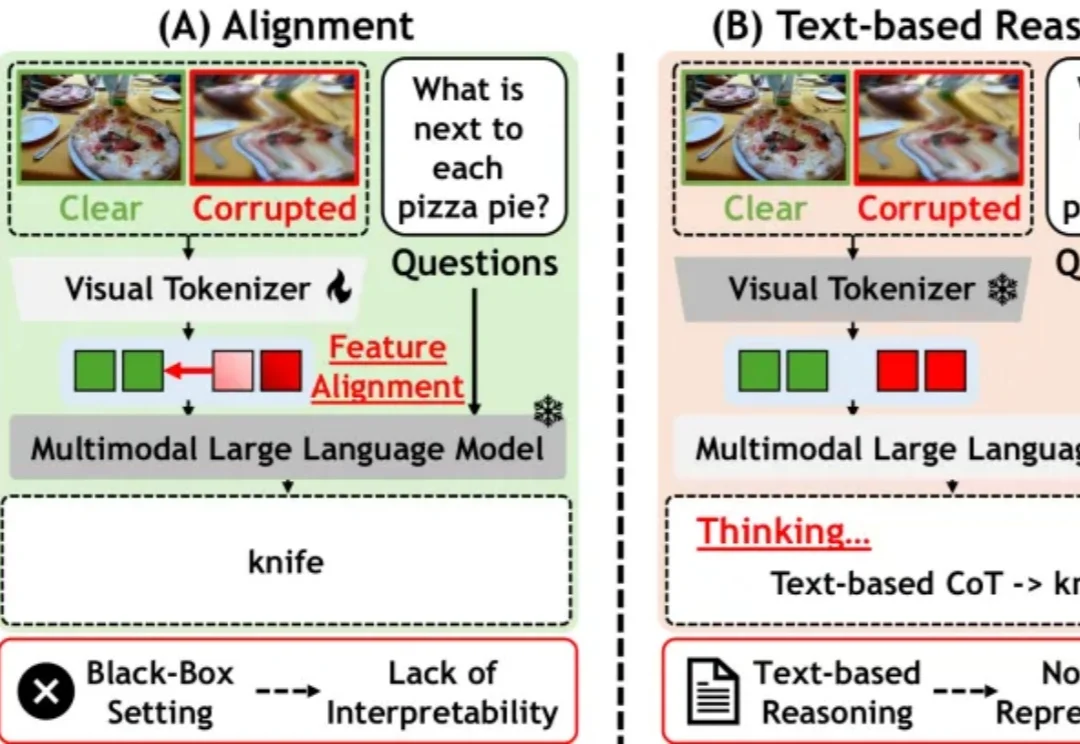
雨雪、雾霾、镜头噪点、压缩失真、夜间弱光……
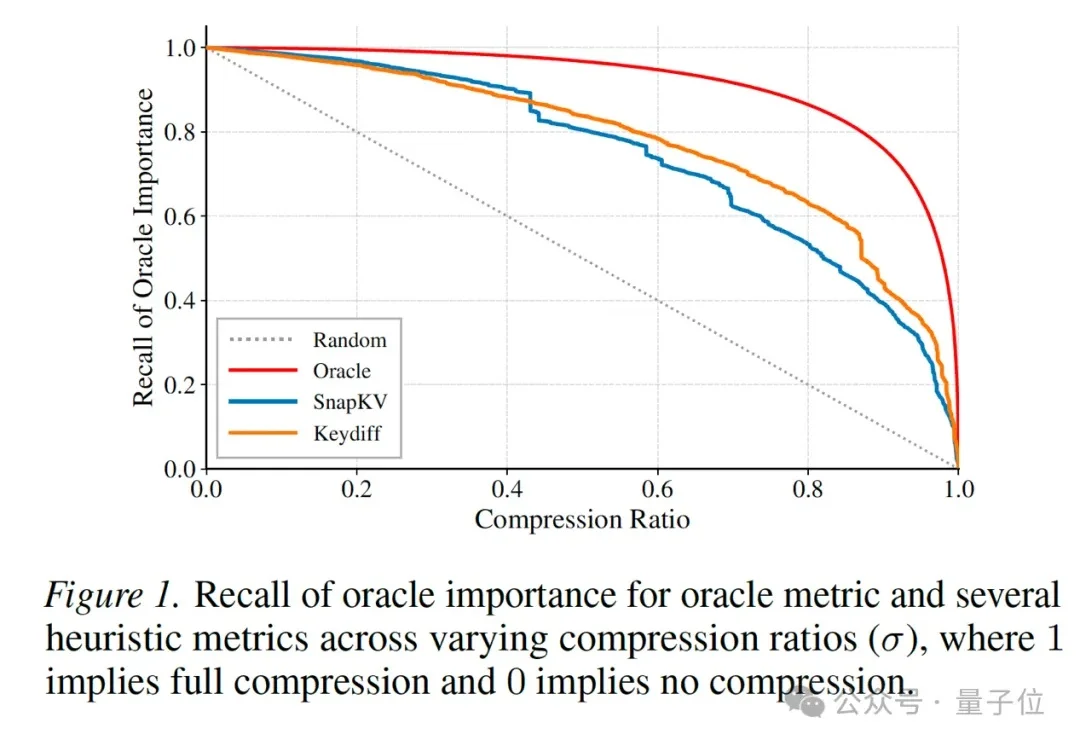
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。