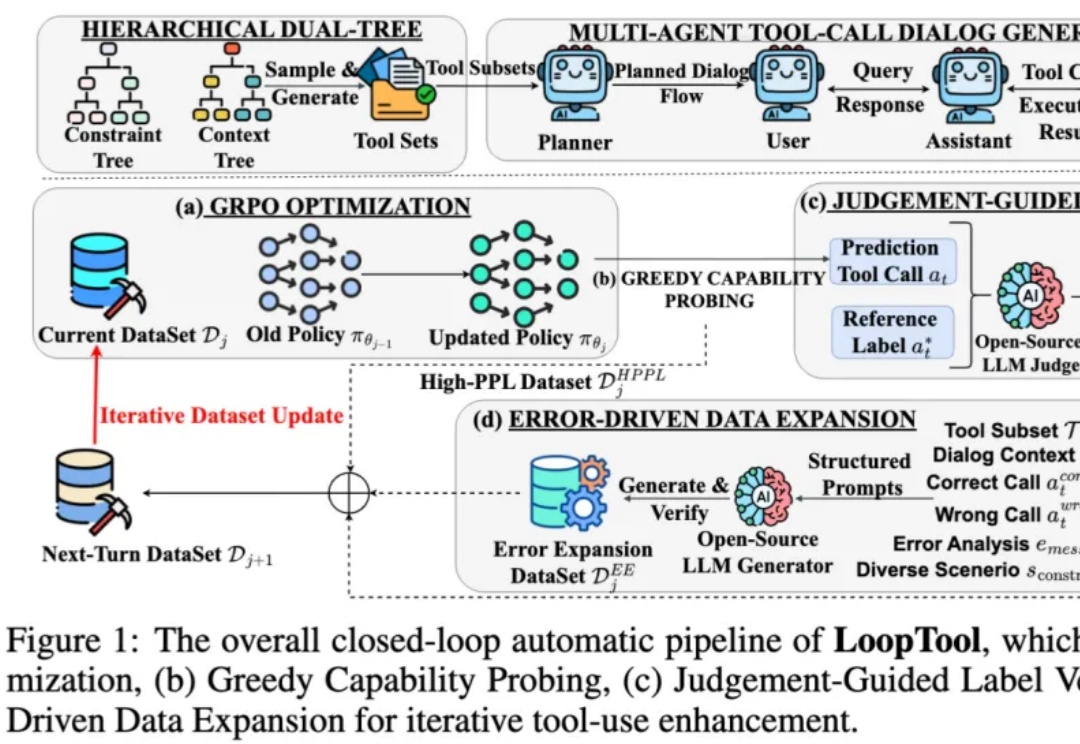
Karpathy组建大模型「议会」,GPT-5.1、Gemini 3 Pro等化身最强智囊团
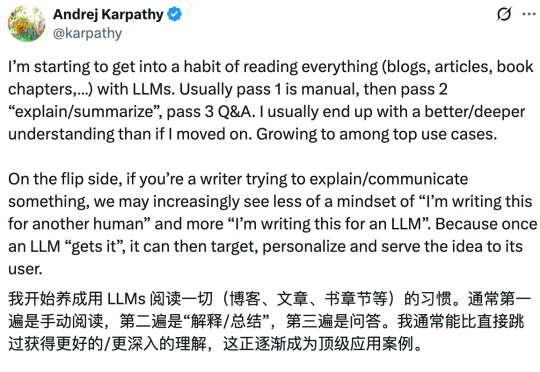
Karpathy组建大模型「议会」,GPT-5.1、Gemini 3 Pro等化身最强智囊团前 OpenAI 联合创始人、特斯拉 AI 总监 Andrej Karpathy 也一样。他在前几天发推,说自己「开始养成用 LLM 阅读一切的习惯」。Karpathy 在周六用氛围编程做了个新的项目,让四个最新的大模型组成一个 LLM 议会,给他做智囊团。
来自主题: AI资讯
10593 点击 2025-11-23 19:39