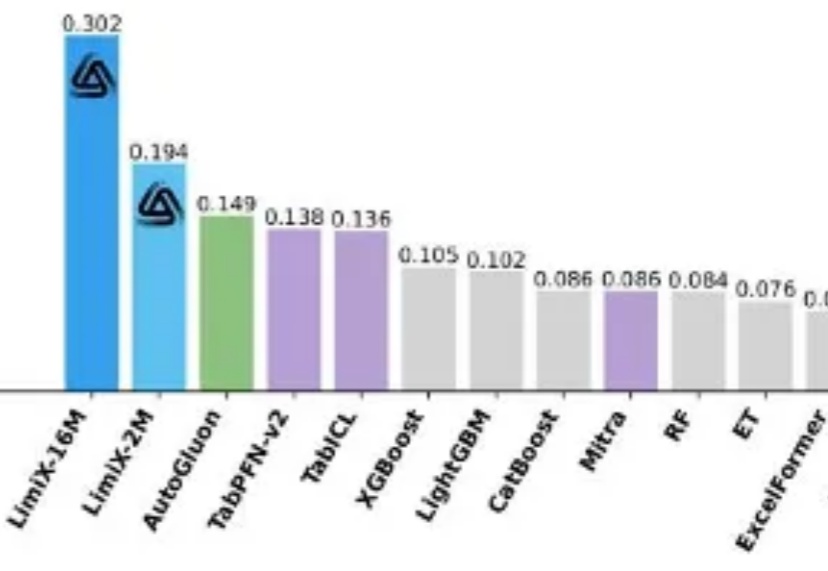
2M大小模型定义表格理解极限,清华大学崔鹏团队开源LimiX-2M
2M大小模型定义表格理解极限,清华大学崔鹏团队开源LimiX-2M提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。
来自主题: AI技术研报
10510 点击 2025-11-13 15:22
 搜索
搜索
提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。
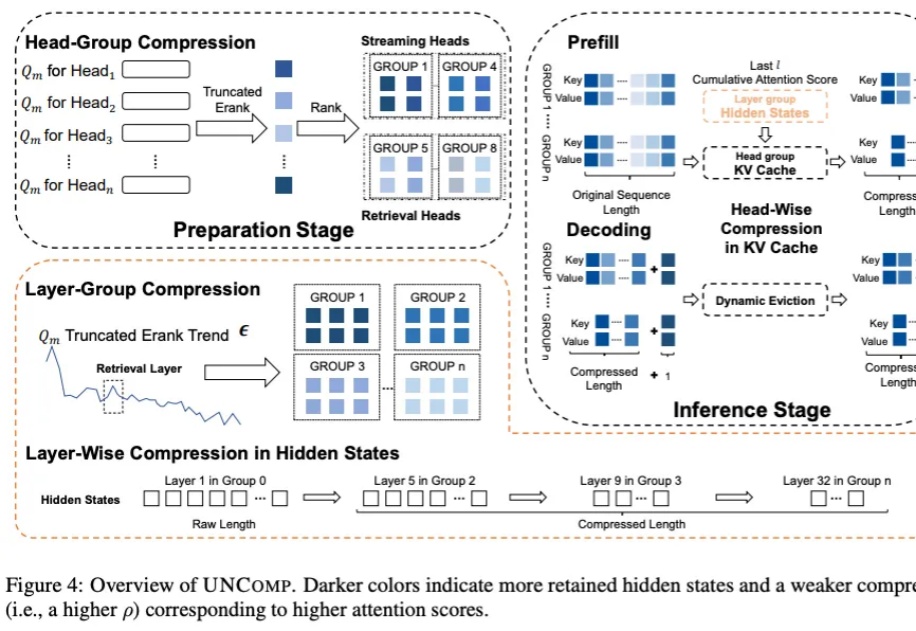
我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的「检索头」和「检索层」?
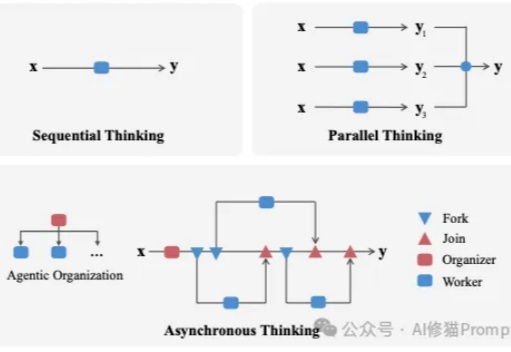
我们长期把LLM当成能独闯难关的“单兵”,在很多任务上,这确实有效。
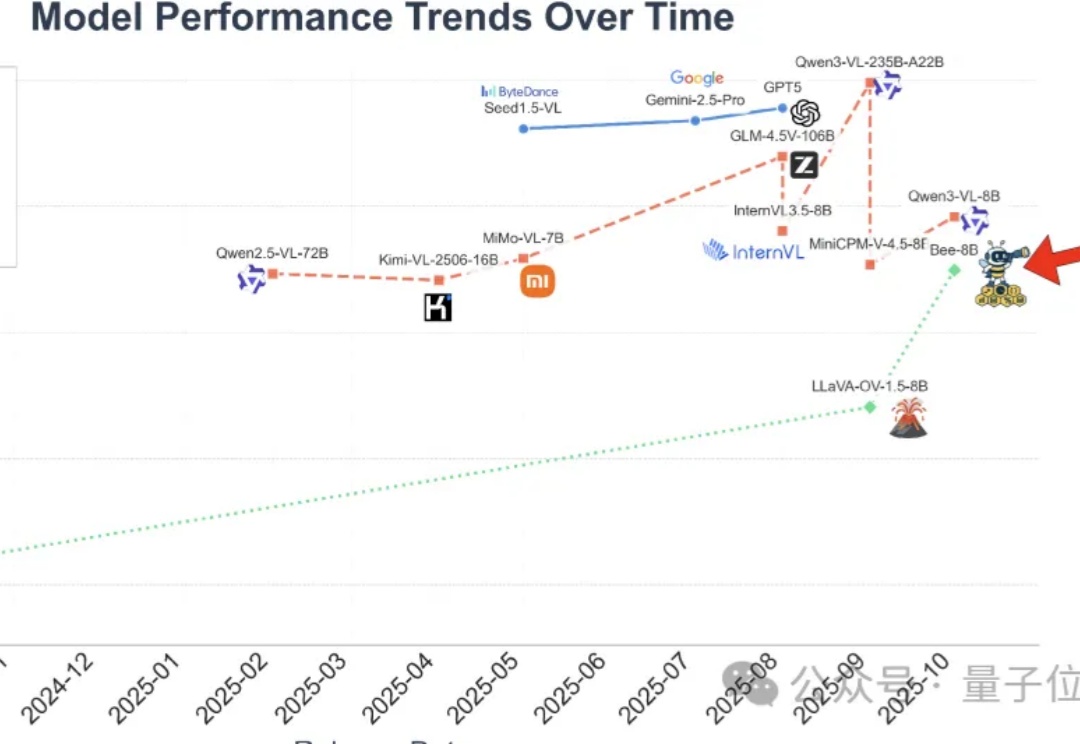
全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。

近期,阿里巴巴 ROLL 团队(淘天未来生活实验室与阿里巴巴智能引擎团队)联合上海交通大学、香港科技大学推出「3A」协同优化框架 ——Async 架构(Asynchronous Training)、Asymmetric PPO(AsyPPO)与 Attention 机制(Attention-based Reasoning Rhythm),
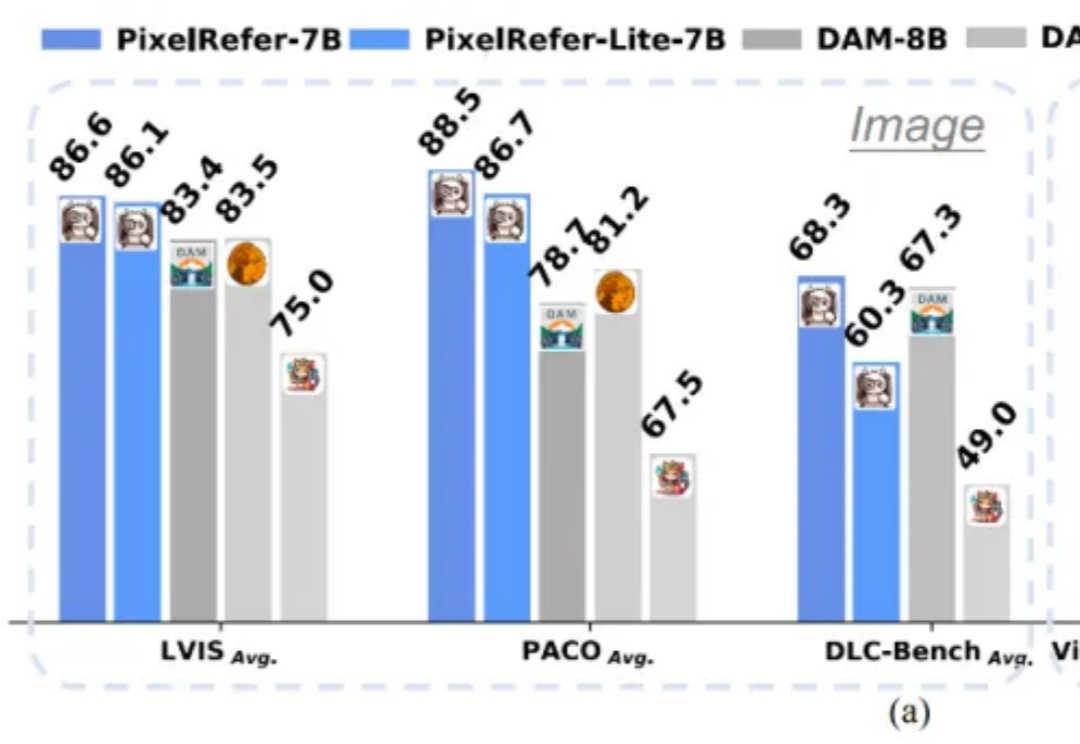
多模态大模型(MLLMs)虽然在图像理解、视频分析上表现出色,但多停留在整体场景级理解。

在处理短文本时,大语言模型(LLM)已经表现出惊人的理解和生成能力。但现实世界中的许多任务 —— 如长文档理解、复杂问答、检索增强生成(RAG)等 —— 都需要模型处理成千上万甚至几十万长度的上下文。
近期,HuggingFace 发布的超过 200 页的超长技术博客,系统性地分享训练先进 LLM 的端到端经验。

LLM Agent 正以前所未有的速度发展,从网页浏览、软件开发到具身控制,其强大的自主能力令人瞩目。然而,繁荣的背后也带来了研究的「碎片化」和能力的「天花板」:多数 Agent 在可靠规划、长期记忆、海量工具管理和多智能体协调等方面仍显稚嫩,整个领域仿佛一片广袤却缺乏地图的丛林。
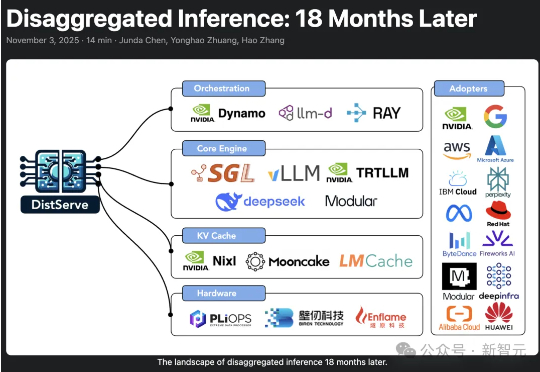
2024年,加州大学圣地亚哥分校「Hao AI Lab」提出了DistServe的解耦推理理念,短短一年多时间,迅速从实验室概念成长为行业标准,被NVIDIA、vLLM等主流大模型推理框架采用,预示着AI正迈向「模块化智能」的新时代。