LLM强化学习新框架!UCSD多智能体训练框架让LLM工具调用能力暴增5.8倍
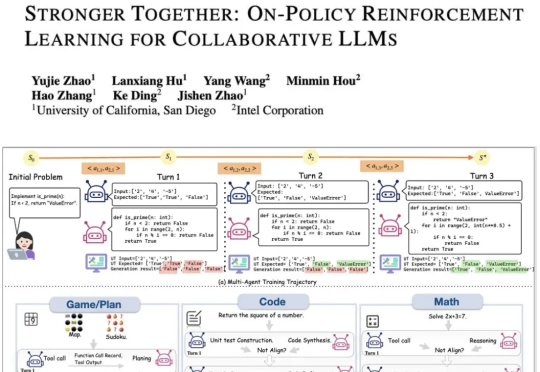
LLM强化学习新框架!UCSD多智能体训练框架让LLM工具调用能力暴增5.8倍现有的LLM智能体训练框架都是针对单智能体的,多智能体的“群体强化”仍是一个亟须解决的问题。为了解决这一领域的研究痛点,来自UCSD和英特尔的研究人员,提出了新的提出通用化多智能体强化学习框架——PettingLLMs。支持任意组合的多个LLM一起训练。
来自主题: AI技术研报
8007 点击 2025-11-09 15:36