AI已学会自我复制!复旦新研究:开源LLM克隆成功率最高90%
AI已学会自我复制!复旦新研究:开源LLM克隆成功率最高90%复旦新研究揭示了AI系统自我复制的突破性进展,表明当前的LLM已具备在没有人类干预的情况下自我克隆的能力。这不仅是AI超越人类的一大步,也为「流氓AI」埋下了隐患,带来前所未有的安全风险。
来自主题: AI技术研报
7357 点击 2025-02-12 12:05
 搜索
搜索
复旦新研究揭示了AI系统自我复制的突破性进展,表明当前的LLM已具备在没有人类干预的情况下自我克隆的能力。这不仅是AI超越人类的一大步,也为「流氓AI」埋下了隐患,带来前所未有的安全风险。

推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。
一篇报道,在AI圈掀起轩然大波。文中引用了近2年前的论文直击大模型死穴——Transformer触及天花板,却引来OpenAI研究科学家的紧急回应。谁能想到,一篇于2023年发表的LLM论文,竟然在一年半之后又「火」了。
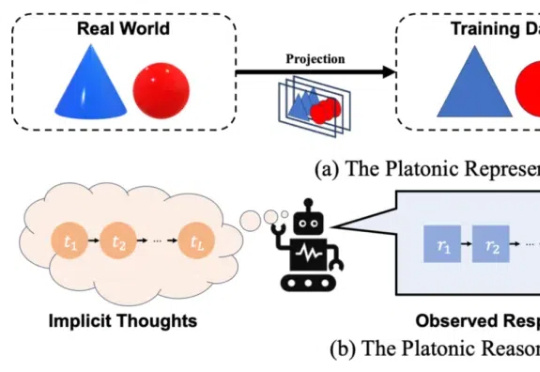
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。
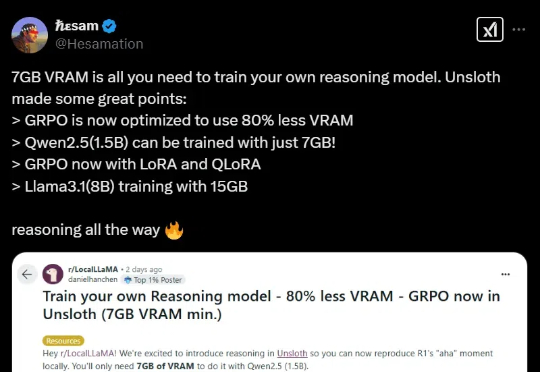
黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO训练的内存使用减少了80%!只需7GB VRAM,本地就能体验AI「啊哈时刻」。
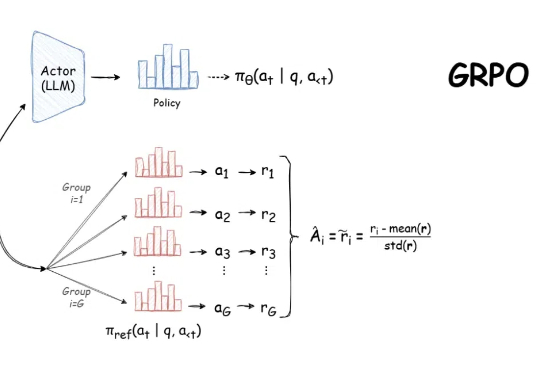
自 DeepSeek-R1 发布以来,群组相对策略优化(GRPO)因其有效性和易于训练而成为大型语言模型强化学习的热门话题。R1 论文展示了如何使用 GRPO 从遵循 LLM(DeepSeek-v3)的基本指令转变为推理模型(DeepSeek-R1)。
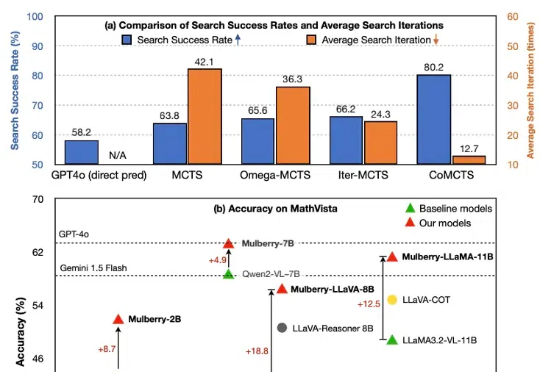
尽管多模态大语言模型(MLLM)在简单任务上最近取得了显著进展,但在复杂推理任务中表现仍然不佳。费曼的格言可能是这种现象的完美隐喻:只有掌握推理过程的每一步,才能真正解决问题。然而,当前的 MLLM 更擅长直接生成简短的最终答案,缺乏中间推理能力。本篇文章旨在开发一种通过学习创造推理过程中每个中间步骤直至最终答案的 MLLM,以实现问题的深入理解与解决。
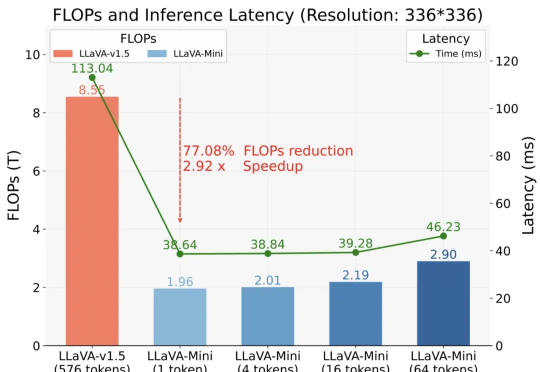
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

关注NLP领域的人们,一定好奇「语言模型能做什么?」「什么是o1?」「为什么思维链有效?」
但这次的情况不太一样:在被称为「新一代国产LLM之光」的大模型背后,我们听到一个特别神奇的,和游戏行业有千丝万缕联系的故事。