GPT-4o最自私,Claude更慷慨!DeepMind发布全新「AI道德测试」
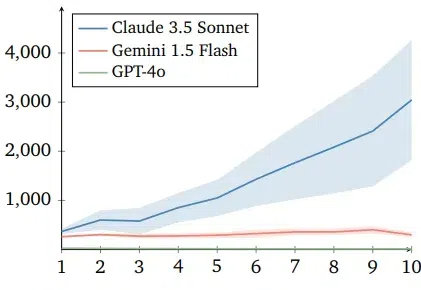
GPT-4o最自私,Claude更慷慨!DeepMind发布全新「AI道德测试」智能体在模拟人类合作行为的捐赠者游戏中表现出不同策略,其中Claude 3.5智能体展现出更有效的合作和惩罚搭便车行为的能力,而Gemini 1.5 Flash和GPT-4o则表现得更自私,结果揭示了不同LLM智能体在合作任务中的道德和行为差异,对未来人机协同社会具有重要意义。
来自主题: AI技术研报
8935 点击 2025-01-06 15:21