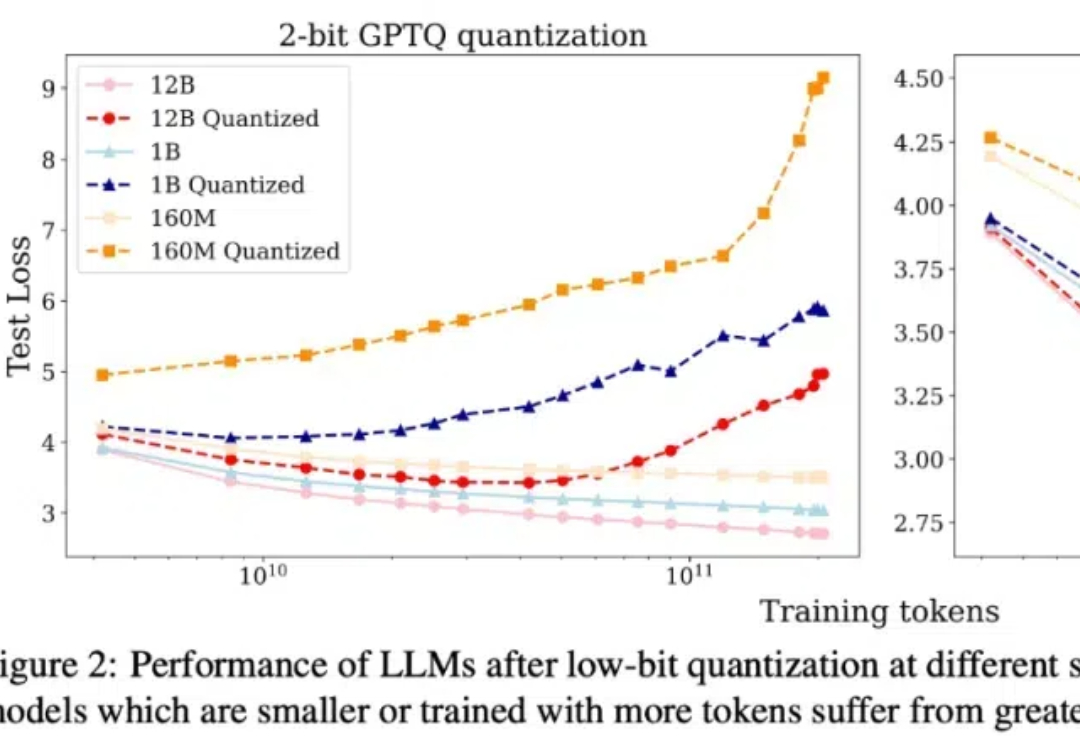
低精度只适用于未充分训练的LLM?腾讯提出LLM量化的scaling laws
低精度只适用于未充分训练的LLM?腾讯提出LLM量化的scaling laws本文介绍了一套针对于低比特量化的 scaling laws。
来自主题: AI技术研报
7818 点击 2024-12-29 17:37
 搜索
搜索
本文介绍了一套针对于低比特量化的 scaling laws。
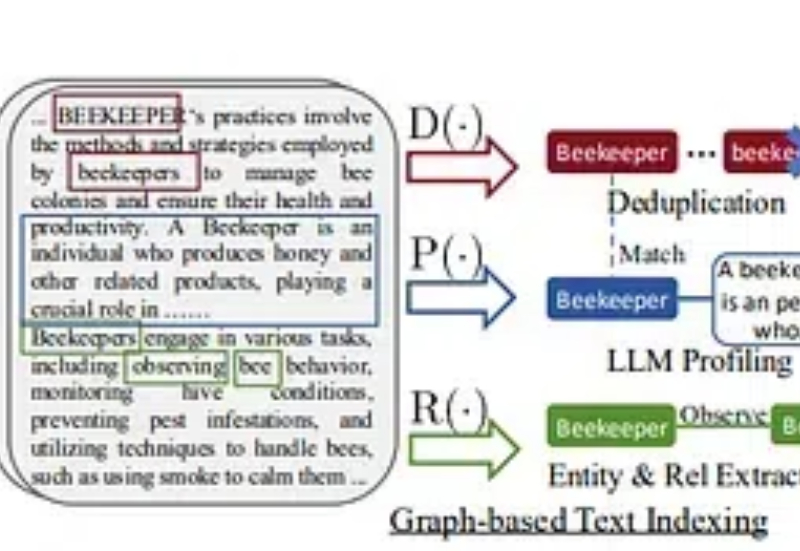
在这个故事中,我将提供一个快速教程,展示如何使用浏览器使用、LightRAG和本地LLM创建一个强大的聊天机器人,以开发一个能够抓取您选择的任何网站的AI代理。此外,您可以询问有关您的数据的问题,这将为您提供该问题的回答。

本月,OpenAI科学家就当前LLM的scaling方法论能否实现AGI话题展开深入辩论,认为将来AI至少与人类平分秋色;LLM scaling目前的问题可以通过后训练、强化学习、合成数据、智能体协作等方法得到解决;按现在的趋势估计,明年LLM就能赢得IMO金牌。

2023年6月,理想汽车推出了自研认知大模型“Mind GPT”,它以“理想同学”App的形式出现在理想汽车的车机中,支持通过自然语言交流、发送指令。2024年,Mind GPT升级到3.0,带来了行业领先的自然语言任务执行功能。

在大语言模型(LLM)蓬勃发展的今天,提示词工程(Prompt Engineering)已经成为AI应用开发中不可或缺的关键环节。
1822 年,电学之父法拉第在日记中写到“既然通电能够产生磁力,为什么不能用磁铁产生电流呢?我一定要反过来试试!”。于是在 1831 年,第一台发电机被发明,推动了人类进入电气化时代。

在当今迅速发展的人工智能时代,大语言模型(LLMs)在各种应用中发挥着至关重要的作用。然而,随着其应用的广泛化,模型的安全性问题也引起了广泛关注。

最近,类 o1 模型的出现,验证了长思维链 (CoT) 在数学和编码等推理任务中的有效性。在长思考(long thought)的帮助下,LLM 倾向于探索、反思和自我改进推理过程,以获得更准确的答案。

2024年,AI Agent称得上最火热的概念。一方面,大模型赛道降温,并呈现出赢家通吃的局面;另一方面,AI Agent则是大模型应用落地的最佳形式,其能够解决LLMs在具体应用场景中的局限性。
近年来,基于大型语言模型(LLMs)的多智能体系统(MAS)已成为人工智能领域的研究热点。