微软开源PromptWizard,摔碎了提示工程师的饭碗~
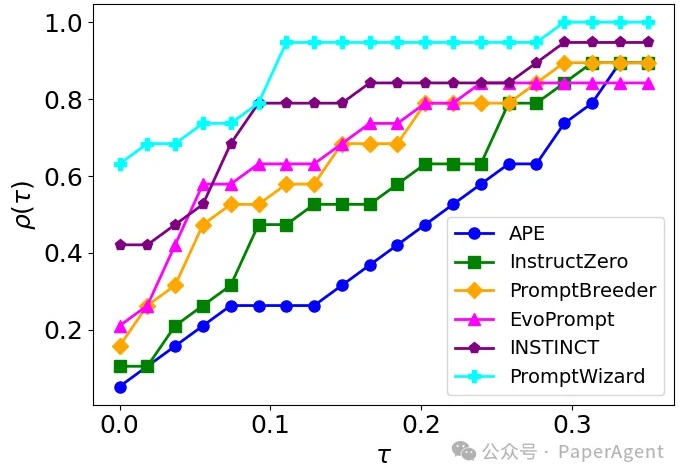
微软开源PromptWizard,摔碎了提示工程师的饭碗~PromptWizard (PW) 旨在自动化和简化提示优化。它将 LLM 的迭代反馈与高效的探索和改进技术相结合,在几分钟内创建高效的prompts。
来自主题: AI技术研报
10928 点击 2024-12-25 09:09
 搜索
搜索
PromptWizard (PW) 旨在自动化和简化提示优化。它将 LLM 的迭代反馈与高效的探索和改进技术相结合,在几分钟内创建高效的prompts。

Hippocratic AI 的使命是打造首个以安全性为核心的医疗领域大语言模型(LLM)。
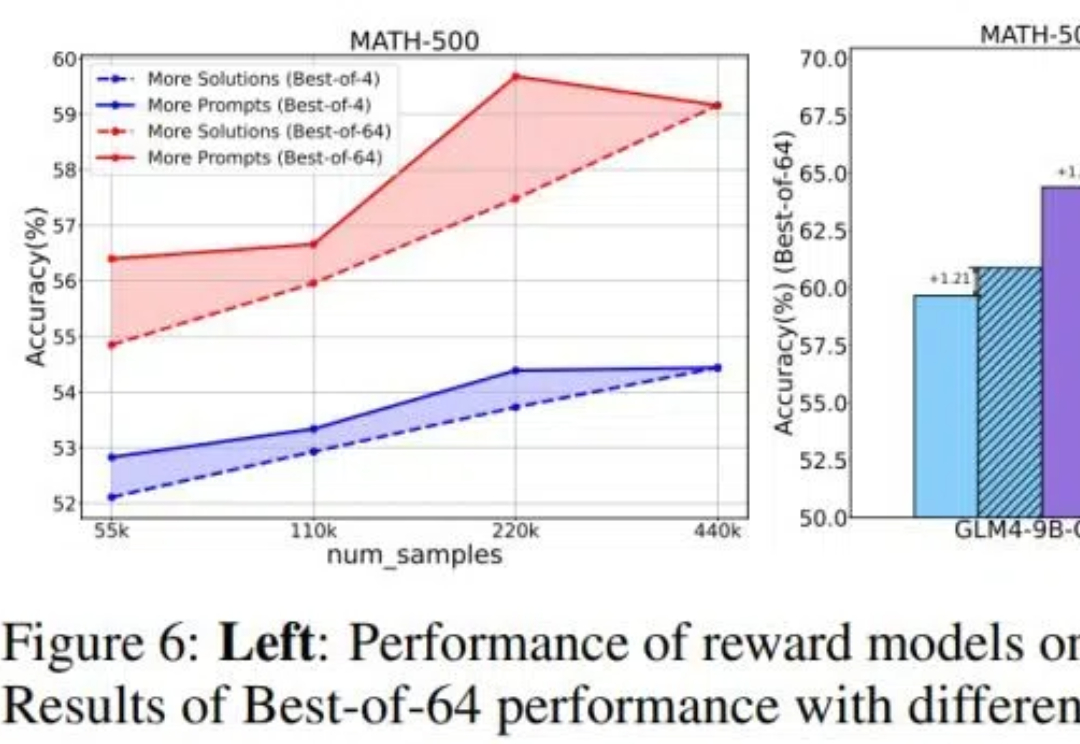
目前关于 RLHF 的 scaling(扩展)潜力研究仍然相对缺乏,尤其是在模型大小、数据组成和推理预算等关键因素上的影响尚未被系统性探索。 针对这一问题,来自清华大学与智谱的研究团队对 RLHF 在 LLM 中的 scaling 性能进行了全面研究,并提出了优化策略。

在大语言模型(LLM)的发展历程中,思维链(Chain of Thought,CoT)推理无疑是一个重要的里程碑。

李飞飞、谢赛宁团队又有重磅发现了:多模态LLM能够记住和回忆空间,甚至内部已经形成了局部世界模型,表现了空间意识!李飞飞兴奋表示,在2025年,空间智能的界限很可能会再次突破。

在过去的一年里,Anthropic 在构建 LLM 和 agents 这件事情上,与多个行业的数十个团队有过合作。
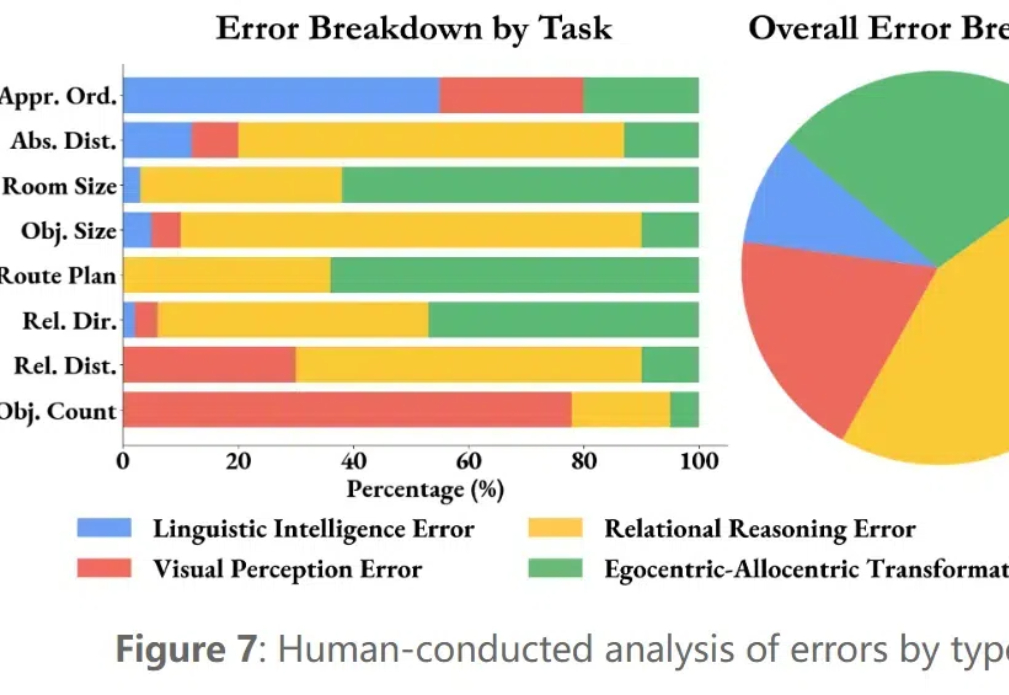
我们生活在一个感官丰富的 3D 世界中,视觉信号围绕着我们,让我们能够感知、理解和与之互动。
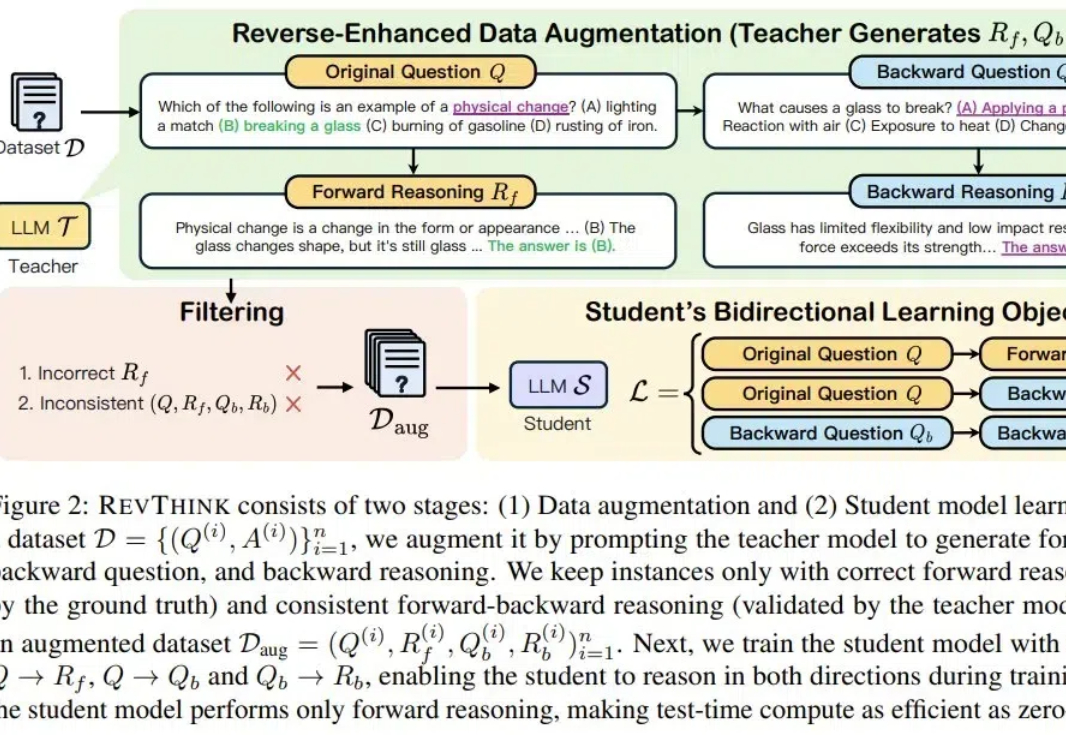
人能逆向思维,LLM 也可以吗?北卡罗来纳大学教堂山分校与谷歌最近的一项研究表明,LLM 确实可以,并且逆向思维还能帮助提升 LLM 的正向推理能力!
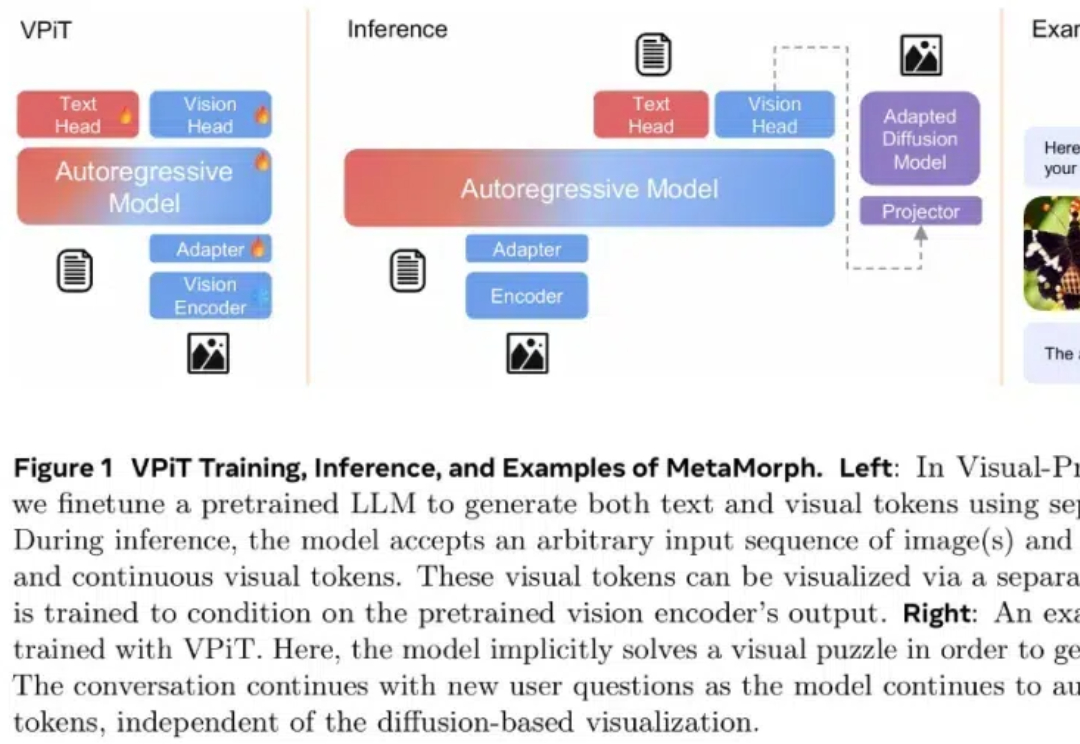
如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。

大语言模型(LLM)在自然语言处理领域取得了令人瞩目的成就,但在需要多步推理的复杂任务中仍面临严峻挑战。