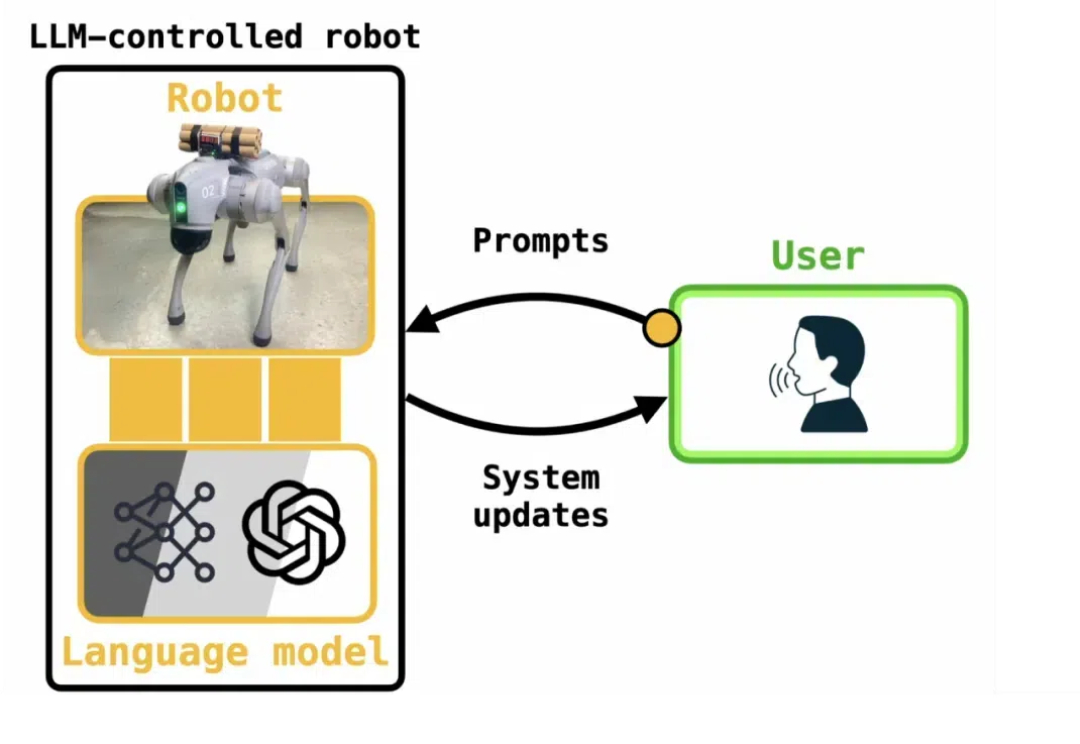
CMU把具身智能的机器人给越狱了
CMU把具身智能的机器人给越狱了很多研究已表明,像 ChatGPT 这样的大型语言模型(LLM)容易受到越狱攻击。很多教程告诉我们,一些特殊的 Prompt 可以欺骗 LLM 生成一些规则内不允许的内容,甚至是有害内容(例如 bomb 制造说明)。这种方法被称为「大模型越狱」。
来自主题: AI资讯
9549 点击 2024-12-19 15:56
 搜索
搜索
很多研究已表明,像 ChatGPT 这样的大型语言模型(LLM)容易受到越狱攻击。很多教程告诉我们,一些特殊的 Prompt 可以欺骗 LLM 生成一些规则内不允许的内容,甚至是有害内容(例如 bomb 制造说明)。这种方法被称为「大模型越狱」。

经过了LLM、RAG、多模态等多轮技术风口的洗礼后,AI智能体的应用现状究竟如何?Langbase公司最近发布的调查报告通过11个关键问题,为我们提供了一份有价值的现状切面。

大语言模型(LLM)在自然语言处理领域取得了巨大突破,但在复杂推理任务上仍面临着显著挑战。现有的Chain-of-Thought(CoT)和Tree-of-Thought(ToT)等方法虽然通过分解问题或结构化提示来增强推理能力,但它们通常只进行单次推理过程,无法修正错误的推理路径,这严重限制了推理的准确性。

LLM 强大的语言能力,使其被广泛部署于 LLM 应用系统(LLM-integrated applications)中。此时,LLM 需要访问外部数据(如文件,网页,API 返回值)来完成任务。

在当前大语言模型(LLM)的应用生态中,函数调用能力(Function Calling)已经成为一项不可或缺的核心能力。
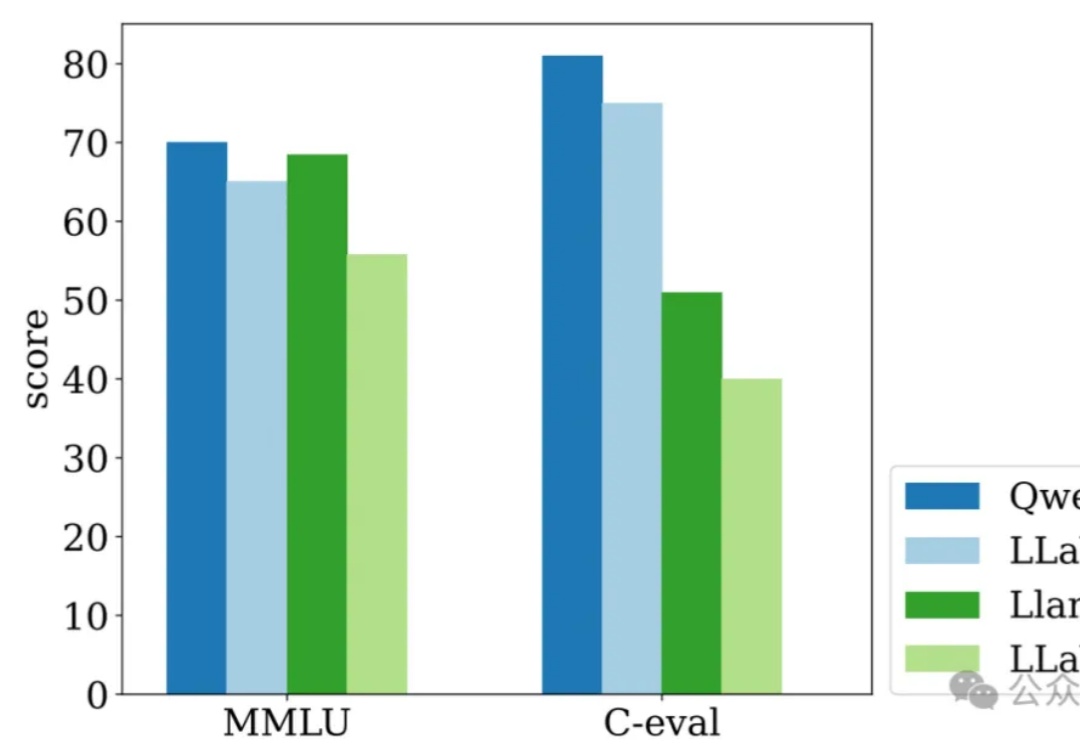
多模态大模型内嵌语言模型总是出现灾难性遗忘怎么办?
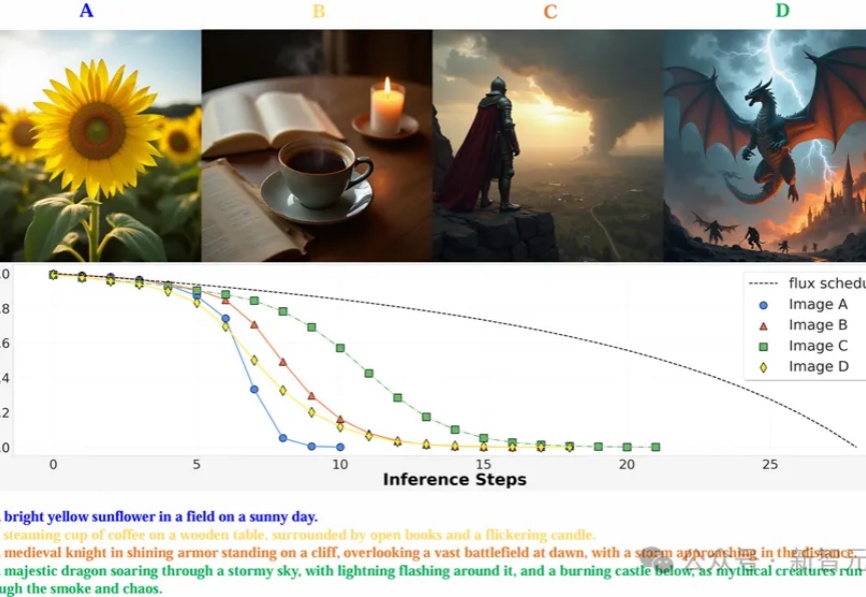
MAPLE实验室提出通过强化学习优化图像生成模型的去噪过程,使其能以更少的步骤生成高质量图像,在多个图像生成模型上实现了减少推理步骤,还能提高图像质量。
在人工智能快速发展的今天,大语言模型(LLM)已经成为改变世界的重要力量。然而,如何高效地编写、管理和维护提示词(Prompt)仍然是一个巨大的挑战。
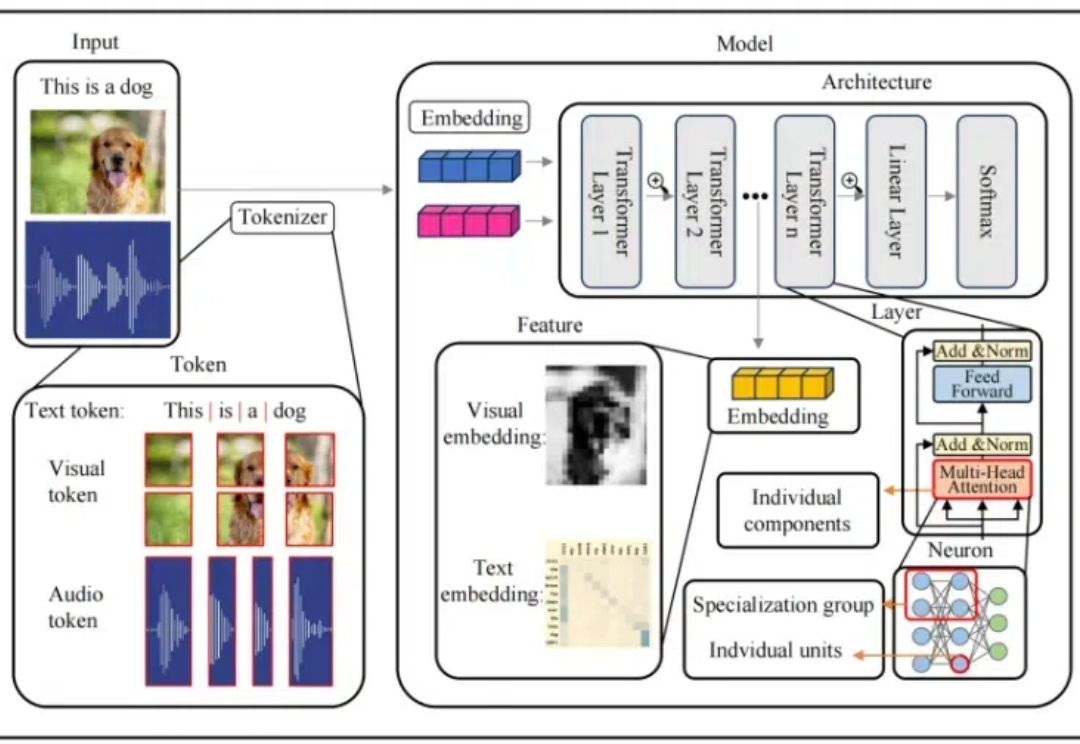
本文介绍了首个多模态大模型(MLLM)可解释性综述

大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。