
Mamba作者新作:将Llama3蒸馏成混合线性 RNN
Mamba作者新作:将Llama3蒸馏成混合线性 RNNTransformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。
来自主题: AI技术研报
9745 点击 2024-08-31 14:54
 搜索
搜索
Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。
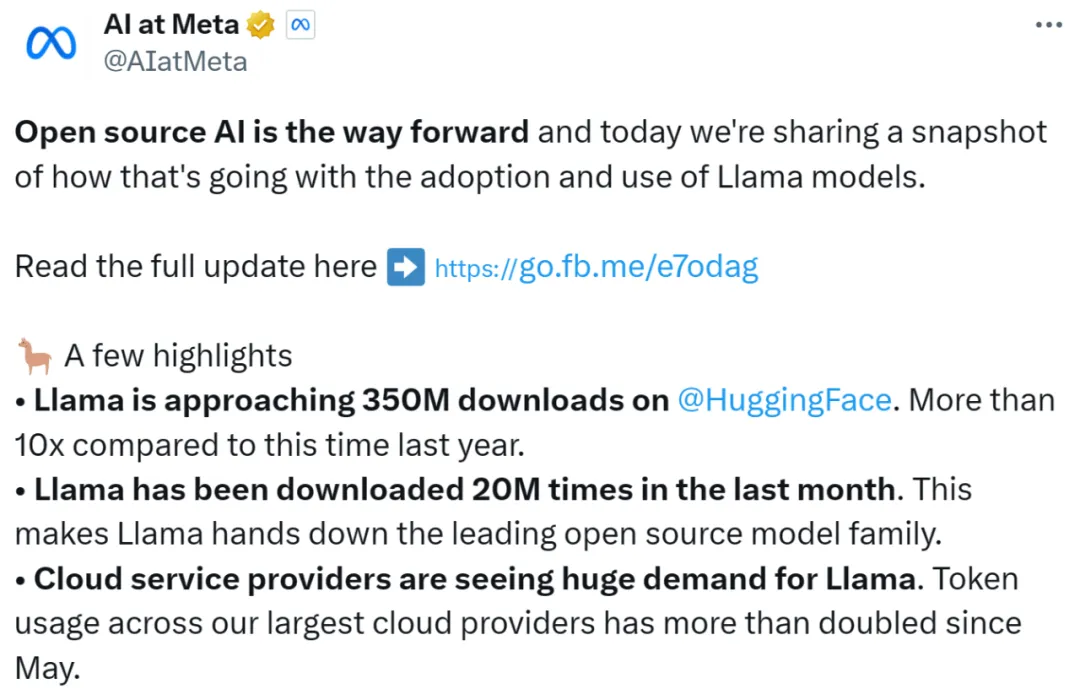
今天一大早,Meta 便秀了一把「Llama 系列模型在开源领域取得的成绩」,包括如下:
诞生一年半,Llama家族早已稳坐开源界头把交椅。最新报告称,Llama全球下载量近3.5亿,是去年同期的10倍。而模型开源让每个人最深体会是,token价格一降再降。

最近,Meta的多个工程团队联合发表了一篇论文,描述了在引入基于GPU的分布式训练时,他们如何为其「量身定制」专用的数据中心网络。

你给翻译翻译,什么是开源?

性能不输Mistral与Llama,优化多语言支持,强化合规性。

Meta的开源大模型Llama 3在市场上遇冷,进一步加剧了大模型开源与闭源之争的关注热度。
微调的所有门道,都在这里了。

随着LLM不断迭代,偏好和评估数据中大量的人工标注逐渐成为模型扩展的显著障碍之一。Meta FAIR的团队最近提出了一种使用迭代式方法「自学成才」的评估模型训练方法,让70B参数的Llama-3-Instruct模型分数超过了Llama 3.1-405B。

人自信的时候,说话都会变得坦率很多。