
70B模型秒出1000token,代码重写超越GPT-4o,来自OpenAI投资的代码神器Cursor团队
70B模型秒出1000token,代码重写超越GPT-4o,来自OpenAI投资的代码神器Cursor团队70B模型,秒出1000token,换算成字符接近4000!
来自主题: AI技术研报
10179 点击 2024-05-17 17:45
 搜索
搜索
70B模型,秒出1000token,换算成字符接近4000!
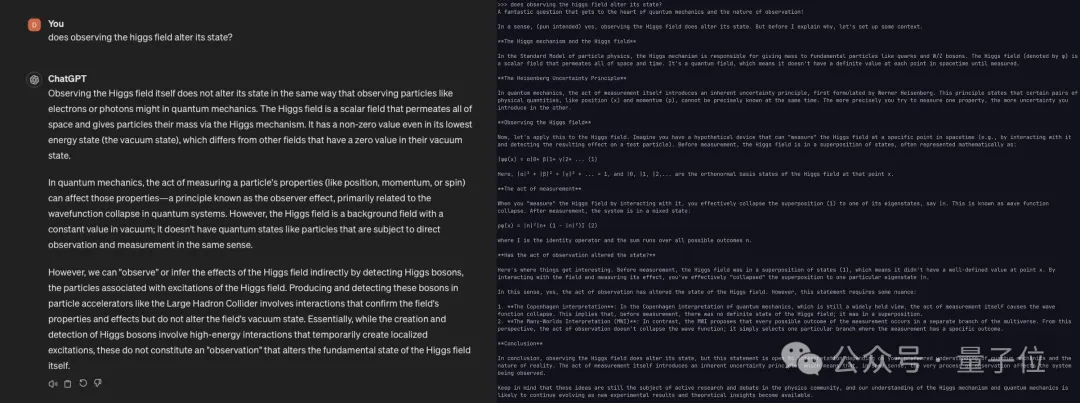
Llama 3首发阵容里没有的120B型号竟意外“曝光”,而且十分能打?!

猛然间,大模型圈掀起一股“降价风潮”。

微软&清华最新研究,打破GPT系列开创的Decoder-Only架构——

在上一篇文章「Unsloth微调Llama3-8B,提速44.35%,节省42.58%显存,最少仅需7.75GB显存」中,我们介绍了Unsloth,这是一个大模型训练加速和显存高效的训练框架,我们已将其整合到Firefly训练框架中,并且对Llama3-8B的训练进行了测试,Unsloth可大幅提升训练速度和减少显存占用。

两周前,OpenBMB开源社区联合面壁智能发布领先的开源大模型「Eurux-8x22B 」。相比口碑之作 Llama3-70B,Eurux-8x22B 发布时间更早,综合性能相当,尤其是拥有更强的推理性能——刷新开源大模型推理性能 SOTA,堪称开源大模型中「理科状元」。
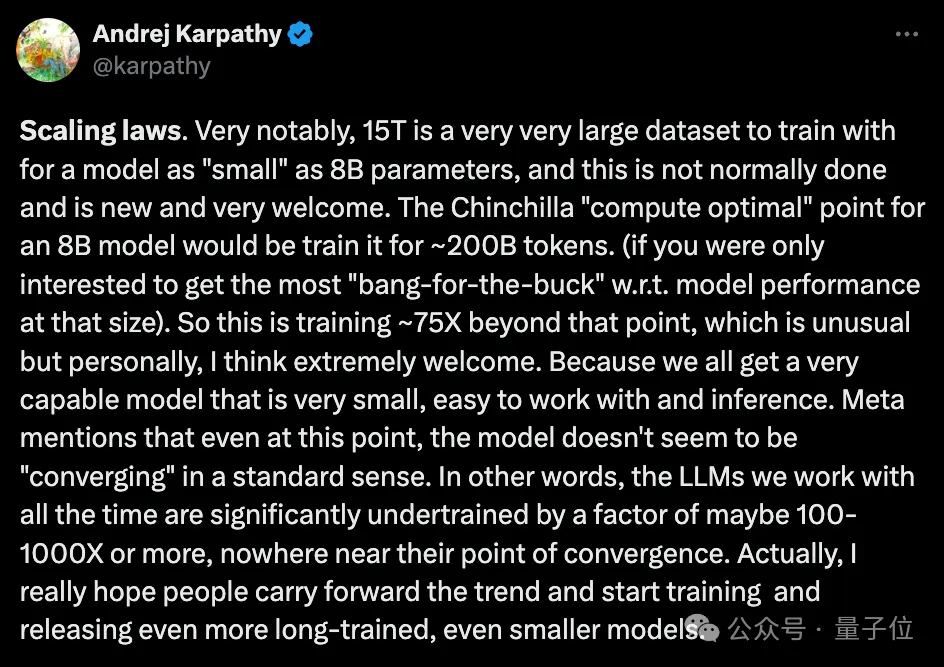
大模型力大砖飞,让LLaMA3演绎出了新高度: 超15T Token数据上的超大规模预训练,既实现了令人印象深刻的性能提升,也因远超Chinchilla推荐量再次引爆开源社区讨论。
Snowflake 发布高「企业智能」模型 Arctic,专注于企业内部应用。
最近,Meta 推出了 Llama 3,为开源大模型树立了新的标杆。
羊驼家族的“最强开源代码模型”,迎来了它的“超大杯”——就在今天凌晨,Meta宣布推出Code Llama的70B版本。