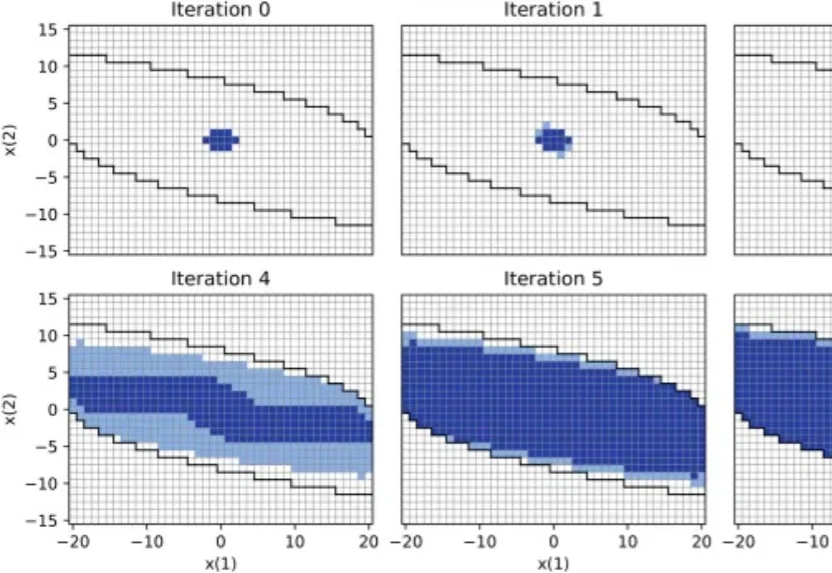
真机强化学习如何保证安全性?清华团队提出安全探索均衡机制
真机强化学习如何保证安全性?清华团队提出安全探索均衡机制近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。
来自主题: AI技术研报
6728 点击 2026-06-24 16:03
 搜索
搜索
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。

最近,前沿实验室 Mind Lab 密集发布了一系列关于 LoRA 与 PEFT(高效微调)的研究结果,似乎描绘出了另一条大模型「持续学习」的路径。在 Mind Lab 的视角中,PEFT 不再是对大模型全参数后训练的一种廉价平替,更是实现从 “基础模型” 向 “可持续学习智能体” 过渡的核心架构机制。

Mindverse 完成由美团领投的 A 轮融资,元禾璞华、韶音、变量资本和老股东追加跟投。Mindverse (心洲科技) 是少数把赌注押在模型「内部」的一家创企,它在通用大模型的基础上,用强化学习让它从复杂、多步骤的真实任务中学会如何把事做成,让模型从「知道很多」变为「能办好事」。
Flora——这款被阿里巴巴、Brex、创意机构五角设计联盟以及娱乐公司狮门影业的设计师广泛使用的设计工具,近日达成了一项新里程碑。这家初创公司于周二宣布,已获得由红点创投领投的 4200 万美元 A 轮融资。

热门LoRA首次内置,控光换镜头实测可用。

视频生成模型总是「记性不好」?生成几秒钟后物体就变形、背景就穿帮?北大、中大等机构联合发布EgoLCD,借鉴人类「长短时记忆」机制,首创稀疏KV缓存+LoRA动态适应架构,彻底解决长视频「内容漂移」难题,在EgoVid-5M基准上刷新SOTA!让AI像人一样拥有连贯的第一人称视角记忆。
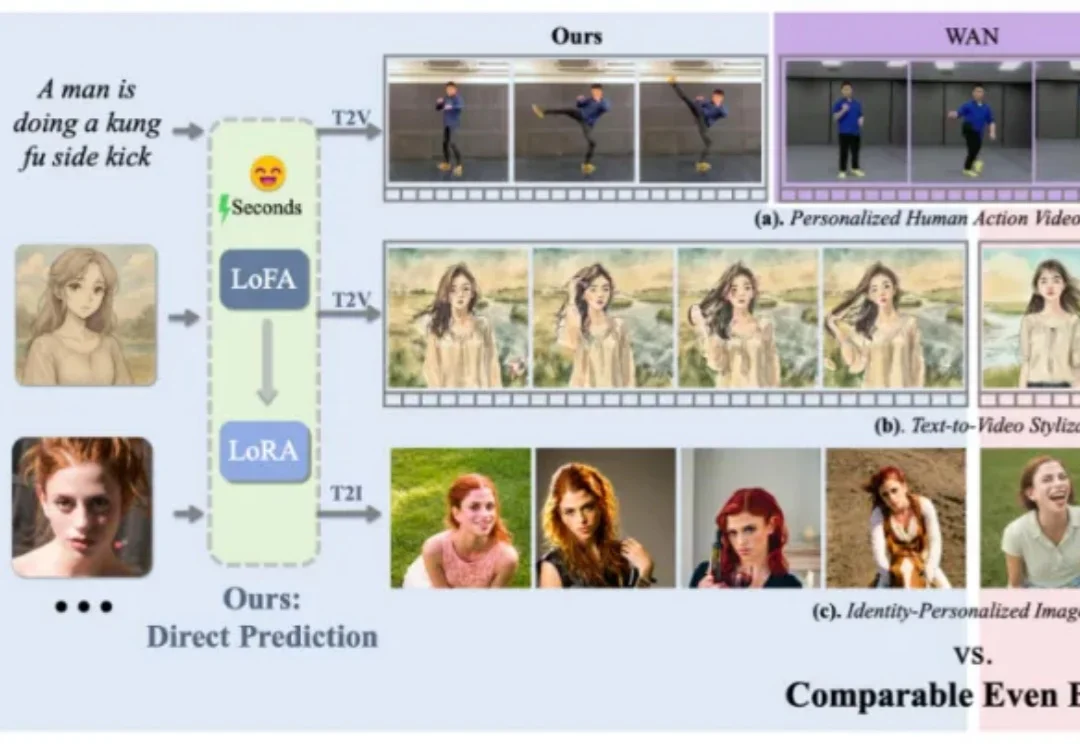
在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。

2 天前,国内最大的 AI 多模态模型社区之一的 LiblibAI 进行了一次大升级,正式推出了 2.0 版本。对许多创作者而言,这个平台并不陌生,LiblibAI 一直是国内开源绘画与 LoRA 文化的重要发源地,也常被称为中国版的 CivitAI (大家常说的 C 站)。
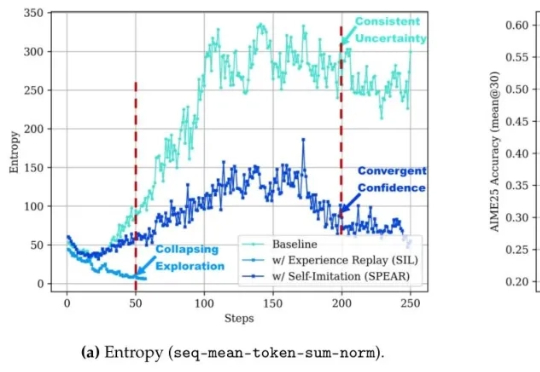
让智能体自己摸索新方法,还模仿自己的成功经验。腾讯优图实验室开源强化学习算法——SPEAR(Self-imitation with Progressive Exploration for Agentic Reinforcement Learning)。

LoRA能否与全参微调性能相当?在Thinking Machines的最新论文中,他们研究了LoRA与FullFT达到相近表现的条件。Thinking Machines关注LoRA,旨在推动其更广泛地应用于各种按需定制的场景,同时也有助于我们更深入审视机器学习中的一些基本问题。