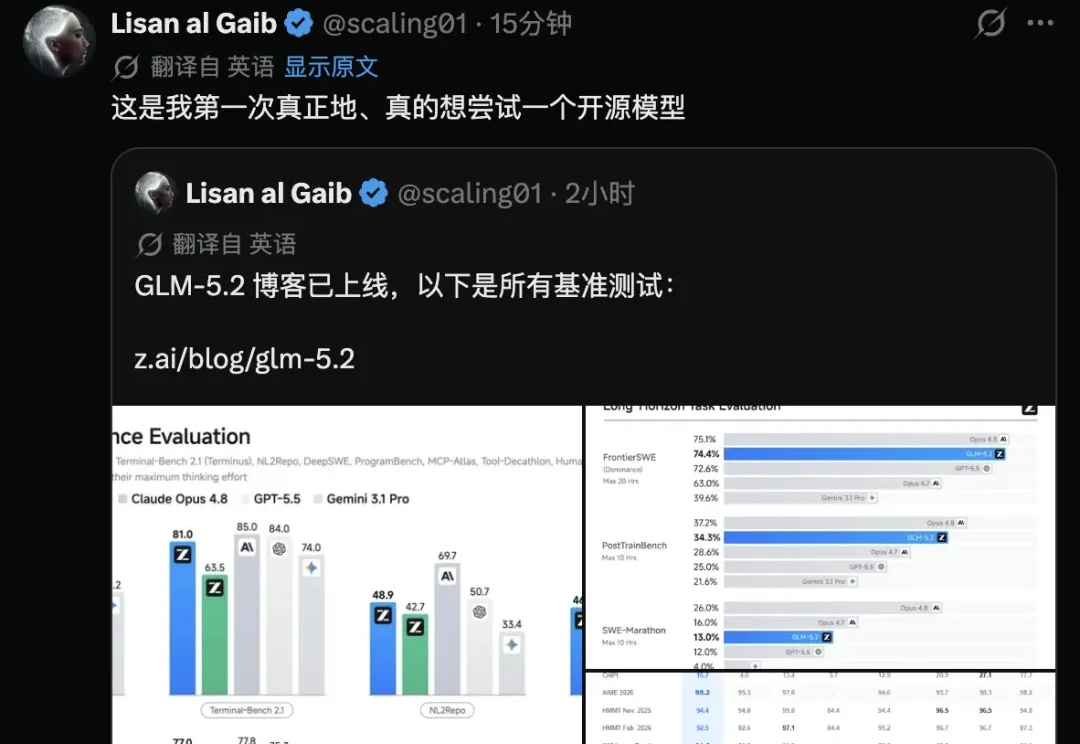
GLM-5.2 正式发布:开源之王来了,摸到了Opus-4.8
GLM-5.2 正式发布:开源之王来了,摸到了Opus-4.8GLM-5.2 正式发布,震撼全网,主打长程任务能力,配合 1M token 上下文窗口,且完全开源(MIT 协议)。在相近的 token 消耗下,GLM-5.2 的能力大致介于 Opus 4.7 和 Opus 4.8 之间,参数仅为753B。
来自主题: AI资讯
9750 点击 2026-06-17 10:50
 搜索
搜索
GLM-5.2 正式发布,震撼全网,主打长程任务能力,配合 1M token 上下文窗口,且完全开源(MIT 协议)。在相近的 token 消耗下,GLM-5.2 的能力大致介于 Opus 4.7 和 Opus 4.8 之间,参数仅为753B。

一颗土豆,表皮上爬满发光电路,焦黄的皮和银色走线贴在一起,像是英伟达和肯德基联名了。 标题端端正正:Potato Chip Tech Summit——一颗土豆如何颠覆半导体行业。 这是我们给 AI 出

当对话型 AI 服务于数十亿用户时,我们能否看见用户没说出口的那一层?JHU、MIT 和 Google Research 给出了新的解法。
初创公司Axiom Math宣布,他们从2026年2月开始提交的8篇论文,到5月28日有5篇已经通过同行评审,登上学术期刊。创始人洪乐潼,2001年出生于广州,本科MIT三年拿下数学与物理双学位,还拿过北美数学本科生的最高荣誉罗德奖学金和摩根奖。
就在今天,美团龙猫大模型团队突然开源了商用级数字人视频生成模型 LongCat-Video-Avatar 1.5。在权威评测中,它的用户偏好胜率全面超越 Kling Avatar 2.0、OmniHuman-1.5 和 HeyGen 这三个头部玩家,并且直接以 MIT 协议开放,连商用限制都懒得设。

AI shopping 的热度正在升温。

一个懂审美、更懂你的“AI闺蜜”。
「我即将离开麻省理工学院,不再继续攻读博士学位。人工智能的发展速度太快,人类已然难以跟上。

由张昊天作为一作兼共同通讯作者在临港实验室联合上海浦江实验室、华盛顿大学、哈佛大学、MIT 等科研力量共同推进的 ODesign 开源科研项目,定位于全球首个面向全模态的分子设计基座模型。
刚刚,小米开源罗福莉带队研发的MiMo-V2.5系列模型,采用MIT协议,允许商用推理部署与二次训练,无需额外授权。此前,该系列模型于4月23日开启公测,包括MiMo-V2.5-Pro、MiMo-V2.5两款模型。模型具备更强Agent能力,支持100万上下文,且Token效率大幅提升。