5050亿参数!余承东开源盘古新模型openPangu-2.0-Pro,距离“世界第一”还有差距
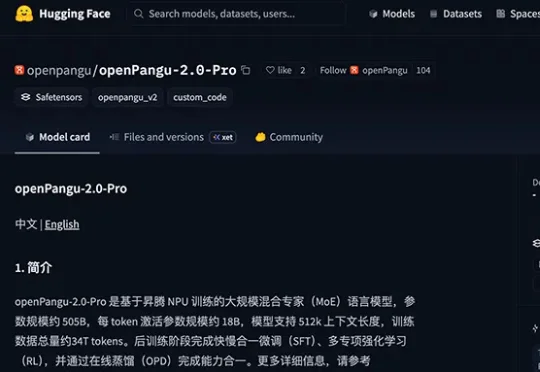
5050亿参数!余承东开源盘古新模型openPangu-2.0-Pro,距离“世界第一”还有差距今日,华为开源基于昇腾NPU训练的盘古MoE模型openPangu-2.0-Pro。该模型是openPangu-2.0系列的最新开源模型,总参数规模5050亿,激活参数规模180亿,支持512K上下文长度,训练数据总量约34T tokens。另一轻量化模型openPangu-2.0-Flash已于6月12日开源,参数92亿,其中6亿为激活参数。
来自主题: AI资讯
8793 点击 2026-07-31 21:54